welcome
Hello World
Open Source
1.
vllm
2.
sglang
3.
pytorch
❱
3.1.
torchrun
3.2.
tensor
3.3.
autograd
3.4.
operator
3.5.
profiler
3.6.
hook
3.7.
elastic
3.8.
patch
3.9.
misc
4.
paddlepaddle
❱
4.1.
ps
4.2.
framework
4.3.
cinn
4.4.
dataloader
5.
horovod
❱
5.1.
run
5.2.
workflow
5.3.
object
5.4.
develop
5.5.
pytorch
5.6.
tensorflow
5.7.
elastic
6.
ray
❱
6.1.
overview
6.2.
gcs
6.3.
raylet
6.4.
api
6.5.
survey
7.
llama
8.
nccl
9.
megatron
10.
deepspeed
11.
nanochat
Survey
12.
survey
❱
12.1.
pollux
12.2.
adasum
12.3.
adaptation_learning
12.4.
gradient_descent
12.5.
auto_parallel
12.6.
scheduling
12.7.
gradient_compression
❱
12.7.1.
dgc
12.7.2.
csc
12.8.
flash attention
12.9.
LoRA
13.
models
❱
13.1.
llm
13.2.
falcon
13.3.
llama
13.4.
peft
13.5.
transformer
13.6.
models
Programming
14.
python
❱
14.1.
concurrent execution
14.2.
multiprocessing
14.3.
decorator
15.
golang
❱
15.1.
golang error
16.
cplusplus
❱
16.1.
enable_shared_from_this
Mathematics
17.
mathematics
❱
17.1.
basic
17.2.
entropy
17.3.
newton
17.4.
regression
17.5.
conjugate descent
17.6.
gradient descent
17.7.
pca
17.8.
support vector
17.9.
differentiation
17.10.
fourier
17.11.
kmeans
18.
wavelets
❱
18.1.
plan
18.2.
preliminary
18.3.
haar wavelet
18.4.
fourier analysis
18.5.
uncertainty principle
18.6.
multiresolution
Learning Deep
19.
kubernetes
❱
19.1.
concepts
19.2.
scheduler
19.3.
operator
19.4.
device plugin
19.5.
docker
19.6.
install
19.7.
api-service
19.8.
controller
20.
cuda
❱
20.1.
101
21.
todo
❱
21.1.
gloo
21.2.
mpi
21.3.
jax
21.4.
tvm
21.5.
llm
22.
notes
❱
22.1.
influence and persuasion
22.2.
freynman technique
22.3.
wavelet signal processing
23.
tips
❱
23.1.
ip_local_port_range
24.
infrastructure
❱
24.1.
pki
24.2.
linux cache
25.
projects
❱
25.1.
copilot
25.2.
library
25.3.
RAG
26.
chronicles
❱
26.1.
feb 2024
Light
Rust
Coal
Navy
Ayu
Aller au boulot
Scaling distributed training with adaptive summation
Saeed Maleki et al. Microsoft Research
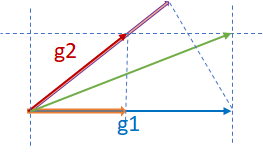
Key point
g
=
(
1
−
2
∣
g
1
∣
2
g
1
⋅
g
2
)
g
1
+
(
1
−
2
∣
g
2
∣
2
g
1
⋅
g
2
)
g
2
Reference
AdaSum with Horovod
Arxiv