Aller au boulot!
Welcome to my notes space, I really appreciate if you find something helpful here.
Host on excel.kuizhiqing.cn.
vllm architecture
Entrypoint
online serving
TL;DR;
- 使用 vllm serve 命令启动 FastAPI/HTTP 模型服务,支持 OpenAI 协议访问;
- 本质上创建了 AsyncLLMEngine,当访问
/v1/chat/completions接口时,会调用engine.generate方法;
使用命令
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
可以在本地启动一个基于 DeepSeek-R1-Distill-Qwen-7B 的模型服务。
服务的默认端口是 8000,采用 OpenAI 的协议 格式,可以使用 http 或 openai sdk 等方式访问。
curl 访问
curl https://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
openai SDK 访问
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1",
)
chat_completion = client.chat.completions.create(
messages=[{
"role": "system",
"content": "You are a helpful assistant."
}, {
"role": "user",
"content": "Hello!"
}],
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
)
print("Chat completion results:")
print(chat_completion)
entrypoint
vllm 命令在安装 vllm 时被安装,在 pyproject.toml 中定义
[project.scripts]
vllm = "vllm.entrypoints.cli.main:main"
入口
vllm/entrypoints/cli/main.py
dispatch 到真实启动的入口
vllm.entrypoints.cli.serve.
# vllm/entrypoints/cli/serve.py
class ServeSubcommand(CLISubcommand):
def __init__(self):
self.name = "serve"
@staticmethod
def cmd(args: argparse.Namespace) -> None:
args.model = args.model_tag
uvloop.run(run_server(args))
def subparser_init(self, subparsers):
serve_parser = subparsers.add_parser("serve", usage="vllm serve <model_tag> [options]")
serve_parser.add_argument("model_tag", ...)
serve_parser.add_argument("--config", ...) # YAML config file
return make_arg_parser(serve_parser)
可以看到,serve 命令的入口是 vllm.entrypoints.cli.serve.ServeSubcommand.cmd,它调用 vllm.entrypoints.cli.serve.run_server,而 run_server 会创建 uvicorn 服务。
# vllm/entrypoints/openai/api_server.py
@asynccontextmanager
async def build_async_engine_client(args) -> AsyncIterator[EngineClient]:
engine_args = AsyncEngineArgs.from_cli_args(args)
engine_client = AsyncLLMEngine.from_engine_args(engine_args, ...)
yield engine_client
def build_app(args: Namespace) -> FastAPI:
app = FastAPI(lifespan=lifespan)
app.include_router(router)
return app
async def run_server(args, **uvicorn_kwargs) -> None:
async with build_async_engine_client(args) as engine_client:
app = build_app(args)
model_config = await engine_client.get_model_config()
await init_app_state(engine_client, model_config, app.state, args)
await serve_http(app, ... **uvicorn_kwargs)
if __name__ == "__main__":
parser = FlexibleArgumentParser(...)
args = parser.parse_args()
uvloop.run(run_server(args))
run_server 是个异步函数,它完成了 2 个主要任务:
- 创建异步 engine :
AsyncLLMEngine - 创建 FastAPI 应用,承接 http 请求
这里通过 init_app_state 初始化了 app.state,即把 vllm LLMEngine 设置给了 FastAPI。
其中 serve_http 通过 uvicorn 实现了 http 服务的启动。
# vllm/entrypoints/launcher.py
async def serve_http(app: FastAPI, sock: Optional[socket.socket], **uvicorn_kwargs: Any):
config = uvicorn.Config(app, **uvicorn_kwargs)
server = uvicorn.Server(config)
loop = asyncio.get_running_loop()
server_task = loop.create_task(
server.serve(sockets=[sock] if sock else None))
同时可以看到 vllm serve 的等价启动方式是
python3 -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
请求链路
# vllm/entrypoints/openai/api_server.py
router = APIRouter()
@router.post("/v1/chat/completions")
async def create_chat_completion(request: ChatCompletionRequest, raw_request: Request):
handler = chat(raw_request)
generator = await handler.create_chat_completion(request, raw_request)
if isinstance(generator, ChatCompletionResponse):
return JSONResponse(content=generator.model_dump())
return StreamingResponse(content=generator, media_type="text/event-stream")
def chat(request: Request) -> Optional[OpenAIServingChat]:
return request.app.state.openai_serving_chat
async def init_app_state(engine_client, model_config, state, args):
state.openai_serving_chat = OpenAIServingChat(
engine_client, model_config, state.openai_serving_models, ...
)
请求 /v1/chat/completions 接口时,会调用 OpenAIServingChat 的 create_chat_completion 方法。
# vllm/entrypoints/openai/serving_chat.py
class OpenAIServingChat(OpenAIServing):
async def create_chat_completion(self, ChatCompletionRequest, Request):
tokenizer = await self.engine_client.get_tokenizer(lora_request)
(conversation, request_prompts, engine_prompts) =
await self._preprocess_chat(request, tokenizer, request.messages, ...)
for i, engine_prompt in enumerate(engine_prompts):
sampling_params = request.to_sampling_params(...)
generator = self.engine_client.generate(engine_prompt, sampling_params, request_id,)
generators.append(generator)
result_generator, = generators
return await self.chat_completion_full_generator( # chat_completion_stream_generator
request, result_generator, request_id, model_name,
conversation, tokenizer, request_metadata)
async def chat_completion_full_generator(self, request, result_generator, ...):
async for res in result_generator:
final_res = res
role = self.get_chat_request_role(request)
for output in final_res.outputs:
logprobs = self._create_chat_logprobs(...)
message = ChatMessage(role=role, content=output.text)
choice_data = ChatCompletionResponseChoice(
index=output.index,
message=message,
logprobs=logprobs, ...)
choices.append(choice_data)
response = ChatCompletionResponse(
choices=choices,
prompt_logprobs=final_res.prompt_logprobs,
)
return response
可以看到 create_chat_completion 的主要逻辑是调用 engine 的 generate 方法,生成结果,
prompt 由 OpenAIServing._preprocess_chat 进行预处理,包括 template 化和 tokenization。
# vllm/entrypoints/openai/serving_engine.py
class OpenAIServing:
async def _preprocess_chat(...):
conversation, mm_data_future = parse_chat_messages_futures(...)
request_prompt = apply_hf_chat_template(tokenizer, conversation=conversation,)
prompt_inputs = await self._tokenize_prompt_input_async(request, tokenizer, request_prompt,)
engine_prompt = TokensPrompt(prompt_token_ids=prompt_inputs["prompt_token_ids"])
return conversation, [request_prompt], [engine_prompt]
注意 request_prompt -> prompt_inputs -> engine_prompt 的过程,engine_prompt 中包含了完整 prompt 信息。
函数 generate 调用的 3 个参数
- prompt : 未 tokenized 的格式化输入;
- sampling_params : 采样参数,包括 temperature, top_p, top_k 等;
- request_id : 请求 id,用于区分不同请求。
注意到
- 生成的文本位于
response.choices.message.content中。 - generate 返回的 generator 中的
output.text是已经经过 tokenizer decode 的。
根据是否 stream 请求,调用 chat_completion_stream_generator 和 chat_completion_full_generator 返回不同的结果。
推理实现的核心逻辑 engine.generate 将在 Engine 部分分析。
offline inference
与 serving 模式不同,离线推理模式直接在程序内加载模型通过函数调用的方式得到推理结果。
demo
from vllm import LLM
prompts = "Hello, my name is"
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts)
for output in outputs:
generated_text = output.outputs[0].text
从 demo 中可以看出流程为使用 LLM 类,调用 generate 方法,得到结果。
# vllm/__init__.py
from vllm.entrypoints.llm import LLM
与在线不同,离线使用的 LLM 类是对应的是同步 LLMEngine, 也即在线 serving 通常使用异步模式,离线 inference 模式通常使用同步模式。
# vllm/entrypoints/llm.py
class LLM:
def __init__(self, model, ...) -> None:
worker_cls = kwargs["worker_cls"]
engine_args = EngineArgs(model, task, tokenizer)
self.engine_class = self.get_engine_class()
self.llm_engine = self.engine_class.from_engine_args(
engine_args, usage_context=UsageContext.LLM_CLASS)
@staticmethod
def get_engine_class() -> Type[LLMEngine]:
if envs.VLLM_USE_V1:
from vllm.v1.engine.llm_engine import LLMEngine as V1LLMEngine
return V1LLMEngine
return LLMEngine
@overload
def generate(self, prompts, sampling_params):
self._validate_and_add_requests(prompts=parsed_prompts, params=sampling_params,...)
outputs = self._run_engine(use_tqdm=use_tqdm)
return self.engine_class.validate_outputs(outputs, RequestOutput)
def _validate_and_add_requests(self, prompts, ...):
for i, prompt in enumerate(prompts):
self._add_request(prompt, ...)
def _add_request(self, prompt, ...):
self.llm_engine.add_request( request_id, prompt, params, ...)
def _run_engine(self, *, use_tqdm: bool) -> List[Union[RequestOutput, PoolingRequestOutput]]:
while self.llm_engine.has_unfinished_requests():
step_outputs = self.llm_engine.step()
for output in step_outputs:
if output.finished:
outputs.append(output)
return sorted(outputs, key=lambda x: int(x.request_id))
总结 LLM 的流程为,
- 初始化时创建
LLMEngine实例; - 调用
generate时首先调用engine.add_request方法添加请求; - 再调用
engine.step方法执行请求,获取推理结果;
具体如何获取推理结果,需要看 LLMEngine 的实现。
AsyncLLMEngine
V1 版本的 AsyncLLMEngine 定义于 vllm.v1.engine.async_llm 的 AsyncLLM
# vllm/engine/async_llm_engine.py
if envs.VLLM_USE_V1:
from vllm.v1.engine.async_llm import AsyncLLM
AsyncLLMEngine = AsyncLLM
AsyncLLM 定义一个异步的 LLM,其关键代码如下,
# vllm/v1/engine/async_llm.py
class AsyncLLM(EngineClient):
def __init__(self, vllm_config, executor_class):
# Tokenizer (+ ensure liveness if running in another process).
self.tokenizer = init_tokenizer_from_configs(...)
self.tokenizer.ping()
# Processor (converts Inputs --> EngineCoreRequests).
self.processor = Processor(..., tokenizer...)
# OutputProcessor (converts EngineCoreOutputs --> RequestOutput).
self.output_processor = OutputProcessor(self.tokenizer, ...)
# EngineCore (starts the engine in background process).
self.engine_core = EngineCoreClient.make_client(..., vllm_config, executor_class, ...)
self.output_handler: Optional[asyncio.Task] = None
@classmethod
def from_engine_args(cls, ...) -> "AsyncLLM":
executor_class = Executor.get_class(vllm_config)
return cls(vllm_config, executor_class, ...)
async def generate(self, prompt, sampling_params, ...) -> AsyncGenerator[RequestOutput, None]:
self.output_handler = asyncio.create_task(self._run_output_handler())
q = await self.add_request(request_id, prompt, sampling_params, ...)
while not finished:
out = q.get_nowait() if not q.empty() else await q.get()
yield out
async def _run_output_handler(self):
"""Background loop: pulls from EngineCore and pushes to AsyncStreams."""
while True:
# 1) Pull EngineCoreOutputs from the EngineCore.
outputs = await self.engine_core.get_output_async()
slices = (outputs.outputs, )
for i, outputs_slice in enumerate(slices):
# 2) Process EngineCoreOutputs.
processed_outputs = self.output_processor.process_outputs(
outputs_slice, outputs.timestamp, iteration_stats)
# 3) Abort any reqs that finished due to stop strings.
await self.engine_core.abort_requests_async(
processed_outputs.reqs_to_abort)
async def add_request(self, request_id, prompt, params, ...) -> asyncio.Queue[RequestOutput]:
# 1) Create a new output queue for the request.
queue: asyncio.Queue[RequestOutput] = asyncio.Queue()
# 2) Convert Input --> Request.
request = self.processor.process_inputs(request_id, prompt, params, ...)
# 3) Add the request to OutputProcessor (this process).
self.output_processor.add_request(request, queue)
# 4) Add the EngineCoreRequest to EngineCore (separate process).
await self.engine_core.add_request_async(request)
return queue
父类
EngineClient本质是 Engine interface.
AsyncLLM (V1 版本的 AsyncLLMEngine) 是一个异步的 LLM,系统的核心组件,它的初始化过程启动了主要组件:
- EngineCoreClient + Executor
- Processor + Tokenizer
- OutputProcessor + Tokenizer
分析 generate() 调用流程
异步处理 output : _run_output_handler
outputs = engine_core.get_output_async()
output_processor.process_outputs(outputs)
engine_core.abort_requests_async()
异步处理 input : add_request
request = processor.process_inputs(...)
output_processor.add_request(request, queue)
engine_core.add_request_async(request)
generate() 返回的是 AsyncGenerator,调用者需要迭代获得 RequestOutput,如
OpenAIServingChat.create_chat_completion中的实现
其中包括 3 个对象及其调用
processor调用process_inputsoutput_processor调用add_request和process_outputsengine_core调用get_output_async,add_request_async和abort_requests_async
下面依次分析这些对象。
EngineCore
首先来看 engine_core,主要关注以下 3 个方法
engine_core.get_output_async()
engine_core.abort_requests_async()
engine_core.add_request_async()
EngineCoreClient
AsyncLLM.engine_core 由 EngineCoreClient.make_client 创建,根据不同配置返回不同实现.
# vllm/v1/engine/core_client.py
class EngineCoreClient(ABC):
@staticmethod
def make_client(..., vllm_config, executor_class, ...) -> "EngineCoreClient":
if multiprocess_mode and asyncio_mode:
return AsyncMPClient(vllm_config, executor_class, log_stats)
if multiprocess_mode and not asyncio_mode:
return SyncMPClient(vllm_config, executor_class, log_stats)
return InprocClient(vllm_config, executor_class, log_stats)
class InprocClient(EngineCoreClient):
def __init__(self, *args, **kwargs):
self.engine_core = EngineCore(*args, **kwargs)
def get_output(self) -> EngineCoreOutputs:
return self.engine_core.step()
def add_request(self, request: EngineCoreRequest) -> None:
self.engine_core.add_request(request)
def abort_requests(self, request_ids: List[str]) -> None:
if len(request_ids) > 0:
self.engine_core.abort_requests(request_ids)
EngineCoreClient 的第一种实现把 EngineCore 作为成员实例化,主要在 v0 版本中采用
- InprocClient: In process EngineCore (for V0-style LLMEngine use)
V1 版本通过 MPClient 实现了 sync 和 async 两个版本,
- SyncMPClient: ZMQ + background proc EngineCore (for LLM)
- AsyncMPClient: ZMQ + background proc EngineCore w/ asyncio (for AsyncLLM)
# vllm/v1/engine/core_client.py
class MPClient(EngineCoreClient):
def __init__(..., vllm_config, executor_class, ...):
self.ctx = zmq.asyncio.Context()
self.output_socket = make_zmq_socket(self.ctx, output_path, zmq.constants.PULL)
self.input_socket = make_zmq_socket(self.ctx, input_path, zmq.constants.PUSH)
self.proc_handle = BackgroundProcHandle(
input_path=input_path,
output_path=output_path,
target_fn=EngineCoreProc.run_engine_core,
process_kwargs={"vllm_config": vllm_config, "executor_class": executor_class, })
class SyncMPClient(MPClient):
def __init__(self, vllm_config, executor_class, ...):
self.outputs_queue = queue.Queue()
def process_outputs_socket():
while True:
(frame, ) = output_socket.recv_multipart(copy=False)
outputs = decoder.decode(frame.buffer)
outputs_queue.put_nowait(outputs)
Thread(target=process_outputs_socket, daemon=True).start()
def get_output(self) -> EngineCoreOutputs:
return self.outputs_queue.get()
def _send_input(self, request_type, request) -> None:
msg = (request_type.value, self.encoder.encode(request))
self.input_socket.send_multipart(msg, copy=False)
def add_request(self, request: EngineCoreRequest) -> None:
self._send_input(EngineCoreRequestType.ADD, request)
def abort_requests(self, request_ids: List[str]) -> None:
self._send_input(EngineCoreRequestType.ABORT, request_ids)
class AsyncMPClient(MPClient):
async def _start_output_queue_task(self):
self.outputs_queue = asyncio.Queue()
async def process_outputs_socket():
while True:
(frame, ) = await output_socket.recv_multipart(copy=False)
outputs: EngineCoreOutputs = decoder.decode(frame.buffer)
outputs_queue.put_nowait(outputs)
self.queue_task = asyncio.create_task(process_outputs_socket())
async def get_output_async(self) -> EngineCoreOutputs:
await self._start_output_queue_task()
return await self.outputs_queue.get()
async def _send_input(request_type, request):
msg = (request_type.value, self.encoder.encode(request))
await self.input_socket.send_multipart(msg, copy=False)
async def add_request_async(self, request: EngineCoreRequest) -> None:
await self._send_input(EngineCoreRequestType.ADD, request)
async def abort_requests_async(self, request_ids: List[str]) -> None:
await self._send_input(EngineCoreRequestType.ABORT, request_ids)
SyncMPClient/AsyncMPClient 的实现基本一致,
add_request/add_request_async通过 input_socket 向 mq 中发送消息;process_outputs_socket中 while 循环从 output_socket 中获取消息,decode 后放入 outputs_queue 中;get_output/get_output_async从 outputs_queue 中返回消息;
process_outputs_socket 在 sync 版本中使用线程实现,async 版本中使用协程实现。
EngineCore
核心逻辑 EngineCoreProc.run_engine_core 则由 BackgroundProcHandle 启动子进程实现。
# vllm/v1/utils.py
class BackgroundProcHandle:
def __init__( self, input_path, output_path, process_name, target_fn: Callable, process_kwargs):
context = get_mp_context()
reader, writer = context.Pipe(duplex=False)
self.proc = context.Process(target=target_fn, kwargs=process_kwargs)
self.proc.start()
# vllm/v1/engine/core.py
class EngineCore:
def __init__(self, vllm_config, executor_class):
self.model_executor = executor_class(vllm_config)
num_gpu_blocks, num_cpu_blocks = self._initialize_kv_caches(vllm_config)
self.scheduler = Scheduler(scheduler_config, model_config, cache_config, ...)
self.batch_queue_size = self.model_executor.max_concurrent_batches
if self.batch_queue_size > 1:
self.batch_queue = queue.Queue(self.batch_queue_size)
def _initialize_kv_caches(self, vllm_config: VllmConfig) -> Tuple[int, int]:
self.model_executor.initialize(kv_cache_configs)
return num_gpu_blocks, num_cpu_blocks
def add_request(self, request: EngineCoreRequest):
req = Request.from_engine_core_request(request)
self.scheduler.add_request(req)
def abort_requests(self, request_ids: List[str]):
self.scheduler.finish_requests(request_ids, RequestStatus.FINISHED_ABORTED)
def step(self) -> EngineCoreOutputs:
scheduler_output = self.scheduler.schedule()
output = self.model_executor.execute_model(scheduler_output)
engine_core_outputs = self.scheduler.update_from_output(scheduler_output, output)
return engine_core_outputs
def step_with_batch_queue(self) -> Optional[EngineCoreOutputs]:
scheduler_output = self.scheduler.schedule()
future = self.model_executor.execute_model(scheduler_output)
self.batch_queue.put_nowait( (future, scheduler_output))
future, scheduler_output = self.batch_queue.get(timeout=POLLING_TIMEOUT_S)
model_output = future.result()
self.batch_queue.task_done()
engine_core_outputs = self.scheduler.update_from_output(scheduler_output, model_output)
return engine_core_outputs
class EngineCoreProc(EngineCore):
def __init__(self, ...):
self.input_queue: queue.Queue[Tuple[EngineCoreRequestType, Any]] = queue.Queue()
self.output_queue: queue.Queue[EngineCoreOutputs] = queue.Queue()
threading.Thread(target=self.process_input_socket, args=(input_path, ), daemon=True).start()
threading.Thread(target=self.process_output_socket, args=(output_path, ), daemon=True).start()
ready_pipe.send({"status": "READY"})
@staticmethod
def run_engine_core(*args, **kwargs):
engine_core = EngineCoreProc(*args, **kwargs)
engine_core.run_busy_loop()
def run_busy_loop(self):
step_fn = (self.step if self.batch_queue is None else self.step_with_batch_queue)
while True:
req = self.input_queue.get_nowait()
self._handle_client_request(*req)
outputs = step_fn()
self.output_queue.put_nowait(outputs)
def _handle_client_request(self, request_type: EngineCoreRequestType, request: Any) -> None:
if request_type == EngineCoreRequestType.ADD:
self.add_request(request)
elif request_type == EngineCoreRequestType.ABORT:
self.abort_requests(request)
def process_input_socket(self, input_path: str):
with zmq_socket_ctx(input_path, zmq.constants.PULL) as socket:
while True:
type_frame, data_frame = socket.recv_multipart(copy=False)
request_type = EngineCoreRequestType(bytes(type_frame.buffer))
request = decoder.decode(data_frame.buffer)
self.input_queue.put_nowait((request_type, request))
def process_output_socket(self, output_path: str):
with zmq_socket_ctx(output_path, zmq.constants.PUSH) as socket:
while True:
outputs = self.output_queue.get()
encoder.encode_into(outputs, buffer)
socket.send_multipart((buffer, ), copy=False)
run_engine_core 调用 run_busy_loop,启动 while 循环,
- 从
input_queue中获取请求 EngineCoreRequest; - 调用 _handle_client_request 和 step_fn 处理请求;
- 将结果 EngineCoreOutputs 发送到 output_queue 中;
其中,
- _handle_client_request 调用
scheduler.add_request放入新请求; - step 处理请求:
- 调用
scheduler.schedule获取调度结果; - 调用
executor.execute_model处理请求(调度结果); - 调用
scheduler.update_from_output获取处理结果;
- 调用
下面依次分析 scheduler 和 executor 的实现。
Scheduler
Scheduler 作为 EngineCore 成员被初始化,关注以下调用:
scheduler.add_request()
scheduler.schedule()
scheduler.update_from_output()
分析 Scheduler 之前先看下 Request 记录的信息, 可以把它看作 dataclass,其中还包含一些处理过程中的动态信息。
# vllm/v1/request.py
class Request:
def __init__(self, request_id, prompt, prompt_token_ids, ...):
self.prompt = prompt
self.prompt_token_ids = prompt_token_ids
self.num_prompt_tokens = len(self.prompt_token_ids)
self._output_token_ids: List[int] = []
self._all_token_ids: List[int] = self.prompt_token_ids.copy()
self.spec_token_ids: List[int] = []
self.num_computed_tokens = 0
@property
def num_tokens(self) -> int:
return len(self._all_token_ids)
@property
def num_tokens_with_spec(self) -> int:
return len(self._all_token_ids) + len(self.spec_token_ids)
def append_output_token_ids(self, token_ids) -> None:
self._output_token_ids.extend(token_ids)
self._all_token_ids.extend(token_ids)
# vllm/v1/core/scheduler.py
class Scheduler:
def __init__(self, scheduler_config, model_config, cache_config, ...):
self.kv_cache_manager = KVCacheManager()
self.requests: Dict[str, Request] = {} # req_id -> Request
self.waiting: Deque[Request] = deque()
self.running: List[Request] = []
self.finished_req_ids: Set[str] = set()
def add_request(self, request: Request) -> None:
self.waiting.append(request)
self.requests[request.request_id] = request
def schedule(self) -> "SchedulerOutput":
num_scheduled_tokens: Dict[str, int] = {}
token_budget = self.max_num_scheduled_tokens
# First, schedule the RUNNING requests.
req_index = 0
while req_index < len(self.running) and token_budget > 0:
request = self.running[req_index]
num_new_tokens = request.num_tokens_with_spec - request.num_computed_tokens
while True:
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens)
if new_blocks is None:
preempted_req = self.running.pop()
self.kv_cache_manager.free(preempted_req)
self.waiting.appendleft(preempted_req)
else:
can_schedule = True
break
if not can_schedule:
break
scheduled_running_reqs.append(request)
num_scheduled_tokens[request.request_id] = num_new_tokens
token_budget -= num_new_tokens
req_index += 1
if request.spec_token_ids:
scheduled_spec_decode_tokens[request.request_id] = (request.spec_token_ids)
# Next, schedule the WAITING requests.
if not preempted_reqs:
while self.waiting and token_budget > 0:
request = self.waiting[0]
computed_blocks, num_computed_tokens = self.kv_cache_manager.get_computed_blocks(request)
num_new_tokens = request.num_tokens - num_computed_tokens
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens, computed_blocks)
if new_blocks is None:
break
self.waiting.popleft()
self.running.append(request)
if request.status == RequestStatus.WAITING:
scheduled_new_reqs.append(request)
elif request.status == RequestStatus.PREEMPTED:
scheduled_resumed_reqs.append(request)
num_scheduled_tokens[request.request_id] = num_new_tokens
token_budget -= num_new_tokens
request.status = RequestStatus.RUNNING
request.num_computed_tokens = num_computed_tokens
total_num_scheduled_tokens = sum(num_scheduled_tokens.values())
new_reqs_data = [
NewRequestData.from_request(req,...) for req in scheduled_new_reqs
]
resumed_reqs_data = [ # CachedRequestData
self._make_cached_request_data(...) for req in scheduled_resumed_reqs
]
running_reqs_data = [ # CachedRequestData
self._make_cached_request_data(...) for req in scheduled_running_reqs
]
scheduler_output = SchedulerOutput(
scheduled_new_reqs=new_reqs_data,
scheduled_cached_reqs=resumed_reqs_data + running_reqs_data,
num_scheduled_tokens=num_scheduled_tokens,
total_num_scheduled_tokens=total_num_scheduled_tokens,
scheduled_spec_decode_tokens=scheduled_spec_decode_tokens,
)
return scheduler_output
def update_from_output(self, scheduler_output, model_runner_output) -> EngineCoreOutputs:
sampled_token_ids = model_runner_output.sampled_token_ids
for request in self.running:
req_id = request.request_id
req_index = model_runner_output.req_id_to_index[req_id]
generated_token_ids = sampled_token_ids[req_index]
if request.num_computed_tokens >= request.num_tokens:
for output_token_id in generated_token_ids:
request.append_output_token_ids(output_token_id)
stopped = self._check_stop(request)
if stopped:
self._free_request(request)
break
if not stopped:
new_running.append(request)
self.running = new_running
return EngineCoreOutputs(outputs=outputs,...)
scheduelr.add_request 比较简单,就是把请求放入 waiting deqeue 中。
调度部分相对复杂且迭代比较快,这里主要关注 v1 版本的核心实现。
scheduelr.schedule 返回 SchedulerOutput 包含两个列表,
scheduled_new_reqs来自 waiting queue,即处理新请求scheduled_cached_reqs来自 running queue 和 resumed requests,即继续处理正在处理中的请求
以 waiting queue 为例看调度过程:
- 处理 waiting queue 中的 0 号请求;
- 通过
kv_cache_manager.get_computed_blocks计算num_computed_tokens包括 cached; - 尝试通过
kv_cache_manager.allocate_slots分配 slots,成功则意味着可调度; - 将请求从 waiting queue 中移除,放入 running queue 中;
这里涉及 KVCacheManager 的部分在后面讨论。
关于调度算法,
# NOTE(woosuk) on the scheduling algorithm:
# There's no "decoding phase" nor "prefill phase" in the scheduler.
# Each request just has the num_computed_tokens and
# num_tokens_with_spec. num_tokens_with_spec =
# len(prompt_token_ids) + len(output_token_ids) + len(spec_token_ids).
# At each step, the scheduler tries to assign tokens to the requests
# so that each request's num_computed_tokens can catch up its
# num_tokens_with_spec. This is general enough to cover
# chunked prefills, prefix caching, speculative decoding,
# and the "jump decoding" optimization in the future.
scheduelr.update_from_output 处理 Executor 执行的结果。
这些结果应该包含在 running queue 中,所以 update_from_output 把结果更新到 request 中,
- 从
model_runner_output.sampled_token_ids中包含生成的 token ids; - 从 running queue 中取出 request 获取对应的生成结果 generated_token_ids;
- 依次从 generated_token_ids 中取出 token id,调用
request.append_output_token_ids更新到 request 中; - 通过
_check_stop判断是否停止调度,停止则调用_free_request释放 request; - 最后将未 stop 的 request 作为新的 running queue;
其中 _check_stop 判断的请求将结束调度,包括
- num_tokens_scheduled == 0 : 本次未调度的
- request.num_tokens >= self.max_model_len
- request.num_output_tokens >= request.max_tokens
- last_token_id == request.eos_token_id
- last_token_id in sampling_params.stop_token_ids
Executor
Excutor 是真正驱动进程执行 GPU 计算的模块。 从 EngineCore 的使用上可以看出,
- 首先是选择具体的 Executor 类实现,进行默认初始化
__init__ - 然后是 initialize 初始化 Executor
- 最后是 execute_model 执行模型返回结果
# AsyncLLM
executor_class = Executor.get_class(vllm_config)
# EngineCore
self.model_executor = executor_class(vllm_config)
self.model_executor.initialize(kv_cache_configs)
output = self.model_executor.execute_model(scheduler_output)
ExecutorBase
当 ExecutorBase 初始化 __init__ 的时候,会执行 _init_executor,这和 scheduler 中调用的 initialize 不是同一个函数。
_init_executor根据不同是实现执行Worker的init_worker,init_device,load_model.initialize会执行Worker的initialize_cache,compile_or_warm_up_model.
execute_model 根据不同的实现执行 Worker 的 execute_model.
# vllm/executor/executor_base.py
class ExecutorBase(ABC):
def __init__(self, vllm_config: VllmConfig) -> None:
self._init_executor()
def initialize_cache(self, num_gpu_blocks: int, num_cpu_blocks) -> None:
self.collective_rpc("initialize_cache", args=(num_gpu_blocks, num_cpu_blocks))
class DistributedExecutorBase(ExecutorBase):
def execute_model(self, execute_model_req: ExecuteModelRequest,) -> List[SamplerOutput]:
if self.parallel_worker_tasks is None:
self.parallel_worker_tasks = self._run_workers(
"start_worker_execution_loop",
async_run_tensor_parallel_workers_only=True)
driver_outputs = self._driver_execute_model(execute_model_req)
return driver_outputs
def collective_rpc(self, ...):
return self._run_workers(method, *args, **(kwargs or {}))
# vllm/v1/executor/abstract.py
class Executor(ExecutorBase):
@staticmethod
def get_class(vllm_config: VllmConfig) -> Type["Executor"]:
executor_class = RayDistributedExecutor
executor_class = MultiprocExecutor
executor_class = UniProcExecutor
executor_class = ExecutorWithExternalLauncher
return executor_class
def initialize(self, kv_cache_configs: List[KVCacheConfig]) -> None:
self.collective_rpc("initialize_cache", args=(kv_cache_configs, ))
self.collective_rpc("compile_or_warm_up_model")
def execute_model(self, scheduler_output,
) -> Union[ModelRunnerOutput, Future[ModelRunnerOutput]]:
output = self.collective_rpc("execute_model", args=(scheduler_output, ))
return output[0]
主要的 executor 有 RayDistributedExecutor, MultiprocExecutor, UniProcExecutor, ExecutorWithExternalLauncher.
RayDistributedExecutor
# vllm/v1/executor/ray_distributed_executor.py
class RayDistributedExecutor(RayDistributedExecutorV0, Executor):
def execute_model( self, scheduler_output,) -> Union[ModelRunnerOutput, Future[ModelRunnerOutput]]:
self.forward_dag = self._compiled_ray_dag(enable_asyncio=False)
refs = self.forward_dag.execute(scheduler_output)
return refs[0].get()
RayDistributedExecutorV0
# vllm/executor/ray_distributed_executor.py
# RayDistributedExecutorV0
class RayDistributedExecutor(DistributedExecutorBase):
def _init_executor(self) -> None:
initialize_ray_cluster(self.parallel_config) # ray.init(...)
self._init_workers_ray(placement_group)
def _init_workers_ray(self, placement_group, **ray_remote_kwargs):
bundle_indices = list(map(int, envs.VLLM_RAY_BUNDLE_INDICES.split(",")))
for rank, bundle_id in enumerate(bundle_indices):
scheduling_strategy = PlacementGroupSchedulingStrategy(placement_group, bundle_id,)
worker = ray.remote(num_cpus=0, num_gpus, scheduling_strategy, **ray_remote_kwargs,
)(RayWorkerWrapper).remote(vllm_config=self.vllm_config, rpc_rank=rank)
worker_metadata.append(RayWorkerMetaData(worker=worker, created_rank=rank))
self.workers = [item.worker for item in sorted_worker_metadata] # List[RayWorkerWrapper]
self._run_workers("adjust_rank", rerank_mapping)
self._run_workers("update_environment_variables", self._get_env_vars_to_be_updated())
self._run_workers("init_worker", all_kwargs)
self._run_workers("init_device")
self._run_workers("load_model", max_concurrent_workers)
def execute_model(self, execute_model_req: ExecuteModelRequest) -> List[SamplerOutput]:
outputs = ray.get(self.forward_dag.execute(execute_model_req))
return outputs[0]
def _run_workers(self, method, *args, **kwargs,) -> Any:
ray_workers = self.workers
ray_worker_outputs = [worker.execute_method.remote(method, ...) for worker in ray_workers]
if async_run_tensor_parallel_workers_only:
return ray_worker_outputs
ray_worker_outputs = ray.get(ray_worker_outputs)
return ray_worker_outputs
V1 版本的 RayDistributedExecutor 继承 V0 版本的 RayDistributedExecutor,改写了 execute_model 方法,使用 DAG 的实现.
V0 版本的 RayDistributedExecutor 在 __init__/_init_excutor 中
- 启动 ray 集群,然后再集群中启动 RayWorkerWrapper 实现的 worker
- 在 worker 中执行
adjust_rank和update_environment_variables方法 - 在 worker 中执行
init_worker,init_device和load_model方法
RayDistributedExecutor 中在 worker 中执行的方法通过 _run_workers 方法提供,其中支持异步和同步的能力。
因为它继承自 Executor,collective_rpc 即等价于 _run_workers 方法, 这里的层级实现关系略乱。
Ray 里通过 ray.remote 执行函数,通过 ray.get 获取结果。
MultiprocExecutor
# vllm/v1/executor/multiproc_executor.py
class MultiprocExecutor(Executor):
def _init_executor(self) -> None:
self.rpc_broadcast_mq = MessageQueue(self.world_size, self.world_size)
scheduler_output_handle = self.rpc_broadcast_mq.export_handle()
self.workers: List[WorkerProcHandle] = []
for rank in range(self.world_size):
worker = WorkerProc.make_worker_process(self.vllm_config, ...)
self.workers.append(worker)
def collective_rpc(self, method, ...) -> List[Any]:
if isinstance(method, str):
send_method = method
else:
send_method = cloudpickle.dumps(method, protocol=pickle.HIGHEST_PROTOCOL)
self.rpc_broadcast_mq.enqueue((send_method, args, kwargs))
responses = [None] * self.world_size
for w in self.workers:
status, result = w.worker_response_mq.dequeue(timeout=dequeue_timeout)
responses[w.rank] = result
return responses
class WorkerProc:
def __init__(self, vllm_config, local_rank, rank, ...):
wrapper = WorkerWrapperBase(vllm_config=vllm_config, ...)
wrapper.init_worker(all_kwargs)
self.worker = wrapper.worker
self.rpc_broadcast_mq = MessageQueue.create_from_handle(...)
self.worker_response_mq = MessageQueue(1, 1)
self.worker.init_device()
self.worker.load_model()
@staticmethod
def make_worker_process(vllm_config, ...) -> WorkerProcHandle:
proc = context.Process(target=WorkerProc.worker_main, ..., daemon=True)
proc.start()
return WorkerProcHandle(proc, rank, ready_path, worker_response_mq)
@staticmethod
def worker_main(*args, **kwargs):
try:
worker = WorkerProc(*args, **kwargs)
worker.worker_busy_loop()
def worker_busy_loop(self):
while True:
method, args, kwargs = self.rpc_broadcast_mq.dequeue()
func = getattr(self.worker, method)
output = func(*args, **kwargs)
self.worker_response_mq.enqueue((SUCCESS, output))
_init_executor 通过 WorkerProc.make_worker_process 创建并启动 worker 进程:
- 在初始化时调用 worker 本身的方法
init_device和load_model; - worker 进程启动后在
worker_busy_loop中,通过 MessageQueue 作为进程间通信的通道, 不断从rpc_broadcast_mq.dequeue获取方法名和参数,不断执行; - 执行结果通过
worker_response_mq.enqueue同样放入 MessageQueue;
调用 collective_rpc 时,即把调用参数放入 excutor 的 rpc_broadcast_mq.enqueue, 然后从 worker_response_mq.dequeue 获取执行结果.
MultiprocExecutor 中 initialize 通过 collective_rpc 执行 initialize_cache 和 compile_or_warm_up_model.
UniProcExecutor ExecutorWithExternalLauncher
# vllm/executor/uniproc_executor.py
class UniProcExecutor(ExecutorBase):
def _init_executor(self) -> None:
self.driver_worker = WorkerWrapperBase(vllm_config=self.vllm_config, rpc_rank=0)
self.collective_rpc("init_worker", args=([kwargs], ))
self.collective_rpc("init_device")
self.collective_rpc("load_model")
def collective_rpc(self, ...):
answer = run_method(self.driver_worker, method, args, kwargs)
return [answer]
class ExecutorWithExternalLauncher(UniProcExecutor):
单进程的 executor 更为简单,函数调用执行即可,值得注意的是这里可能处理序列化问题。
# vllm/utils.py
def run_method(obj: Any, method, args, kwargs) -> Any:
if isinstance(method, bytes):
func = partial(cloudpickle.loads(method), obj)
elif isinstance(method, str):
func = getattr(obj, method)
else:
func = partial(method, obj) # type: ignore
return func(*args, **kwargs)
Worker
如 excutor 中的分析,重点关注 worker 的以下函数:
- init_worker, init_device, load_model
- initialize_cache, compile_or_warm_up_model
- execute_model
init_worker 在 WorkerWrapperBase 中实现;
init_device, load_model, compile_or_warm_up_model 和 execute_model 在 Worker 中实现。
Worker 的实现依赖于 excutor,Ray 的 worker 使用 RayWorkerWrapper 构造,它继承自 WorkerWrapperBase,由 ray cluster 调度进程实现。
MultiprocExecutor 中已经包含了 WorkerProc 实现的进程,而 WorkerProc 依赖 WorkerWrapperBase 构造 worker。
UniProcExecutor 则直接通过 WorkerWrapperBase 构造 worker.
# vllm/worker/worker_base.py
class WorkerWrapperBase:
def __init__(self, vllm_config, rpc_rank) -> None:
self.worker: Optional[WorkerBase] = None
init_cached_hf_modules()
def init_worker(self, all_kwargs: List[Dict[str, Any]]) -> None:
worker_class = resolve_obj_by_qualname(self.vllm_config.parallel_config.worker_cls)
worker_class = cloudpickle.loads(self.vllm_config.parallel_config.worker_cls)
self.worker = worker_class(**kwargs)
def execute_method(self, method: Union[str, bytes], *args, **kwargs):
return run_method(target, method, args, kwargs)
这说明不同 excutor 的 worker 构造都指向 WorkerWrapperBase,而 worker 的具体实现则由 vllm_config.parallel_config.worker_cls 配置, 并支持自定义的实现。
# vllm/platforms/cuda.py
class CudaPlatformBase(Platform):
@classmethod
def check_and_update_config(cls, vllm_config: VllmConfig) -> None:
if parallel_config.worker_cls == "auto":
parallel_config.worker_cls = "vllm.v1.worker.gpu_worker.Worker"
在 GPU 场景下,worker 的实现为 vllm.v1.worker.gpu_worker.Worker.
# vllm/v1/worker/gpu_worker.py
class Worker(WorkerBase):
def init_device(self):
self.device = torch.device(f"cuda:{self.local_rank}")
torch.cuda.set_device(self.device)
self.model_runner: GPUModelRunner = GPUModelRunner(self.vllm_config, self.device)
def load_model(self) -> None:
self.model_runner.load_model()
def initialize_from_config(self, kv_cache_config: KVCacheConfig) -> None:
self.model_runner.initialize_kv_cache(kv_cache_config)
def compile_or_warm_up_model(self) -> None:
for size in sorted(warmup_sizes, reverse=True):
self.model_runner._dummy_run(size)
if not self.model_config.enforce_eager:
self.model_runner.capture_model()
def get_model(self) -> nn.Module:
return self.model_runner.get_model()
@torch.inference_mode()
def execute_model(self, scheduler_output) -> Optional[ModelRunnerOutput]:
output = self.model_runner.execute_model(scheduler_output)
return output if self.is_driver_worker else None
# vllm/v1/worker/worker_base.py
from vllm.worker.worker_base import WorkerBase as WorkerBaseV0
class WorkerBase(WorkerBaseV0):
可以看到,model_runner 会在 worker 的 init_device 中初始化,然后 load_model, initialize_from_config, compile_or_warm_up_model, execute_model 都是调用 model_runner 的对应方法。
近期代码改动将
initialize_cache修改为了initialize_from_config,不影响整体流程梳理。
GPUModelRunner
ModelRunner 是控制 Model 的 Runner, 它创建 model 对象并执行获得结果。不同的硬件有不同的 Runner 实现。
# vllm/v1/worker/gpu_model_runner.py
from vllm.model_executor.model_loader import get_model
class GPUModelRunner(LoRAModelRunnerMixin):
def load_model(self) -> None:
self.model = get_model(vllm_config=self.vllm_config)
def initialize_kv_cache(self, kv_cache_config: KVCacheConfig) -> None:
bind_kv_cache(kv_caches, ..., self.kv_caches)
@torch.inference_mode()
def _dummy_run(self, num_tokens: int,) -> torch.Tensor:
with set_forward_context(None, self.vllm_config, num_tokens=num_tokens):
hidden_states = model(..., input_ids=input_ids,)
return hidden_states
def capture_model(self) -> None:
...
@torch.inference_mode()
def execute_model(...) -> Union[ModelRunnerOutput, torch.Tensor]:
self._update_states(scheduler_output)
attn_metadata, logits_indices = self._prepare_inputs(scheduler_output)
with set_forward_context(attn_metadata, self.vllm_config):
hidden_states = self.model(input_ids=input_ids,...)
logits = self.model.compute_logits(sample_hidden_states, None)
sampler_output = self.model.sample(logits, sampling_metadata)
logprobs_tensors = sampler_output.logprobs_tensors
model_runner_output = ModelRunnerOutput(...)
return model_runner_output
GPUModelRunner 的实现比较复杂,它涉及到推理的核心调用,这里主要关注调用流程。 它调用 load_model 方法创建 Model, execute_model 方法驱动执行 model,输出 ModelRunnerOutput。
Model
Model 关注两个部分:
- model_loader 包括目录的模型文件,主流以 huggingface 的 safetensor 为主流;
- model 部分不同的模型有不同的定义实现,都实现 PyTorch 的 nn.Module, 比如 DeepseekForCausalLM, LlamaForCausalLM, 它们有各自的实现并在
vllm/model_executor/models/registry.py中注册。
# vllm/model_executor/model_loader/__init__.py
def get_model(*, vllm_config: VllmConfig) -> nn.Module:
loader = get_model_loader(vllm_config.load_config)
return loader.load_model(vllm_config=vllm_config)
# vllm/model_executor/model_loader/loader.py
def _initialize_model(vllm_config: VllmConfig,) -> nn.Module:
model_config = vllm_config.model_config
model_class, _ = get_model_architecture(model_config)
return model_class(**kwargs)
class DefaultModelLoader(BaseModelLoader):
def download_model(self, model_config: ModelConfig) -> None:
self._prepare_weights(model_config.model, ...)
def load_model(self, vllm_config: VllmConfig) -> nn.Module:
target_device = torch.device(device_config.device)
with set_default_torch_dtype(model_config.dtype):
with target_device:
model = _initialize_model(vllm_config=vllm_config)
loaded_weights = model.load_weights(self._get_all_weights(model_config, model))
_process_weights_after_loading(model, model_config, target_device)
return model.eval()
def get_model_loader(load_config: LoadConfig) -> BaseModelLoader:
if load_config.load_format == LoadFormat.BITSANDBYTES:
return BitsAndBytesModelLoader(load_config)
return DefaultModelLoader(load_config)
model_loader 读取并初始化模型权重等,按照规范的模型定义,本地不存在的模型可通过网络自动下载到本地。
# vllm/model_executor/models/llama.py
class LlamaForCausalLM(nn.Module, SupportsLoRA, SupportsPP):
def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
super().__init__()
self.model = self._init_model(vllm_config=vllm_config, prefix=maybe_prefix(prefix, "model"))
def _init_model(self, vllm_config: VllmConfig, prefix: str = ""):
return LlamaModel(vllm_config=vllm_config, prefix=prefix)
def forward(self, ...) -> Union[torch.Tensor, IntermediateTensors]:
model_output = self.model(input_ids, positions, intermediate_tensors, inputs_embeds)
return model_output
def compute_logits(self, hidden_states, sampling_metadata):
logits = self.logits_processor(self.lm_head, hidden_states, sampling_metadata)
return logits
def sample(self, logits: torch.Tensor, sampling_metadata: SamplingMetadata) -> Optional[SamplerOutput]:
next_tokens = self.sampler(logits, sampling_metadata)
return next_tokens
def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]) -> Set[str]:
loader = AutoWeightsLoader(self, ...)
return loader.load_weights(weights)
Model 相关的计算是推理的核心部分,同样的网络结构,不同的实现和优化方法也会有性能上的差异,例如使用 FlashAttention 技术,继承 FlashInfer 库的实现等。
KVCache
KV Cache 作为推理引擎里的重要一环,cache 管理主要通过 KVCacheManager 和 BlockPool 两个对象实现。
KVCacheManager
以下方法参与了 Scheduler 的核心逻辑实现,功能也如字面所示。
kv_cache_manager.get_computed_blocks
kv_cache_manager.allocate_slots
kv_cache_manager.free
# vllm/v1/core/kv_cache_manager.py
class KVCacheManager:
def __init__(self, ...) -> None:
self.block_size = block_size
self.block_pool = BlockPool(num_gpu_blocks, enable_caching)
self.req_to_blocks: DefaultDict[str, List[KVCacheBlock]] = defaultdict(list)
self.req_to_block_hashes: DefaultDict[str, List[BlockHashType]] = defaultdict(list)
def get_computed_blocks(self, request: Request) -> Tuple[List[KVCacheBlock], int]:
computed_blocks = []
block_hashes = self.req_to_block_hashes[request.request_id]
for block_hash in block_hashes:
if cached_block := self.block_pool.get_cached_block(block_hash):
computed_blocks.append(cached_block)
else:
break
num_computed_tokens = len(computed_blocks) * self.block_size
return computed_blocks, num_computed_tokens
def allocate_slots(self, request: Request,) -> Optional[List[KVCacheBlock]]:
"""Blocks layout:
-----------------------------------------------------------------------
| < computed > | < new computed > | < new > | < pre-allocated > |
-----------------------------------------------------------------------
| < required > |
--------------------------------------------------
| < full > |
------------------------------------------------
| <new full> |
--------------
"""
num_computed_tokens = (request.num_computed_tokens + len(new_computed_blocks) * self.block_size)
num_required_blocks = cdiv(num_computed_tokens + num_tokens, self.block_size)
req_blocks = self.req_to_blocks[request.request_id]
num_new_blocks = (num_required_blocks - len(req_blocks) - len(new_computed_blocks))
req_blocks.extend(new_computed_blocks)
if num_new_blocks <= 0:
new_blocks = []
else:
new_blocks = self.block_pool.get_new_blocks(num_new_blocks)
req_blocks.extend(new_blocks)
self.block_pool.cache_full_blocks(
request=request,
blocks=req_blocks,
block_hashes=self.req_to_block_hashes[request.request_id],
num_cached_blocks=num_cached_blocks,
num_full_blocks=num_full_blocks_after_append,
block_size=self.block_size,
)
return new_blocks
当通过 kv_cache_manager.allocate_slots 成功分配了 slots,则意味着可调度, 继续后续实际的计算。
BlockPool
Cache 的管理以 block 为粒度,BlockPool 实现了 block/KVCacheBlock 的管理细节。
block_pool = BlockPool(num_gpu_blocks, enable_caching)
block_pool.get_cached_block(block_hash)
block_pool.get_new_blocks(num_new_blocks)
block_pool.cache_full_blocks(...)
# vllm/v1/core/block_pool.py
class BlockPool:
def __init__(self, num_gpu_blocks: int, enable_caching: bool):
self.num_gpu_blocks = num_gpu_blocks
self.enable_caching = enable_caching
self.blocks: List[KVCacheBlock] = [
KVCacheBlock(idx) for idx in range(num_gpu_blocks)
]
self.free_block_queue = FreeKVCacheBlockQueue(self.blocks)
self.cached_block_hash_to_block: Dict[BlockHashType, Dict[int, KVCacheBlock]] = defaultdict(dict)
def get_cached_block(self, block_hash: BlockHashType) -> Optional[KVCacheBlock]:
if block_hash in self.cached_block_hash_to_block:
first_block_id = list(self.cached_block_hash_to_block[block_hash].keys())[0]
return self.cached_block_hash_to_block[block_hash][first_block_id]
return None
def cache_full_blocks(self, ...) -> None:
new_full_blocks = blocks[num_cached_blocks:num_full_blocks]
new_block_hashes = block_hashes[num_cached_blocks:]
if num_cached_blocks == 0:
prev_block_hash_value = None
else:
prev_block = blocks[num_cached_blocks - 1]
prev_block_hash_value = prev_block.block_hash.hash_value
for i, blk in enumerate(new_full_blocks):
if i < len(new_block_hashes):
block_hash = new_block_hashes[i]
else:
blk_idx = num_cached_blocks + i
start_token_idx = blk_idx * block_size
end_token_idx = (blk_idx + 1) * block_size
block_tokens = request.all_token_ids[start_token_idx:end_token_idx]
extra_keys, _ = generate_block_hash_extra_keys(request, start_token_idx, end_token_idx, -1)
block_hash = hash_block_tokens(prev_block_hash_value, block_tokens, extra_keys)
block_hashes.append(block_hash)
blk.block_hash = block_hash
self.cached_block_hash_to_block[block_hash][blk.block_id] = blk
prev_block_hash_value = block_hash.hash_value
def get_new_blocks(self, num_blocks: int) -> List[KVCacheBlock]:
ret: List[KVCacheBlock] = []
idx = 0
while idx < num_blocks:
curr_block = self.free_block_queue.popleft()
curr_block.incr_ref()
ret.append(curr_block)
idx += 1
return ret
Reference
bf33700ecd6db472c4aeb489c5d42aa47a735198
- https://github.com/vllm-project/vllm
- https://platform.openai.com/docs/api-reference/chat/create
- https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
vllm
sglang
Entrypoint
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3-0324 --tp 8 --port 30000 --host 0.0.0.0 --mem-fraction-static 0.9
Refereces
commit: 9069884b5140f95fc4a381b5c98114717744e110
pytorch
torchrun
本文使用代码版本 commit: 0da8127f77f9bf05ba204ea7659cb15ec85e88a7
PyTorch 提供了原生的分布式启动命令 torchrun,可以用于启动分布式训练任务。
例如通过以下命令可以启动一个 2 节点的分布式训练任务,该命令需要在所有 2 个节点上执行。
torchrun
--nnodes=2
--nproc-per-node=8
--rdzv-endpoint=123.45.67.89:36123
--rdzv-backend=c10d
demo.py
根据环境变量转换规则,env action, 上述启动命令等价于以下命令:
export PET_NPROC_PER_NODE=8
export PET_NNODES=2
export PET_RDZV_ENDPOINT=123.45.67.89:36123
export PET_RDZV_BACKEND=c10d
torchrun demo.py
其中 demo.py 可以是如下的可以用于测试完整流程的 allreduce 例子.
# demo.py
import torch
torch.distributed.init_process_group(backend="nccl", init_method="env://")
rank = torch.distributed.get_rank()
torch.cuda.set_device(rank % torch.cuda.device_count())
world_size = torch.distributed.get_world_size()
print(f"rank {rank} world_size {world_size}")
a = torch.tensor([1]).cuda()
torch.distributed.all_reduce(a)
print(f"rank {rank} world_size {world_size} {a}")
torch.distributed.barrier()
print(f"rank {rank} world_size {world_size}")
在无 GPU 的环境下可以使用以下 demo 进行测试
import torch
torch.distributed.init_process_group(backend="gloo", init_method="env://")
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
print(f"rank {rank} world_size {world_size}")
a = torch.tensor([1])
torch.distributed.all_reduce(a)
print(f"rank {rank} world_size {world_size} {a}")
torch.distributed.barrier()
print(f"rank {rank} world_size {world_size}")
下面分析启动的细节流程。
run
根据 setup.py 可以看出 torchrun 对应的启动函数
# setup.py
def configure_extension_build():
entry_points = {
"console_scripts": [
"torchrun = torch.distributed.run:main",
],
}
在 pytorch 1.9.0 版本后引入 torch.distributed.run 模块取代 torch.distributed.launch 启动分布式任务并支持弹性容错能力。
# torch/distributed/run.py
from torch.distributed.launcher.api import elastic_launch
def run(args):
config, cmd, cmd_args = config_from_args(args)
elastic_launch(config=config, entrypoint=cmd,)(*cmd_args)
@record
def main(args=None):
args = parse_args(args)
run(args)
if __name__ == "__main__":
main()
可以看到实际执行的是伪装成函数的 elastic_launch 类
# torch/distributed/launcher/api.py
class elastic_launch:
def __init__(self, config: LaunchConfig, entrypoint: Union[Callable, str, None],):
self._config = config
self._entrypoint = entrypoint
def __call__(self, *args):
return launch_agent(self._config, self._entrypoint, list(args))
def launch_agent(config: LaunchConfig, entrypoint: Union[Callable, str, None], args: list[Any],):
rdzv_parameters = RendezvousParameters(
backend=config.rdzv_backend,
endpoint=config.rdzv_endpoint,
run_id=config.run_id,
min_nodes=config.min_nodes,
max_nodes=config.max_nodes,
local_addr=config.local_addr,
**config.rdzv_configs,
)
master_addr, master_port = _get_addr_and_port(rdzv_parameters)
spec = WorkerSpec(
role=config.role,
local_world_size=config.nproc_per_node,
entrypoint=entrypoint,
args=tuple(args),
rdzv_handler=rdzv_registry.get_rendezvous_handler(rdzv_parameters),
master_addr=master_addr,
master_port=master_port,
)
agent = LocalElasticAgent(spec=spec, ...)
try:
result = agent.run()
return result.return_values
def _get_addr_and_port(rdzv_parameters: RendezvousParameters,) -> tuple[Optional[str], Optional[int]]:
if rdzv_parameters.backend != "static":
return (None, None)
endpoint = rdzv_parameters.endpoint
endpoint = endpoint.strip()
master_addr, master_port = parse_rendezvous_endpoint(endpoint, default_port=-1)
return (master_addr, master_port)
elastic_launch 通过 launch_agent 实现了主要的启动流程。
- 通过启动参数定义 rendezvous, 用于节点间的协同模块
- 定义进程 worker 的描述信息 WorkerSpec,一个 worker 对应一个进程,一般对应一个 GPU
- 定义并启动 agent, LocalElasticAgent 在每个分布式节点上启动,管理节点上的多个 worker 进程
注意到:
- 当 rendezvous backend 为
static时,worker 中的master_addr和master_port为None, 否则比如为 c10d 时,master_addr和master_port为 endpoint 中的 ip 和 port. - 根据
rendezvous backend参数会从rdzv_registry中选择对应的rendezvous handler,比如etcd,c10d等,不同的 handler 采用不同的方式实现 rendezvous 即分布式节点间如何协同.
worker
这里的 worker 并没有被封装成 process 的抽象, 所以 worker 部分相对比较简单。 WorkerSpec/Worker 都只是包含了 worker 的描述信息,WorkerGroup 包含 worker 的集合信息。
# torch/distributed/elastic/agent/server/api.py
@dataclass
class WorkerSpec:
role: str
local_world_size: int
rdzv_handler: rdzv.RendezvousHandler
fn: Optional[Callable] = None
entrypoint: Union[Callable, str, None] = None
args: tuple = ()
max_restarts: int = 3
monitor_interval: float = 0.1
master_port: Optional[int] = None
master_addr: Optional[str] = None
local_addr: Optional[str] = None
class Worker:
def __init__(
self,
local_rank: int,
global_rank: int = -1,
role_rank: int = -1,
world_size: int = -1,
role_world_size: int = -1,
):
self.id: Any = None
self.local_rank: int = local_rank
self.global_rank: int = global_rank
self.role_rank: int = role_rank
self.world_size: int = world_size
self.role_world_size: int = role_world_size
class WorkerGroup:
def __init__(self, spec: WorkerSpec):
self.spec = spec
self.workers = [Worker(local_rank=i) for i in range(self.spec.local_world_size)]
self.master_addr = None
self.master_port = None
self.state = WorkerState.INIT
rendezvous
rendezvous, 法语词,字面意思的约会,读音“夯dēi勿”, 用于分布式节点间协同,简单说就是节点间如何找到彼此,协商各自的 rank 等信息。
# torch/distributed/elastic/rendezvous/__init__.py
from .registry import _register_default_handlers
_register_default_handlers()
可用的 rendezvous backend 是静态定义的,当前版本支持:etcd, etcd-v2, c10d, static,初始化化时注册到 handler_registry 中,通过 rdzv_registry.get_rendezvous_handler 获取对应的 handler.
# torch/distributed/elastic/rendezvous/registry.py
def _register_default_handlers() -> None:
handler_registry.register("etcd", _create_etcd_handler)
handler_registry.register("etcd-v2", _create_etcd_v2_handler)
handler_registry.register("c10d", _create_c10d_handler)
handler_registry.register("static", _create_static_handler)
def _create_static_handler(params: RendezvousParameters) -> RendezvousHandler:
from . import static_tcp_rendezvous
return static_tcp_rendezvous.create_rdzv_handler(params)
def _create_c10d_handler(params: RendezvousParameters) -> RendezvousHandler:
from .c10d_rendezvous_backend import create_backend
backend, store = create_backend(params)
return create_handler(store, backend, params)
这里主要看 c10d 的实现,c10d 的 tcp 版本通过 TCPStore 实现了 rendezvous,TCPStore 就是 pytorch 中重要的 kv 存储实现,在 init_process_group 等多个场景中都有使用。
# torch/distributed/elastic/rendezvous/c10d_rendezvous_backend.py
def create_backend(params: RendezvousParameters) -> tuple[C10dRendezvousBackend, Store]:
if store_type == "file":
store = _create_file_store(params)
elif store_type == "tcp":
store = _create_tcp_store(params)
backend = C10dRendezvousBackend(store, params.run_id)
return backend, store
def _create_tcp_store(params: RendezvousParameters) -> TCPStore:
host, port = parse_rendezvous_endpoint(params.endpoint, default_port=DEFAULT_PORT)
store = TCPStore(
host,
port,
is_master=is_server,
multi_tenant=True,
timeout=timedelta(seconds=read_timeout),
)
return store
划重点:用户参数中传递的 endpoint 对应的 host 和 port 会启动 TCPStore 服务端。
区别于 static backend, 使用 c10d 创建的 rendezvous 是动态 DynamicRendezvousHandler, 可以想见,它支持动态地进行节点协同,即在完成首次 rendezvous 后,可以动态的添加节点,删除节点,重新同步节点间的信息。
# torch/distributed/elastic/rendezvous/dynamic_rendezvous.py
def create_handler(store: Store, backend: RendezvousBackend, params: RendezvousParameters) -> DynamicRendezvousHandler:
return DynamicRendezvousHandler.from_backend(...)
class DynamicRendezvousHandler(RendezvousHandler):
_node_desc_generator = _NodeDescGenerator()
@classmethod
def from_backend(...):
node = cls._node_desc_generator.generate(local_addr)
return cls(node, settings, backend.name, store, state_holder)
def __init__(...):
self._this_node = node
self._bootstrap_store_info: Optional[RendezvousStoreInfo] = None
def next_rendezvous(self) -> RendezvousInfo:
try:
rank, world_size = self._get_world()
store = self._get_store()
if os.getenv("TORCH_DISABLE_SHARE_RDZV_TCP_STORE", "0") == "1":
bootstrap_store_info = RendezvousStoreInfo.build(
rank, store, local_addr=self._this_node.addr
)
return RendezvousInfo(
store,
rank,
world_size,
bootstrap_store_info,
)
# This will only be hit when TCPStore sharing is enabled.
if self._bootstrap_store_info is None:
server_port = 0
if rank == 0:
self._shared_tcp_store_server = self._create_tcp_store_server(
self._this_node.addr, server_port
)
server_port = self._shared_tcp_store_server.port
self._bootstrap_store_info = RendezvousStoreInfo.build(
rank,
store,
local_addr=self._this_node.addr,
server_port=server_port, # For non-0 rank, this is a no-op
)
return RendezvousInfo(
store,
rank,
world_size,
self._bootstrap_store_info, # type: ignore[assignment]
)
class _NodeDescGenerator:
def generate(self, local_addr: Optional[str] = None) -> _NodeDesc:
return _NodeDesc(local_addr or socket.getfqdn(), os.getpid(), local_id)
可以看到 rendezvous 的结果通过 RendezvousInfo 进行了封装,其中包含了 rank 和 world_size 信息。
其中 RendezvousInfo 包含两个 TCPStore:
store是使用参数 rdzv endpoint 创建的 TCPStore;_bootstrap_store_info中 master 存储了通过 store 交换回来的 addr 为 rank-0 地址,port 为 _create_tcp_store_server 创建的新的 TCPStore 的端口;
# torch/distributed/elastic/rendezvous/api.py
@dataclass
class RendezvousStoreInfo:
@staticmethod
def build(
rank: int,
store: Store,
local_addr: Optional[str],
server_port: Optional[int] = None,
) -> "RendezvousStoreInfo":
if rank == 0:
addr = local_addr or socket.getfqdn()
port = server_port or get_free_port()
store.set(
RendezvousStoreInfo.MASTER_ADDR_KEY,
addr.encode(encoding="UTF-8"), # type: ignore[arg-type]
)
store.set(
RendezvousStoreInfo.MASTER_PORT_KEY,
str(port).encode(encoding="UTF-8"), # type: ignore[arg-type]
)
addr = store.get(RendezvousStoreInfo.MASTER_ADDR_KEY).decode(encoding="UTF-8")
port = int(
store.get(RendezvousStoreInfo.MASTER_PORT_KEY).decode(encoding="UTF-8")
)
return RendezvousStoreInfo(master_addr=addr, master_port=port)
- rank 为 0 的 “主节点” 会将自己的地址和端口信息存储到
store中,所有节点会从store中获取新的 master 地址和端口信息即 rank 0 的信息存储在 RendezvousStoreInfo 中并返回; - 每次执行都可能更新信息,每次调用
next_rendezvous都会返回新的RendezvousInfo,返回新的master地址和端口; - 在弹性容错逻辑中,
_restart_workers会通过_initialize_workers调用_rendezvous来重新刷新 rank 等信息,RendezvousInfo 中的 master_addr/master_port 信息将会被使用;
agent
从上述启动流程可以看到,agent 是启动的核心,rendezvous 和 worker 的定义都是传递给 agent,然后调用 agent 的 run 方法启动,这是一个阻塞函数,它代表了节点的生命周期,也即 torchrun 进程可以等同于 agent 进程。
LocalElasticAgent 中的 run 函数在父类 SimpleElasticAgent 中实现,
# torch/distributed/elastic/agent/server/api.py
class SimpleElasticAgent(ElasticAgent):
def __init__(self, spec: WorkerSpec, exit_barrier_timeout: float = 300):
self._worker_group = WorkerGroup(spec)
def _rendezvous(self, worker_group: WorkerGroup) -> None:
spec = worker_group.spec
rdzv_info = spec.rdzv_handler.next_rendezvous()
store = rdzv_info.store
group_rank = rdzv_info.rank
group_world_size = rdzv_info.world_size
master_addr = spec.master_addr or rdzv_info.bootstrap_store_info.master_addr
master_port = spec.master_port or rdzv_info.bootstrap_store_info.master_port
self._store = store
workers = self._assign_worker_ranks(
store, group_rank, group_world_size, spec
)
worker_group.workers = workers
worker_group.store = store
worker_group.group_rank = group_rank
worker_group.group_world_size = group_world_size
worker_group.master_addr = master_addr
worker_group.master_port = master_port
def _assign_worker_ranks(
self, store, group_rank: int, group_world_size: int, spec: WorkerSpec
) -> list[Worker]:
base_role_rank = ...
role_world_size = ...
workers = []
for local_rank in range(spec.local_world_size):
worker = Worker(
local_rank=local_rank,
global_rank=base_global_rank + local_rank,
role_rank=base_role_rank + local_rank,
world_size=global_world_size,
role_world_size=role_world_size,
)
workers.append(worker)
return workers
def _initialize_workers(self, worker_group: WorkerGroup) -> None:
role = worker_group.spec.role
self._rendezvous(worker_group)
worker_ids = self._start_workers(worker_group)
for local_rank, w_id in worker_ids.items():
worker = worker_group.workers[local_rank]
worker.id = w_id
worker_group.state = WorkerState.HEALTHY
def _restart_workers(self, worker_group: WorkerGroup) -> None:
self._stop_workers(worker_group, is_restart=True)
self._initialize_workers(worker_group)
def run(self, role: str = DEFAULT_ROLE) -> RunResult:
result = self._invoke_run(role)
return result
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
spec = self._worker_group.spec
role = spec.role
self._initialize_workers(self._worker_group)
rdzv_handler = spec.rdzv_handler
while True:
time.sleep(monitor_interval)
run_result = self._monitor_workers(self._worker_group)
state = run_result.state
self._worker_group.state = state
if state == WorkerState.SUCCEEDED:
self._exit_barrier()
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
self._remaining_restarts -= 1
self._restart_workers(self._worker_group)
elif state == WorkerState.HEALTHY:
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
LocalElasticAgent 中主要实现了 _start_workers 和 _monitor_workers, 这里和进程的封装 PContext 进行交互。
# torch/distributed/elastic/agent/server/local_elastic_agent.py
class LocalElasticAgent(SimpleElasticAgent):
def __init__(
self,
spec: WorkerSpec,
start_method="spawn",
):
super().__init__(spec, exit_barrier_timeout)
self._start_method = start_method
self._pcontext: Optional[PContext] = None
self._rdzv_handler = spec.rdzv_handler
def _start_workers(self, worker_group: WorkerGroup) -> dict[int, Any]:
spec = worker_group.spec
store = worker_group.store
use_agent_store: bool = spec.rdzv_handler.use_agent_store
args: dict[int, tuple] = {}
envs: dict[int, dict[str, str]] = {}
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),
"RANK": str(worker.global_rank),
"GROUP_RANK": str(worker_group.group_rank),
"ROLE_RANK": str(worker.role_rank),
"ROLE_NAME": spec.role,
"LOCAL_WORLD_SIZE": str(spec.local_world_size),
"WORLD_SIZE": str(worker.world_size),
"GROUP_WORLD_SIZE": str(worker_group.group_world_size),
"ROLE_WORLD_SIZE": str(worker.role_world_size),
"MASTER_ADDR": worker_group.master_addr,
"MASTER_PORT": str(worker_group.master_port),
"TORCHELASTIC_RESTART_COUNT": str(restart_count),
"TORCHELASTIC_MAX_RESTARTS": str(spec.max_restarts),
"TORCHELASTIC_RUN_ID": spec.rdzv_handler.get_run_id(),
"TORCHELASTIC_USE_AGENT_STORE": str(use_agent_store),
"TORCH_NCCL_ASYNC_ERROR_HANDLING": os.getenv(
"TORCH_NCCL_ASYNC_ERROR_HANDLING", str(1)
),
}
if "OMP_NUM_THREADS" in os.environ:
worker_env["OMP_NUM_THREADS"] = os.environ["OMP_NUM_THREADS"]
envs[local_rank] = worker_env
worker_args = list(spec.args)
worker_args = macros.substitute(worker_args, str(local_rank))
args[local_rank] = tuple(worker_args)
self._pcontext = start_processes(
name=spec.role,
entrypoint=spec.entrypoint,
args=args,
envs=envs,
logs_specs=self._logs_specs,
log_line_prefixes=log_line_prefixes,
start_method=self._start_method,
)
return self._pcontext.pids()
def _monitor_workers(self, worker_group: WorkerGroup) -> RunResult:
result = self._pcontext.wait(0)
if result:
if result.is_failed():
return RunResult(state=WorkerState.FAILED, failures=worker_failures)
else:
return RunResult(state=WorkerState.SUCCEEDED, return_values=workers_ret_vals)
else:
return RunResult(state=WorkerState.HEALTHY)
进程环境变量
注意到 worker_env 是配置给进程的环境变量,其中 MASTER_ADDR/MASTER_PORT 来自于 worker_group,
它在 SimpleElasticAgent._rendezvous 中被赋值
master_addr = spec.master_addr or rdzv_info.bootstrap_store_info.master_addr
master_port = spec.master_port or rdzv_info.bootstrap_store_info.master_port
worker_group.master_addr = master_addr
worker_group.master_port = master_port
当 rdvz-backend != static 时,
由 WorkerSpec 定义的 worker_group.master_addr/master_port 赋值为 None,
使得上述 worker_group.master_addr/master_port 由 rdzv_info.bootstrap_store_info 赋值。
而 rdzv_info 在 DynamicRendezvousHandler.next_rendezvous 中生成。
在 next_rendezvous 中 RendezvousStoreInfo 里的 master 信息取决于 self._this_node, 它来自于 _NodeDescGenerator.generate 的返回
_NodeDesc(local_addr or socket.getfqdn(), os.getpid(), local_id)
这里的 local_addr 来自于启动命令的 --local-addr 参数,所以如果未使用该参数时,MASTER_ADDR 由 socket.getfqdn() 得到,即本机域名。MASTER_PORT 为在 next_rendezvous 启动 store server 分配到的端口.
注意,这里的新 store 信息会通过已有的 store 在 RendezvousStoreInfo.build 进行同步,所有 group 内的节点都会获得该信息。
启动流程:
简化后的启动流程如下:
# launch_agent 中定义 进程的基础信息: 例如机器有 8 个 gpu,对应 8 个进程
spec = WorkerSpec(...) # launch_agent
local_world_size=config.nproc_per_node,
# 根据 WorkerSpec 构建 WorkerGroup: 本机的 8 个进程抽象为 8 个 Worker,并组成 WorkerGroup
self._worker_group = WorkerGroup(spec) # agent init
self.workers = [Worker(local_rank=i) for i in range(self.spec.local_world_size)]
# 根据 WorkerGroup 初始化 worker
self._initialize_workers(self._worker_group)
# rendezvous 过程
self._rendezvous(worker_group)
# 通过对应的 rendezvous 模式获取共建信息: 协同分配 rank 的媒介
rdzv_info = spec.rdzv_handler.next_rendezvous()
# 根据全局信息为每个 worker 计算分配 rank
workers = self._assign_worker_ranks(...)
# 启动 workers
worker_ids = self._start_workers(worker_group)
# 为每个 worker 配置环境变量并启动进程
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),
"RANK": str(worker.global_rank),
"GROUP_RANK": str(worker_group.group_rank),
}
envs[local_rank] = worker_env
args[local_rank] = tuple(worker_args)
self._pcontext = start_processes(...)
rank 计算:
- local_rank: 本节点内进程粒度的 rank
- global_rank: 全局进程粒度的 rank
- group_rank: 全局节点粒度的 rank
group_rank 计算方式:
global_rank = group_rank * group_world_size + local_rank
rank 计算的逻辑处理好累计问题其实比较简单,此处不详细展开。
elastic:
agent 的弹性能力体现在 _invoke_run 中,_invoke_run 会循环检测 worker 进程的状态:
- 如果 worker 进程正常退出则正常退出;
- 如果 worker 进程异常退出则重启 worker 进程;
- 如果 worker 进程正常但是有节点处于等待状态,即其他节点故障时会触发当前节点重启 worker 进程;
可以看出,agent 对当前节点上的 worker 进程负责,监控他们的健康状态,按需重启。
注意这里的查看状态函数 _monitor_workers 底层使用 timeout=0 的 poll 操作,所以是非阻塞的,而当前循环的等待是靠显示 sleep 实现的。
为什么其他节点故障时会触发当前节点重启 worker 进程?
当前架构中 agent-workers agent 是负责管理的进程,worker 是真正执行任务的进程,worker 之间还会通过 NCCL/gloo 等方式创建通信域进行通信从而可以交换数据。 当有节点故障时,当前逻辑是每个节点上的 agent 进程不退出,但是所有节点包括健康节点上的 worker 进程都会退出,再节点替换等逻辑恢复后,agent 重新拉起 worker 进程进而实现弹性。
这一实现的主要原因如下:
- 假设发生故障后,只有故障节点退出,健康节点的 worker 进程不退出,那么新 worker 启动后需要重新和已有进程建立新的通信域,这个过程的实现会极为复杂,远没有所有进程重启简单且稳定;
- 在 NCCL 信息域的角度看,peer 节点的异常是几乎无法感知的,无法感知就无法采取其他动作,并且不是处在所有状态的 OP 都是可撤销的(其实大多数是不可撤销的),即使利用超时等不可以的逻辑之上依然难以实现稳定的重建逻辑;
- 从 workflow 的角度看,worker 进程中的工作进程大概可以看作是计算、通信 OP 的串行序列,并没有一个 supervisor 的角色负责确认是否异常等上层逻辑,实现难度大且不够优雅。
以上原因导致主流的实现都使用 GPU 进程重启方式应对故障,实现容错和弹性。当然如果从探索角度看的话这已经不是一个新的话题,早几年就已经有相关的论文。
rendezvous version
在最近的几个版本中,rendevous 模块有一些比较大的变化,所以导致启动行为有写不一样,这里做一个简单对比。
v2.6.0 & v2.7.0
# torch/distributed/elastic/rendezvous/dynamic_rendezvous.py
class DynamicRendezvousHandler(RendezvousHandler):
def next_rendezvous(self) -> RendezvousInfo:
try:
rank, world_size = self._get_world()
store = self._get_store()
if self._bootstrap_store_info is None:
# To avoid race in get_free_port because we release the port after the call,
# we want to create a TCPStore server soon afterwards.
server_port = 0
if rank == 0:
self._shared_tcp_store_server = self._create_tcp_store_server(
self._this_node.addr, server_port
)
server_port = self._shared_tcp_store_server.port
self._bootstrap_store_info = RendezvousStoreInfo.build(
rank,
store,
local_addr=self._this_node.addr,
server_port=server_port, # For non-0 rank, this is a no-op
)
return RendezvousInfo(
store,
rank,
world_size,
self._bootstrap_store_info, # type: ignore[assignment]
)
# torch/distributed/elastic/rendezvous/api.py
@dataclass
class RendezvousStoreInfo:
@staticmethod
def build(
rank: int,
store: Store,
local_addr: Optional[str],
server_port: Optional[int] = None,
) -> "RendezvousStoreInfo":
if rank == 0:
addr = local_addr or socket.getfqdn()
# When TCPStore is not shared, we fallback to get_free_port.
port = server_port or get_free_port()
store.set(RendezvousStoreInfo.MASTER_ADDR_KEY, addr.encode(encoding="UTF-8"))
store.set(RendezvousStoreInfo.MASTER_PORT_KEY, str(port).encode(encoding="UTF-8"))
addr = store.get(RendezvousStoreInfo.MASTER_ADDR_KEY).decode(encoding="UTF-8")
port = int(
store.get(RendezvousStoreInfo.MASTER_PORT_KEY).decode(encoding="UTF-8")
)
return RendezvousStoreInfo(master_addr=addr, master_port=port)
在最新的两个版本中,接收通过 local_addr 指定本机地址,都通过 RendezvousStoreInfo.build 同步到 master_addr 和 master_port 信息。
v2.5.1
# torch/distributed/elastic/rendezvous/dynamic_rendezvous.py
class DynamicRendezvousHandler(RendezvousHandler):
def next_rendezvous(self) -> RendezvousInfo:
try:
rank, world_size = self._get_world()
store = self._get_store()
if self._bootstrap_store_info is None:
if isinstance(self._store, dist.TCPStore):
addr = self._store.host
port = self._store.port
self._bootstrap_store_info = RendezvousStoreInfo(
master_addr=addr, master_port=port
)
if rank == 0:
self._shared_tcp_store_server = self._store
else:
# If the store is not type of TCPStore start TCPStore server, which requries
# bootstrapping info across ranks
self._bootstrap_store_info = RendezvousStoreInfo.build(
rank, store, local_addr=self._this_node.addr
)
if rank == 0:
self._shared_tcp_store_server = self._create_tcp_store_server(
self._bootstrap_store_info
)
return RendezvousInfo(
store,
rank,
world_size,
self._bootstrap_store_info, # type: ignore[assignment]
)
# torch/distributed/elastic/rendezvous/api.py
@dataclass
class RendezvousStoreInfo:
@staticmethod
def build(
rank: int, store: Store, local_addr: Optional[str]
) -> "RendezvousStoreInfo":
if rank == 0:
addr = local_addr or socket.getfqdn()
port = _get_free_port()
store.set(RendezvousStoreInfo.MASTER_ADDR_KEY, addr.encode(encoding="UTF-8"))
store.set(RendezvousStoreInfo.MASTER_PORT_KEY, str(port).encode(encoding="UTF-8"))
addr = store.get(RendezvousStoreInfo.MASTER_ADDR_KEY).decode(encoding="UTF-8")
port = int(
store.get(RendezvousStoreInfo.MASTER_PORT_KEY).decode(encoding="UTF-8")
)
return RendezvousStoreInfo(master_addr=addr, master_port=port)
在 v2.5.1 版本中,当原 store 为 TCPStore 时,会直接构造并返回 RendezvousStoreInfo,不再创建新的 store.
v2.4.1
# torch/distributed/elastic/rendezvous/dynamic_rendezvous.py
class DynamicRendezvousHandler(RendezvousHandler):
def next_rendezvous(self) -> RendezvousInfo:
try:
rank, world_size = self._get_world()
store = self._get_store()
bootstrap_store_info = RendezvousStoreInfo.build(rank, store)
return RendezvousInfo(
store,
rank,
world_size,
bootstrap_store_info,
)
# torch/distributed/elastic/rendezvous/api.py
@dataclass
class RendezvousStoreInfo:
@staticmethod
def build(rank: int, store: Store) -> "RendezvousStoreInfo":
if rank == 0:
addr = socket.getfqdn()
port = _get_free_port()
store.set(RendezvousStoreInfo.MASTER_ADDR_KEY, addr.encode(encoding="UTF-8"))
store.set(RendezvousStoreInfo.MASTER_PORT_KEY, str(port).encode(encoding="UTF-8"))
addr = store.get(RendezvousStoreInfo.MASTER_ADDR_KEY).decode(encoding="UTF-8")
port = int(store.get(RendezvousStoreInfo.MASTER_PORT_KEY).decode(encoding="UTF-8"))
return RendezvousStoreInfo(master_addr=addr, master_port=port)
在 v2.4.1 版本中,统一通过
RendezvousStoreInfo.build 同步 master 信息,master 的 addr 通过 socket.getfqdn() 获取,无法指定。
Reference
Tensor
How torch.tensor works ?
init
What's behind import torch ?
# torch/__init__.py
from torch._C import *
cf doc
// torch/csrc/stub.c
PyMODINIT_FUNC PyInit__C(void)
{
return initModule();
}
// torch/csrc/Module.cpp
extern "C"
TORCH_API PyObject* initModule();
PyObject* initModule() {
THPUtils_addPyMethodDefs(methods, TorchMethods);
THPUtils_addPyMethodDefs(methods, torch::autograd::python_functions());
static struct PyModuleDef torchmodule = {PyModuleDef_HEAD_INIT, "torch._C", nullptr, -1, methods.data()};
ASSERT_TRUE(module = PyModule_Create(&torchmodule));
ASSERT_TRUE(THPGenerator_init(module));
ASSERT_TRUE(THPException_init(module));
THPSize_init(module);
THPDtype_init(module);
THPDTypeInfo_init(module);
THPLayout_init(module);
THPMemoryFormat_init(module);
THPQScheme_init(module);
THPDevice_init(module);
THPStream_init(module);
ASSERT_TRUE(THPVariable_initModule(module));
ASSERT_TRUE(THPFunction_initModule(module));
ASSERT_TRUE(THPEngine_initModule(module));
at::init();
return module;
}
function torch.tensor
torch.tensor(1.0)
pytorch 使用 PyMethodDef 暴露 python tensor, 对应类型 THPVariable_tensor.
// torch/csrc/autograd/python_torch_functions_manual.cpp
static PyMethodDef torch_functions_manual[] = {
{"tensor",
castPyCFunctionWithKeywords(THPVariable_tensor),
METH_VARARGS | METH_KEYWORDS | METH_STATIC,
nullptr},
}
// implemented on python object to allow torch.tensor to be constructed with
// arbitrarily nested python objects - list, tuple, np array, scalar, etc.
static PyObject* THPVariable_tensor( PyObject* self, PyObject* args, PyObject* kwargs) {
jit::tracer::warn("torch.tensor", jit::tracer::WARN_CONSTRUCTOR);
return THPVariable_Wrap(torch::utils::tensor_ctor(
torch::tensors::get_default_dispatch_key(),
torch::tensors::get_default_scalar_type(),
r));
}
- torch::utils::tensor_ctor() 返回 cpp tensor
- torch::tensors::get_default_dispatch_key() 获取默认 dispatch key
- torch::tensors::get_default_scalar_type() 获取默认数据类型
- THPVariable_Wrap 把 tensor 封装成 python 可使用的 THPVariable
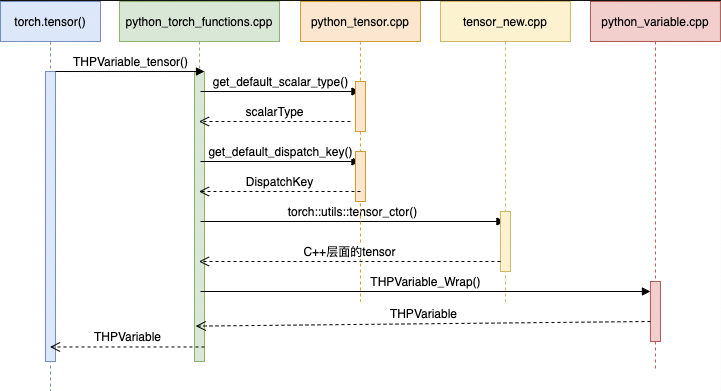
tensor_new
// torch/csrc/utils/tensor_new.cpp
Tensor tensor_ctor(
c10::DispatchKey dispatch_key,
at::ScalarType scalar_type,
PythonArgs& r) {
if (r.idx == 0) {
PyObject* data = r.pyobject(0);
bool type_inference = r.isNone(1);
bool pin_memory = r.toBool(3);
bool args_requires_grad = r.toBool(4);
auto new_tensor = internal_new_from_data(
typeIdWithDefault(r, 2, dispatch_key),
r.scalartypeWithDefault(1, scalar_type),
r.deviceOptional(2),
data,
/*copy_variables=*/true,
/*copy_numpy=*/true,
/*type_inference=*/type_inference,
pin_memory);
auto names = r.toDimnameListOptional(5);
if (names) {
at::namedinference::propagate_names(
new_tensor, *names, /*validate_names=*/true);
}
new_tensor.detach_(); // ensure new_tensor a leaf node
new_tensor.set_requires_grad(args_requires_grad);
return new_tensor;
}
}
- 解析参数
- 调用 internal_new_from_data 创建 cpp tensor,初始化 storage_
- new_tensor.detach_() 确保是叶子结点,初始化 autograd_meta_
internal_new_from_data
// torch/csrc/utils/tensor_new.cpp
Tensor internal_new_from_data(
c10::TensorOptions options,
at::ScalarType scalar_type,
c10::optional<Device> device_opt,
PyObject* data,
bool copy_variables,
bool copy_numpy,
bool type_inference,
bool pin_memory = false) {
if (THPVariable_Check(data)) {
auto var = THPVariable_Unpack(data);
return var.to(...);
}
if (PyObject_HasAttrString(data, "__cuda_array_interface__")) {
auto tensor = tensor_from_cuda_array_interface(data);
return tensor.to(...);
}
if (is_numpy_available() && PyArray_Check(data)) {
auto tensor = tensor_from_numpy(data, /*warn_if_not_writeable=*/!copy_numpy);
return tensor.to(...);
}
auto device = device_opt.has_value() ? *device_opt : options.device();
auto sizes = compute_sizes(data, scalar_type);
ScalarType inferred_scalar_type = type_inference ? infer_scalar_type(data) : scalar_type;
Tensor tensor;
{
{
if (isStorage(data)) {
Storage storage = createStorageGetType(data, storage_scalar_type, is_typed_storage);
tensor = at::empty( sizes,
at::initialTensorOptions().dtype( is_typed_storage ? storage_scalar_type : inferred_scalar_type)
.pinned_memory(pin_memory)
.device(storage.device()));
tensor.set_(storage);
} else {
TensorOptions opts = at::initialTensorOptions().dtype(inferred_scalar_type);
tensor = at::empty(sizes, opts.pinned_memory(pin_memory));
recursive_store(
(char*)tensor.data_ptr(),
tensor.sizes(),
tensor.strides(),
0,
inferred_scalar_type,
tensor.dtype().itemsize(),
data);
}
}
maybe_initialize_cuda(device);
tensor = tensor.to(device, inferred_scalar_type, /*non_blocking=*/false, /*copy=*/false);
}
return at::lift_fresh(tensor);
}
- at::empty() 创建 tensor
- recursive_store() 初始化 tensor 数据
其中 detach_ 调用会调用 materialize_autograd_meta 初始化 autograd_meta_.
// torch/csrc/autograd/variable.cpp
AutogradMeta* materialize_autograd_meta(const at::TensorBase& self) {
auto p = self.unsafeGetTensorImpl();
if (!p->autograd_meta()) {
p->set_autograd_meta(std::make_unique<AutogradMeta>());
}
return get_autograd_meta(self);
}
THPVariable_Wrap
// torch/csrc/autograd/python_variable.cpp
PyObject* THPVariable_Wrap(at::TensorBase var) {
return THPVariable_NewWithVar( (PyTypeObject*)THPVariableClass, std::move(var), status);
}
static PyObject* THPVariable_NewWithVar(PyTypeObject* type, Variable _var, c10::impl::PyInterpreterStatus status) {
PyObject* obj = type->tp_alloc(type, 0);
if (obj) {
auto v = (THPVariable*)obj;
}
return obj;
}
PyMethodDef
PyMethodDef including
- PyModuleDef
- PyInit_* and PyModule_Create
// torch/csrc/autograd/python_variable.cpp
bool THPVariable_initModule(PyObject* module) {
PyModule_AddObject(module, "_TensorMeta", (PyObject*)&THPVariableMetaType);
static std::vector<PyMethodDef> methods;
THPUtils_addPyMethodDefs(methods, torch::autograd::variable_methods);
THPUtils_addPyMethodDefs(methods, extra_methods);
THPVariableType.tp_methods = methods.data();
PyModule_AddObject(module, "_TensorBase", (PyObject*)&THPVariableType);
torch::autograd::initTorchFunctions(module);
torch::autograd::initTensorImplConversion(module);
return true;
}
initTorchFunctions
// torch/csrc/autograd/python_torch_functions_manual.cpp
namespace torch {
namespace autograd {
static PyTypeObject THPVariableFunctions = {
PyVarObject_HEAD_INIT(
nullptr,
0) "torch._C._VariableFunctionsClass", /* tp_name */
0, /* tp_basicsize */
...
}
void initTorchFunctions(PyObject* module) {
static std::vector<PyMethodDef> torch_functions;
gatherTorchFunctions(torch_functions);
THPVariableFunctions.tp_methods = torch_functions.data();
if (PyModule_AddObject(
module,
"_VariableFunctionsClass",
reinterpret_cast<PyObject*>(&THPVariableFunctions)) < 0) { }
THPVariableFunctionsModule =
PyType_GenericNew(&THPVariableFunctions, Py_None, Py_None);
if (PyModule_AddObject(
module, "_VariableFunctions", THPVariableFunctionsModule) < 0) { }
}
} // namespace autograd
} // namespace torch
checkout it out
torch.tensor
<built-in method tensor of type object at 0x7f72955df1a0>
torch._C._VariableFunctions.tensor
<built-in method tensor of type object at 0x7f72955df1a0>
torch._C._VariableFunctionsClass.__dict__['tensor']
<staticmethod object at 0x7f7296e30a10>
# torch/__init__.py
for name in dir(_C._VariableFunctions):
if name.startswith('__') or name in PRIVATE_OPS:
continue
obj = getattr(_C._VariableFunctions, name)
obj.__module__ = 'torch'
globals()[name] = obj
if not name.startswith("_"):
__all__.append(name)
gatherTorchFunctions 填充 torch_functions, 包括 tensor.
// torch/csrc/autograd/python_torch_functions_manual.cpp
void gatherTorchFunctions(std::vector<PyMethodDef>& torch_functions) {
constexpr size_t num_functions =
sizeof(torch_functions_manual) / sizeof(torch_functions_manual[0]);
torch_functions.assign(
torch_functions_manual, torch_functions_manual + num_functions);
gatherTorchFunctions_0(torch_functions);
gatherTorchFunctions_1(torch_functions);
gatherTorchFunctions_2(torch_functions);
static std::array<std::pair<const char*, const char*>, 4> aliases{
{// Canonical function, alias name
{"sspaddmm", "saddmm"},
{"mm", "spmm"},
{"mm", "dsmm"},
{"hspmm", "hsmm"}}};
for (const auto& alias : aliases) {
auto it = std::find_if(
torch_functions.begin(),
torch_functions.end(),
[&](const PyMethodDef& def) {
return strcmp(def.ml_name, alias.first) == 0;
});
TORCH_INTERNAL_ASSERT(
it != torch_functions.end(),
"Failed to create function alias from ",
alias.first,
" to ",
alias.second);
PyMethodDef alias_def = *it;
alias_def.ml_name = alias.second;
torch_functions.push_back(alias_def);
}
torch_functions.push_back({nullptr});
}
torch_functions.assign(torch_functions_manual, ...);
很多 functions 由
tools/autograd/gen_python_functions.py自动生成的文件torch/csrc/autograd/generated/python_torch_functions_0.cpp定义。文件中的这些 functions 由同文件中的函数gatherTorchFunctions_0添加到torch_functions从而添加进PyModuleDef.
# tools/autograd/gen_python_functions.py
# These functions require manual Python bindings or are not exposed to Python
_SKIP_PYTHON_BINDINGS = [
"tensor",
]
def gen( out: str, native_yaml_path: str, tags_yaml_path: str, deprecated_yaml_path: str, template_path: str, *, symint: bool = True,):
create_python_bindings( None, "python_variable_methods.cpp",)
create_python_bindings_sharded( "torch", "python_torch_functions.cpp",)
create_python_bindings( "torch.nn", "python_nn_functions.cpp",)
create_python_bindings( "torch.fft", "python_fft_functions.cpp",)
create_python_bindings( "torch.linalg", "python_linalg_functions.cpp",)
create_python_bindings( "torch.nested", "python_nested_functions.cpp",)
create_python_bindings( "torch.sparse", "python_sparse_functions.cpp",)
create_python_bindings( "torch.special", "python_special_functions.cpp",)
create_python_return_type_bindings( fm, functions, lambda fn: True, "python_return_types.cpp")
class torch.Tensor
What's behind torch.Tensor ?
From py to cpp
# torch/__init__.py
from ._tensor import Tensor
python Tensor 都继承自 torch._C._TensorBase
# torch/_tensor.py
class Tensor(torch._C._TensorBase):
def __deepcopy__(self, memo):
...
def storage(self):
return self._typed_storage()
def backward(self, gradient=None, retain_graph=None, create_graph=False, inputs=None):
torch.autograd.backward(
self, gradient, retain_graph, create_graph, inputs=inputs
)
def register_hook(self, hook):
return handle
...
python 的 torch._C._TensorBase 绑定在 cpp THPVariableType 上
// torch/csrc/autograd/python_variable.cpp
bool THPVariable_initModule(PyObject *module)
{
THPVariableMetaType.tp_base = &PyType_Type;
if (PyType_Ready(&THPVariableMetaType) < 0)
return false;
Py_INCREF(&THPVariableMetaType);
PyModule_AddObject(module, "_TensorMeta", (PyObject *)&THPVariableMetaType);
static std::vector<PyMethodDef> methods;
THPUtils_addPyMethodDefs(methods, torch::autograd::variable_methods);
THPUtils_addPyMethodDefs(methods, extra_methods);
THPVariableType.tp_methods = methods.data();
if (PyType_Ready(&THPVariableType) < 0)
return false;
Py_INCREF(&THPVariableType);
PyModule_AddObject(module, "_TensorBase", (PyObject *)&THPVariableType);
torch::autograd::initTorchFunctions(module);
torch::autograd::initTensorImplConversion(module);
return true;
}
PyTypeObject THPVariableType = {
PyVarObject_HEAD_INIT(
&THPVariableMetaType,
0) "torch._C._TensorBase", /* tp_name */
sizeof(THPVariable), /* tp_basicsize */
0, /* tp_itemsize */
...
THPVariable_pynew, /* tp_new */
};
PyTypeObject THPVariableMetaType = {
PyVarObject_HEAD_INIT(DEFERRED_ADDRESS(&PyType_Type), 0)
"torch._C._TensorMeta", /* tp_name */
sizeof(THPVariableMeta),
...
THPVariableMetaType_init, /* tp_init */
nullptr, /* tp_alloc */
nullptr, /* tp_new */
};
// torch/csrc/autograd/python_variable.h
// Python object that backs torch.autograd.Variable
struct THPVariable {
PyObject_HEAD;
// Payload
c10::MaybeOwned<at::Tensor> cdata;
// Hooks to be run on backwards pass (corresponds to Python attr
// '_backwards_hooks', set by 'register_hook')
PyObject* backward_hooks = nullptr;
};
// torch/csrc/autograd/function_hook.h
namespace torch { namespace autograd {
using Variable = at::Tensor;
using variable_list = std::vector<Variable>;
} }
TensorBase and Tensor
TensorBase
Tensor 继承自 TensorBase, TensorBase 不依赖 function 自动生成,使用 TensorBase 可以避免自动生成部分有改动时全量编译,其次是引用计数问题。
// aten/src/ATen/core/TensorBase.h
// Convert Tensor to TensorBase without any need to include Tensor.h
TORCH_API const TensorBase& get_tensor_base(const Tensor& t);
// NOTE: [Tensor vs. TensorBase]
//
// Tensor, being the central data structure in PyTorch, gets used and
// it's header included almost everywhere. Unfortunately this means
// every time an operator signature is updated or changed in
// native_functions.yaml, you (and every other PyTorch developer) need
// to recompile all of ATen and it's dependencies.
//
// TensorBase aims to break up these header dependencies, and improve
// incremental build times for all PyTorch developers. TensorBase
// represents a reference counted handle to TensorImpl, exactly the
// same as Tensor. However, TensorBase doesn't have code generated
// methods in it's API and thus no dependence on native_functions.yaml.
//
// Usage tips
// ----------
// - You can `#define TORCH_ASSERT_NO_OPERATORS` at the top of a .cpp
// or .cu file to ensure it has no header dependencies on
// native_functions.yaml (direct or indirect).
// - Tensor inherits from TensorBase, so functions taking
// `const TensorBase &` are callable with Tensor as well.
// - TensorBase can be converted to tensor with `Tensor(tensor_base)`,
// but this requires a reference-count bump. OptionalTensorRef on
// the other hand can materialize a `const Tensor &` without
// touching the reference-count.
class TORCH_API TensorBase {
public:
const c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>& getIntrusivePtr() const {
return impl_;
}
c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl> unsafeReleaseIntrusivePtr() {
return std::move(impl_);
}
DispatchKeySet key_set() const {
return impl_->key_set();
}
ScalarType scalar_type() const {
return typeMetaToScalarType(impl_->dtype());
}
const Storage& storage() const {
return impl_->storage();
}
Layout layout() const noexcept {
return impl_->layout();
}
caffe2::TypeMeta dtype() const noexcept {
return impl_->dtype();
}
inline Device device() const {
return impl_->device();
}
int64_t get_device() const {
// NB: this is not a native function to avoid dispatching overhead.
return impl_->get_device();
}
TensorOptions options() const {
return TensorOptions().dtype(dtype())
.device(device())
.layout(layout());
}
void* data_ptr() const {
return this->unsafeGetTensorImpl()->data();
}
template <typename T>
T * data_ptr() const;
at::TensorBase tensor_data() const;
at::TensorBase variable_data() const;
const std::shared_ptr<torch::autograd::Node>& grad_fn() const;
protected:
c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl> impl_;
};
Tensor API
// torch/include/ATen/core/TensorBody.h
// aten/src/ATen/templates/TensorBody.h
// Tensor is a "generic" object holding a pointer to the underlying TensorImpl object, which has an embedded reference count.
// similar to boost::intrusive_ptr.
class TORCH_API Tensor: public TensorBase {
protected:
friend MaybeOwnedTraits<Tensor>;
friend OptionalTensorRef;
public:
explicit Tensor(
c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl> tensor_impl)
: TensorBase(std::move(tensor_impl)) {}
Tensor(const Tensor &tensor) = default;
Tensor(Tensor &&tensor) = default;
explicit Tensor(const TensorBase &base): TensorBase(base) {}
c10::MaybeOwned<Tensor> expect_contiguous(MemoryFormat memory_format=MemoryFormat::Contiguous) const &;
c10::MaybeOwned<Tensor> expect_contiguous(MemoryFormat memory_format=MemoryFormat::Contiguous) && = delete;
Tensor& operator=(const TensorBase& x) & {
impl_ = x.getIntrusivePtr();
return *this;
}
Tensor& operator=(TensorBase&& x) & { }
Tensor& operator=(const Tensor &x) & { }
Tensor& operator=(Tensor &&x) & { }
Tensor& operator=(Scalar v) && { }
Tensor& operator=(const Tensor &rhs) && { }
Tensor& operator=(Tensor&& rhs) && { }
void backward(const Tensor & gradient={}, c10::optional<bool> retain_graph=c10::nullopt, bool create_graph=false, c10::optional<TensorList> inputs=c10::nullopt) const { }
Tensor data() const {
return TensorBase::data();
}
}
Tensor 的继承关系
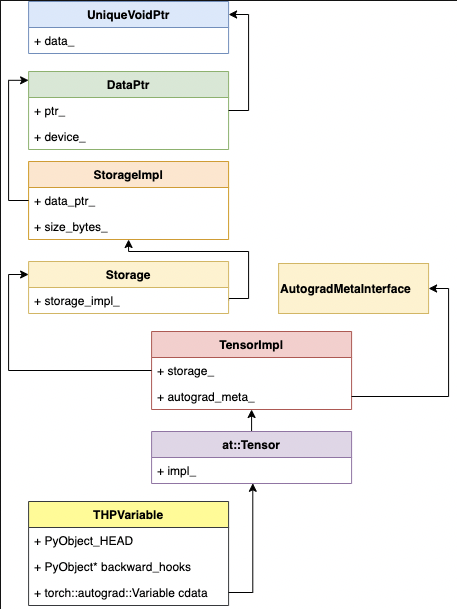
at:Tensor 本质是 Tensor 的 API,底层是 TensorImpl
// c10/core/TensorImpl.h
/**
* The low-level representation of a tensor, which contains a pointer
* to a storage (which contains the actual data) and metadata (e.g., sizes and
* strides) describing this particular view of the data as a tensor.
*
*/
struct C10_API TensorImpl : public c10::intrusive_ptr_target {
enum ImplType { VIEW };
public:
virtual IntArrayRef strides() const;
TENSORIMPL_MAYBE_VIRTUAL const Storage& storage() const {
return storage_;
}
Device device() const {
return *device_opt_;
}
Layout layout() const {
// This keyset must also be kept in sync with the logic in
// is_sparse() / is_sparse_csr() / is_mkldnn()
constexpr auto sparse_and_sparsecsr_and_mkldnn_ks =
c10::sparse_ks | c10::sparse_csr_ks | c10::mkldnn_ks;
...
}
Storage storage_;
inline T* data() const {
return data_ptr_impl<T>();
}
inline T* data_ptr_impl() const {
return storage_.unsafe_data<T>() + storage_offset_;
}
inline void* data() const {
return static_cast<void*>(
static_cast<char*>(storage_.data()) +
data_type_.itemsize() * storage_offset_);
}
const caffe2::TypeMeta dtype() const {
return data_type_;
}
DeviceType device_type() const {
return (*device_opt_).type();
}
private:
// This pointer points to an AutogradMeta struct that stores autograd-specific
// fields (such as grad_ / grad_fn_ / grad_accumulator_). This pointer always
// has unique ownership (meaning only one TensorImpl can own it at a time).
//
std::unique_ptr<c10::AutogradMetaInterface> autograd_meta_ = nullptr;
protected:
std::unique_ptr<c10::NamedTensorMetaInterface> named_tensor_meta_ = nullptr;
c10::VariableVersion version_counter_;
PyObject* pyobj_;
c10::impl::SizesAndStrides sizes_and_strides_;
caffe2::TypeMeta data_type_;
c10::optional<c10::Device> device_opt_;
const at::Tensor& grad() const;
}
Storage
// c10/core/Storage.h
struct C10_API Storage {
void* data() const {
return storage_impl_.get()->data();
}
at::DataPtr& data_ptr() {
return storage_impl_->data_ptr();
}
const at::DataPtr& data_ptr() const {
return storage_impl_->data_ptr();
}
protected:
c10::intrusive_ptr<StorageImpl> storage_impl_;
};
StorageImpl
// c10/core/StorageImpl.h
struct C10_API StorageImpl : public c10::intrusive_ptr_target {
private:
DataPtr data_ptr_;
size_t size_bytes_;
bool resizable_;
bool received_cuda_;
Allocator* allocator_;
}
// c10/core/Allocator.h
class C10_API DataPtr {
private:
c10::detail::UniqueVoidPtr ptr_;
Device device_;
}
UniqueVoidPtr
// c10/util/UniqueVoidPtr.h
namespace c10 {
using DeleterFnPtr = void (*)(void*);
namespace detail {
class UniqueVoidPtr {
private:
void* data_;
std::unique_ptr<void, DeleterFnPtr> ctx_;
}
} }
detail::UniqueVoidPtr is an owning smart pointer like unique_ptr
- specialized to void
- specialized for a function pointer deleter
void(void* ctx) - deleter is guaranteed to be called when the unique pointer is destructed and the context is non-null
Why this ?
>>> torch.Tensor(1)
tensor([6.7871e-27])
>>> torch.Tensor(1.0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new(): data must be a sequence (got float)
// torch/csrc/autograd/python_variable.cpp
PyObject* THPVariable_pynew(
PyTypeObject* type,
PyObject* args,
PyObject* kwargs) {
TORCH_CHECK(
type != &THPVariableType,
"Cannot directly construct _TensorBase; subclass it and then construct that");
auto tensor = torch::utils::base_tensor_ctor(args, kwargs);
return THPVariable_NewWithVar(
type,
std::move(tensor),
c10::impl::PyInterpreterStatus::MAYBE_UNINITIALIZED);
}
// torch/csrc/utils/tensor_new.cpp
Tensor base_tensor_ctor(PyObject* args, PyObject* kwargs) {
return legacy_tensor_generic_ctor_new(
torch::tensors::get_default_dispatch_key(),
torch::tensors::get_default_scalar_type(),
args,
kwargs,
CtorOrNew::BASE_CTOR);
}
Tensor legacy_tensor_generic_ctor_new(
c10::DispatchKey dispatch_key,
at::ScalarType scalar_type,
PyObject* args,
PyObject* kwargs,
CtorOrNew ctor_or_new) {
auto options = dispatchKeyToTensorOptions(dispatch_key);
static PythonArgParser parser({
"new(*, Device? device=None)",
"new(Storage storage)",
"new(*, int64_t cdata)|hidden",
// This constructor is no longer legacy, it will also be usable for
// subclass initialization
"new(Tensor other)",
"new(Tensor other, *, Device? device=None)|hidden", // prevent Tensor
// matching with
// IntArrayRef,
// PyObject*
"new(IntArrayRef size, *, Device? device=None)",
"new(PyObject* data, *, Device? device=None)",
});
if (isSparse(dispatchKeyToBackend(dispatch_key))) {
return legacy_sparse_tensor_generic_ctor_new(
dispatch_key, scalar_type, args, kwargs, ctor_or_new);
}
if (ctor_or_new == CtorOrNew::NEW)
check_base_legacy_new(dispatch_key, c10::kStrided);
ParsedArgs<2> parsed_args;
auto r = parser.parse(args, kwargs, parsed_args);
if (r.idx == 0) {
auto deviceOptional = r.deviceOptional(0);
check_legacy_ctor_device(dispatch_key, deviceOptional);
at::OptionalDeviceGuard device_guard(deviceOptional);
return at::empty({0}, build_options(options, scalar_type));
} else if (r.idx == 1) {
at::ScalarType storage_scalar_type;
bool is_typed_storage = false;
at::Storage storage = r.storage(0, storage_scalar_type, is_typed_storage);
if (storage_scalar_type != at::ScalarType::Undefined && is_typed_storage) {
TORCH_CHECK(
storage_scalar_type == scalar_type,
"Expected a Storage of type ",
scalar_type,
" or an UntypedStorage, but got type ",
storage_scalar_type,
" for argument 1 'storage'");
}
return new_with_storage(options, scalar_type, storage);
} else if (r.idx == 2) {
auto cdata = reinterpret_cast<void*>(r.toInt64(0));
return at::unsafeTensorFromTH(cdata, true);
} else if (r.idx == 3) {
const auto& other = r.tensor(0);
// BASE_CTOR (aka torch.Tensor) is now relaxed to accept any
// dtype; previously it was "float" biased
if (ctor_or_new != CtorOrNew::BASE_CTOR) {
options = options.dtype(scalar_type);
TORCH_CHECK_TYPE(
other.options().type_equal(options),
"expected ",
options,
" (got ",
other.options(),
")");
}
return other.alias();
} else if (r.idx == 4) {
if (ctor_or_new == CtorOrNew::CTOR || ctor_or_new == CtorOrNew::BASE_CTOR) {
TORCH_CHECK(
false,
"Legacy tensor constructor of the form torch.Tensor(tensor, device=device) "
"is not supported. Use torch.tensor(...) or torch.as_tensor(...) instead.");
} else {
TORCH_CHECK(
false,
"Legacy tensor new of the form tensor.new(tensor, device=device) "
"is not supported. Use torch.as_tensor(...) instead.");
}
} else if (r.idx == 5) {
PyObject* arg = r.pyobject(0);
auto deviceOptional = r.deviceOptional(1);
check_legacy_ctor_device(dispatch_key, deviceOptional);
if (!THPSize_Check(arg) && PyTuple_GET_SIZE(args) >= 1 &&
arg == PyTuple_GET_ITEM(args, 0)) {
// new(sequence) binds to this signature but should be treated differently
// unless the sequences is a torch.Size
return legacy_new_from_sequence(
options, scalar_type, deviceOptional, r.pyobject(0));
}
return new_with_sizes(
options, scalar_type, r.deviceOptional(1), r.intlist(0));
} else if (r.idx == 6) {
auto deviceOptional = r.deviceOptional(1);
check_legacy_ctor_device(dispatch_key, deviceOptional);
return legacy_new_from_sequence(
options, scalar_type, deviceOptional, r.pyobject(0));
}
throw std::runtime_error("new(): invalid arguments");
}
PyTorch Tensor 相关主要数据结构和关系
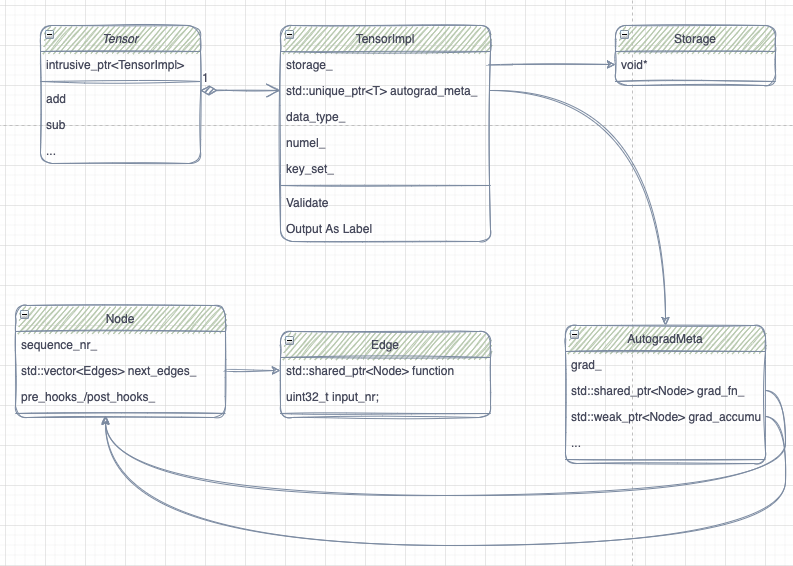
Tensor API dependency
The dependency of tensor related API
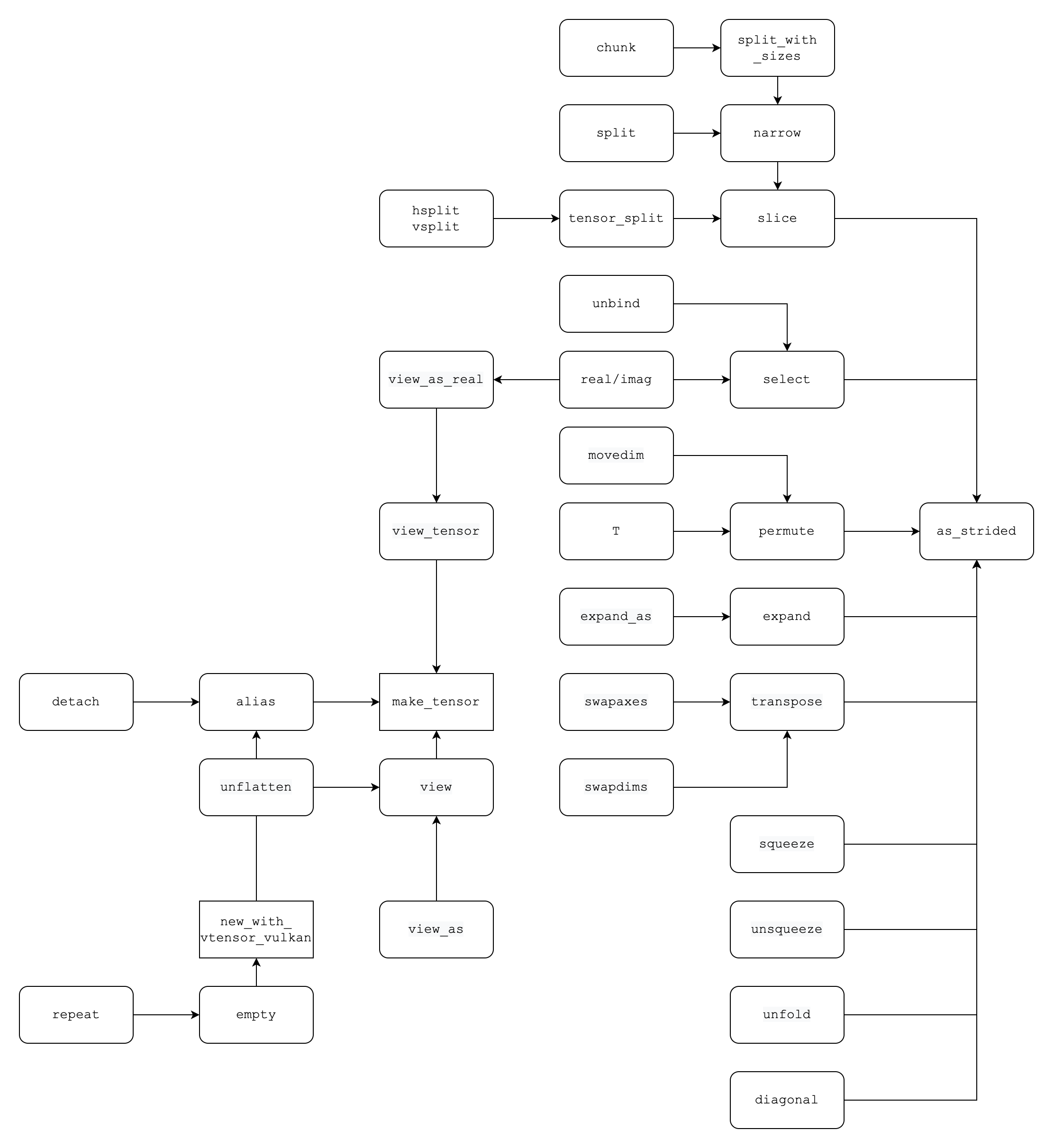
View
Tensor view explication
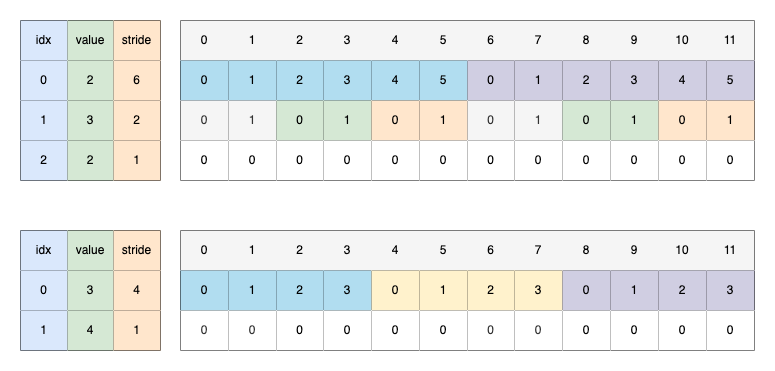
Autograd
// torch/csrc/autograd/variable.h
struct TORCH_API AutogradMeta : public c10::AutogradMetaInterface {
std::string name_;
Variable grad_;
std::shared_ptr<Node> grad_fn_;
std::weak_ptr<Node> grad_accumulator_;
std::shared_ptr<ForwardGrad> fw_grad_;
std::vector<std::shared_ptr<FunctionPreHook>> hooks_;
std::shared_ptr<hooks_list> cpp_hooks_list_;
}
AutogradMeta 中包含 autograd 所需的元素
- grad_: Tensor 对应的 grad
- grad_fn_: 反向 op
- grad_accumulator_: 反向梯度累加器,Node 类型
- cpp_hooks_list_, hooks_: 反向调用时的 hook
Node
Node
- The most important method on
Nodeis the call operator, which takes in a list of variables and produces a list of variables. - The precise size of these lists can be determined with
num_inputs()andnum_outputs(). Nodes are stitched together via theirnext_edgeinterface, which let you manipulate the set of outgoing edges of aNode.- You can add an edge with
add_next_edge(), retrieve an edge withnext_edge(index)and iterate over them via thenext_edges()method.
// torch/csrc/autograd/function.h
using edge_list = std::vector<Edge>;
struct TORCH_API Node : std::enable_shared_from_this<Node> {
public:
explicit Node(
uint64_t sequence_nr,
edge_list&& next_edges = edge_list())
: sequence_nr_(sequence_nr),
next_edges_(std::move(next_edges)) {
for (const Edge& edge: next_edges_) {
update_topological_nr(edge);
}
}
variable_list operator()(variable_list&& inputs) {
...
return apply(std::move(inputs));
}
void update_topological_nr(const Edge& edge) {
Node* node = edge.function.get();
if (node) {
auto topo_nr = node->topological_nr();
if (topological_nr_ <= topo_nr) {
topological_nr_ = topo_nr + 1;
}
}
}
void set_next_edge(size_t index, Edge edge) {
update_topological_nr(edge);
next_edges_[index] = std::move(edge);
}
void add_next_edge(Edge edge) {
update_topological_nr(edge);
next_edges_.push_back(std::move(edge));
}
void set_next_edges(edge_list&& next_edges) {
next_edges_ = std::move(next_edges);
for (const auto& next_edge : next_edges_) {
update_topological_nr(next_edge);
}
}
const Edge& next_edge(size_t index) const noexcept {
return next_edges_[index];
}
const edge_list& next_edges() const noexcept {
return next_edges_;
}
edge_list& next_edges() noexcept {
return next_edges_;
}
protected:
virtual variable_list apply(variable_list&& inputs) = 0;
const uint64_t sequence_nr_;
uint64_t topological_nr_ = 0;
uint64_t thread_id_ = 0;
edge_list next_edges_;
std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_;
std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_;
at::SmallVector<InputMetadata, 2> input_metadata_;
};
可以看到
- Node 的创建由 Edge 来完成,Node 中保存了连接情况和需要执行的方法。
- Node 本身是 callable object, 通过虚函数 apply 被子类重载实现。
- set_next_edge 方法可以添加 Edge
Edge
// torch/csrc/autograd/edge.h
struct Edge {
Edge() noexcept : function(nullptr), input_nr(0) {}
Edge(std::shared_ptr<Node> function_, uint32_t input_nr_) noexcept
: function(std::move(function_)), input_nr(input_nr_) {}
// Required for use in associative containers.
bool operator==(const Edge& other) const noexcept {
return this->function == other.function && this->input_nr == other.input_nr;
}
bool operator!=(const Edge& other) const noexcept {
return !(*this == other);
}
/// The function this `Edge` points to.
std::shared_ptr<Node> function;
/// The identifier of a particular input to the function.
uint32_t input_nr;
};
网络构建
先看简单的例子,
import torch
a = torch.tensor(1.0, requires_grad=True)
b = torch.tensor(2.0, requires_grad=True)
c = torch.add(a, b)
d = torch.mul(a, c)
d.backward()
print(f"a grad:{a.grad} grad_fn:{a.grad_fn}")
print(f"b grad:{b.grad} grad_fn:{b.grad_fn}")
print(f"c grad:{c.grad} grad_fn:{c.grad_fn}")
print(f"d grad:{d.grad} grad_fn:{d.grad_fn}")
'''
a grad:4.0 grad_fn:None
b grad:1.0 grad_fn:None
c grad:None grad_fn:<AddBackward0 object at 0x7f6862dc76d0>
d grad:None grad_fn:<MulBackward0 object at 0x7f6862dc76d0>
'''
以上代码构建的网络如图所示
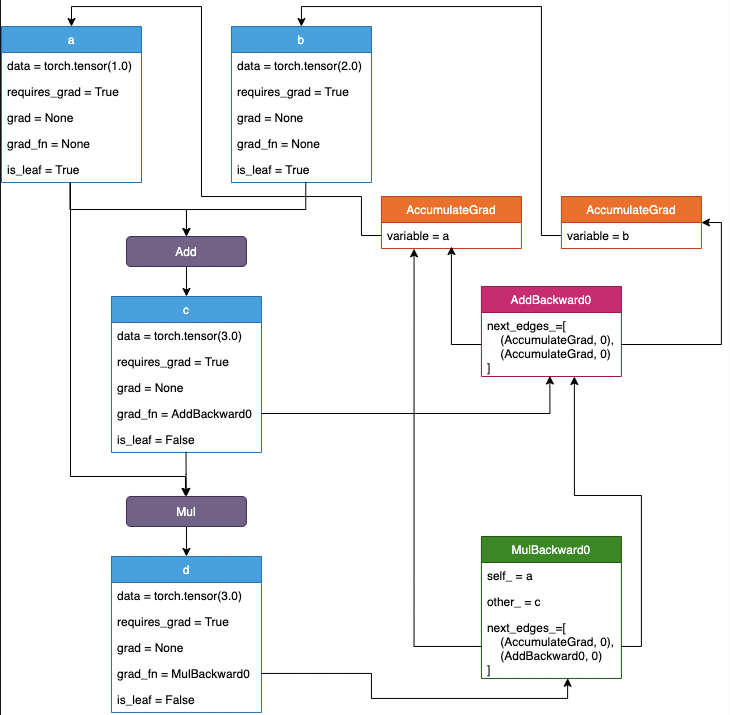
下面解析详细构建过程.
torch.add
torch/csrc/autograd/generated/ 目录需要 build 生成
// torch/csrc/autograd/generated/VariableType_2.cpp
// @generated by torchgen/gen.py from VariableType.cpp
at::Tensor add_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) {
auto& self_ = unpack(self, "self", 0);
auto& other_ = unpack(other, "other", 1);
auto _any_requires_grad = compute_requires_grad( self, other );
(void)_any_requires_grad;
auto _any_has_forward_grad_result = (isFwGradDefined(self) || isFwGradDefined(other));
(void)_any_has_forward_grad_result;
std::shared_ptr<AddBackward0> grad_fn;
if (_any_requires_grad) {
grad_fn = std::shared_ptr<AddBackward0>(new AddBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
grad_fn->other_scalar_type = other.scalar_type();
grad_fn->alpha = alpha;
grad_fn->self_scalar_type = self.scalar_type();
}
auto _tmp = ([&]() {
at::AutoDispatchBelowADInplaceOrView guard;
return at::redispatch::add(ks & c10::after_autograd_keyset, self_, other_, alpha);
})();
auto result = std::move(_tmp);
if (grad_fn) {
set_history(flatten_tensor_args( result ), grad_fn);
}
return result;
}
- 构建反向节点 AddBackward0
- 计算 at::redispatch::add,结果保存至 result
- 关联 AddBackward0 和 result
首先计算逻辑 add 的调用是自动生成的
// torch/include/ATen/RedispatchFunctions.h
// @generated by torchgen/gen.py from RedispatchFunctions.h
namespace at {
namespace redispatch {
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
inline at::Tensor add(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha=1) {
return at::_ops::add_Tensor::redispatch(dispatchKeySet, self, other, alpha);
}
}
}
具体实现 kernel 如下
// torch/include/ATen/ops/add_ops.h
// @generated by torchgen/gen.py from Operator.h
namespace at {
namespace _ops {
struct TORCH_API add_Tensor {
using schema = at::Tensor (const at::Tensor &, const at::Tensor &, const at::Scalar &);
using ptr_schema = schema*;
// See Note [static constexpr char* members for windows NVCC]
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(name, "aten::add")
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(overload_name, "Tensor")
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(schema_str, "add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor")
static at::Tensor call(const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha);
static at::Tensor redispatch(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha);
};
C API 入口
// torch/include/ATen/core/TensorBody.h
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
inline at::Tensor Tensor::add(const at::Tensor & other, const at::Scalar & alpha) const {
return at::_ops::add_Tensor::call(const_cast<Tensor&>(*this), other, alpha);
}
// aten::add_.Tensor(Tensor(a!) self, Tensor other, *, Scalar alpha=1) -> Tensor(a!)
inline at::Tensor & Tensor::add_(const at::Tensor & other, const at::Scalar & alpha) const {
return at::_ops::add__Tensor::call(const_cast<Tensor&>(*this), other, alpha);
}
AddBackward0
// torch/csrc/autograd/generated/Functions.h
// @generated from ../tools/autograd/templates/Functions.h
struct TORCH_API AddBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "AddBackward0"; }
void release_variables() override { }
at::ScalarType other_scalar_type;
at::Scalar alpha;
at::ScalarType self_scalar_type;
};
TraceableFunction
// torch/csrc/autograd/function.h
struct TraceableFunction : public Node {
using Node::Node;
bool is_traceable() final {
return true;
}
};
collect_next_edges 根据两个输入找到节点的 Edges
// torch/csrc/autograd/function.h
/// Return the next edges of all the given variables, or tuples of variables.
template <typename... Variables>
edge_list collect_next_edges(Variables&&... variables) {
detail::MakeNextFunctionList make;
make.apply(std::forward<Variables>(variables)...);
return std::move(make.next_edges);
}
struct MakeNextFunctionList : IterArgs<MakeNextFunctionList> {
edge_list next_edges;
using IterArgs<MakeNextFunctionList>::operator();
void operator()(const Variable& variable) {
if (variable.defined()) {
next_edges.push_back(impl::gradient_edge(variable));
} else {
next_edges.emplace_back();
}
}
void operator()(const Variable* variable) { ... }
void operator()(const c10::optional<Variable>& variable) { ... }
};
gradient_edge 会返回一组 Edges
// torch/csrc/autograd/variable.cpp
Edge gradient_edge(const Variable& self) {
if (const auto& gradient = self.grad_fn()) {
return Edge(gradient, self.output_nr());
} else {
return Edge(grad_accumulator(self), 0);
}
}
如果 self 是内部创建的(非叶子结点),即通过运算生成的,则返回 self 的 grad_fn 数据成员,否则(即用户创建的叶子结点)返回 AccumulateGrad 实例。
// torch/csrc/autograd/variable.cpp
std::shared_ptr<Node> grad_accumulator(const Variable& self) {
auto autograd_meta = get_autograd_meta(self);
c10::raw::intrusive_ptr::incref(self.unsafeGetTensorImpl());
auto intrusive_from_this =
c10::intrusive_ptr<at::TensorImpl>::reclaim(self.unsafeGetTensorImpl());
result = std::make_shared<AccumulateGrad>(
Variable(std::move(intrusive_from_this)));
autograd_meta->grad_accumulator_ = result;
return result;
}
其中 AcculateGrad 中的 Variable 即 aten::Tensor 指向 self 的 TensorImpl 用于更新聚合梯度:
// torch/csrc/autograd/functions/accumulate_grad.h
struct TORCH_API AccumulateGrad : public Node {
explicit AccumulateGrad(Variable variable_);
variable_list apply(variable_list&& grads) override;
Variable variable;
};
set_history
// torch/csrc/autograd/functions/utils.h
inline void set_history(
at::Tensor& variable,
const std::shared_ptr<Node>& grad_fn) {
AT_ASSERT(grad_fn);
if (variable.defined()) {
auto output_nr = grad_fn->add_input_metadata(variable);
impl::set_gradient_edge(variable, {grad_fn, output_nr});
} else {
grad_fn->add_input_metadata(Node::undefined_input());
}
}
inline void set_history(
std::vector<Variable>&& variables,
const std::shared_ptr<Node>& grad_fn) {
for (auto& variable : variables) {
set_history(variable, grad_fn);
}
}
set_gradient_edge 设置 Tensor 和 grad_fn_.
// torch/csrc/autograd/variable.cpp
void set_gradient_edge(const Variable& self, Edge edge) {
auto* meta = materialize_autograd_meta(self);
meta->grad_fn_ = std::move(edge.function);
meta->output_nr_ = edge.input_nr;
auto diff_view_meta = get_view_autograd_meta(self);
if (diff_view_meta && diff_view_meta->has_bw_view()) {
diff_view_meta->set_attr_version(self._version());
}
}
// torch/csrc/autograd/generated/python_variable_methods.cpp
static PyObject * THPVariable_add(PyObject* self_, PyObject* args, PyObject* kwargs)
{
const Tensor& self = THPVariable_Unpack(self_);
static PythonArgParser parser({
"add(Scalar alpha, Tensor other)|deprecated",
"add(Tensor other, *, Scalar alpha=1)",
}, /*traceable=*/true);
ParsedArgs<2> parsed_args;
auto _r = parser.parse(self_, args, kwargs, parsed_args);
if(_r.has_torch_function()) {
return handle_torch_function(_r, self_, args, kwargs, THPVariableClass, "torch.Tensor");
}
switch (_r.idx) {
case 0: {
// [deprecated] aten::add(Tensor self, Scalar alpha, Tensor other) -> Tensor
auto dispatch_add = [](const at::Tensor & self, const at::Scalar & alpha, const at::Tensor & other) -> at::Tensor {
pybind11::gil_scoped_release no_gil;
return self.add(other, alpha);
};
return wrap(dispatch_add(self, _r.scalar(0), _r.tensor(1)));
}
case 1: {
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
auto dispatch_add = [](const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) -> at::Tensor {
pybind11::gil_scoped_release no_gil;
return self.add(other, alpha);
};
return wrap(dispatch_add(self, _r.tensor(0), _r.scalar(1)));
}
}
}
// aten/src/ATen/core/dispatch/Dispatcher.h
// See [Note: Argument forwarding in the dispatcher] for why Args doesn't use &&
template<class Return, class... Args>
inline Return Dispatcher::redispatch(const TypedOperatorHandle<Return (Args...)>& op, DispatchKeySet currentDispatchKeySet, Args... args) const {
detail::unused_arg_(args...); // workaround for a false-positive warning about unused parameters in gcc 5
// do not use RecordFunction on redispatch
#ifndef NDEBUG
DispatchTraceNestingGuard debug_guard;
if (show_dispatch_trace()) {
auto nesting_value = dispatch_trace_nesting_value();
for (int64_t i = 0; i < nesting_value; ++i) std::cerr << " ";
std::cerr << "[redispatch] op=[" << op.operator_name() << "], key=[" << toString(currentDispatchKeySet.highestPriorityTypeId()) << "]" << std::endl;
}
#endif
const KernelFunction& kernel = op.operatorDef_->op.lookup(currentDispatchKeySet);
return kernel.template call<Return, Args...>(op, currentDispatchKeySet, std::forward<Args>(args)...);
}
// aten/src/ATen/native/BinaryOps.cpp
Tensor add(const Tensor& self, const Scalar& other, const Scalar& alpha) {
return at::add(self, wrapped_scalar_tensor(other), alpha);
}
Tensor& add_(Tensor& self, const Scalar& other, const Scalar& alpha) {
return self.add_(wrapped_scalar_tensor(other), alpha);
}
torch.mul
流程类似
// torch/csrc/autograd/generated/VariableType_0.cpp
at::Tensor mul_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other) {
auto& self_ = unpack(self, "self", 0);
auto& other_ = unpack(other, "other", 1);
auto _any_requires_grad = compute_requires_grad( self, other );
(void)_any_requires_grad;
auto _any_has_forward_grad_result = (isFwGradDefined(self) || isFwGradDefined(other));
(void)_any_has_forward_grad_result;
std::shared_ptr<MulBackward0> grad_fn;
if (_any_requires_grad) {
grad_fn = std::shared_ptr<MulBackward0>(new MulBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
if (grad_fn->should_compute_output(1)) {
grad_fn->self_ = SavedVariable(self, false);
}
grad_fn->other_scalar_type = other.scalar_type();
grad_fn->self_scalar_type = self.scalar_type();
if (grad_fn->should_compute_output(0)) {
grad_fn->other_ = SavedVariable(other, false);
}
}
auto _tmp = ([&]() {
at::AutoDispatchBelowADInplaceOrView guard;
return at::redispatch::mul(ks & c10::after_autograd_keyset, self_, other_);
})();
auto result = std::move(_tmp);
if (grad_fn) {
set_history(flatten_tensor_args( result ), grad_fn);
}
if (result_new_fw_grad_opt.has_value() && result_new_fw_grad_opt.value().defined() && result.defined()) {
// The hardcoded 0 here will need to be updated once we support multiple levels.
result._set_fw_grad(result_new_fw_grad_opt.value(), /* level */ 0, /* is_inplace_op */ false);
}
return result;
}
不同是的是因为乘法的求导和输入有关,所以我们在构建 MulBackward0 的时候需要把输入保存下来,即代码中的 SavedVariable 用于保存实例.
// torch/csrc/autograd/generated/Functions.h
struct TORCH_API MulBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "MulBackward0"; }
void release_variables() override {
std::lock_guard<std::mutex> lock(mutex_);
self_.reset_data();
other_.reset_data();
}
SavedVariable self_;
at::ScalarType other_scalar_type;
at::ScalarType self_scalar_type;
SavedVariable other_;
};
使用 SavedVariable 来保存前向 Var 的数据区而不影响其管理反向 Op 的生命周期:
// torch/csrc/autograd/saved_variable.h
class TORCH_API SavedVariable {
public:
/// Reconstructs the saved variable. Pass `saved_for` as the gradient
/// function if constructing the `SavedVariable` with it would have caused a
/// circular reference.
Variable unpack(std::shared_ptr<Node> saved_for = nullptr) const;
private:
at::Tensor data_;
std::shared_ptr<ForwardGrad> fw_grad_;
std::weak_ptr<Node> weak_grad_fn_;
c10::VariableVersion version_counter_;
uint32_t saved_version_ = 0;
uint32_t output_nr_ = 0;
bool was_default_constructed_ = true;
bool is_inplace_on_view_ = false;
bool saved_original_ = false;
bool is_leaf_ = false;
bool is_output_ = false;
std::unique_ptr<SavedVariableHooks> hooks_;
std::shared_ptr<Node> grad_fn_;
std::weak_ptr<Node> grad_accumulator_;
bool requires_grad_ = false;
};
Lifecycle
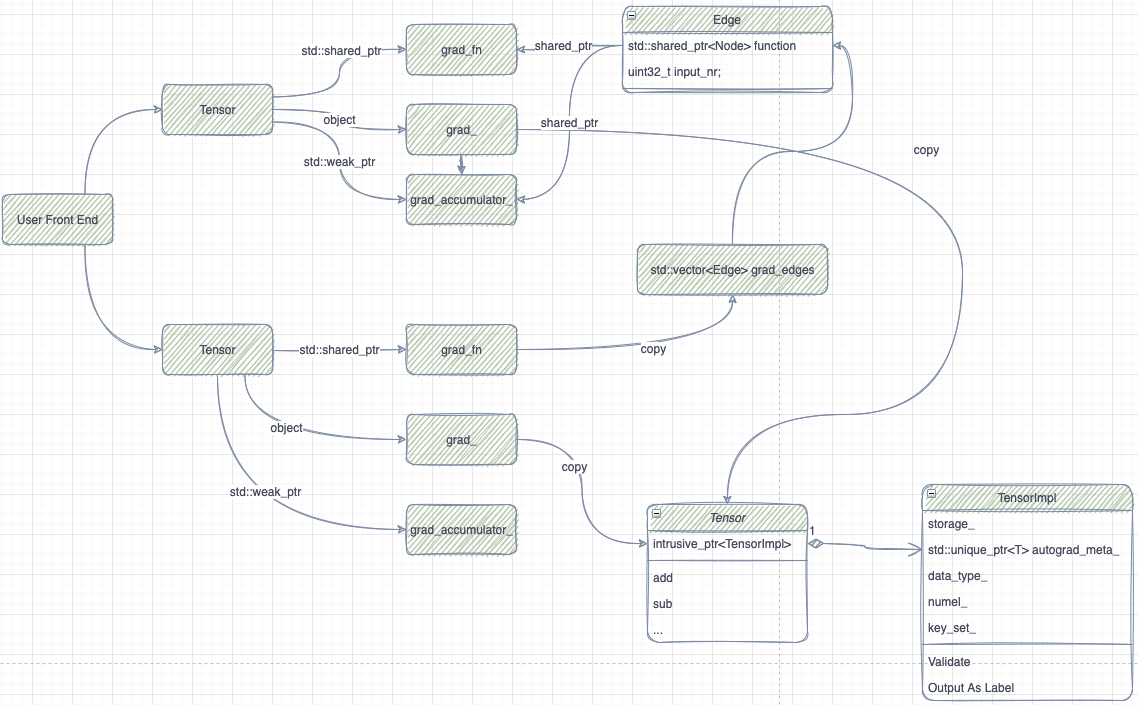
operator
以 add 为例
//
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
inline at::Tensor Tensor::add(const at::Tensor & other, const at::Scalar & alpha) const {
return at::_ops::add_Tensor::call(const_cast<Tensor&>(*this), other, alpha);
}
PyTorch Profiler
Overview
- PyTorch 功能相对齐全:
- 基础设计明确:profiler/benchmark/debug 信息分的很细,比如时间统计放 benchmark,前反向信息放 debug
- profiler 数据设计层次明确:打点日志 events --> 整理数据 key_averages --> 数据展示 table
- 数据展示部分:
- 控制台打印依赖整理数据的表格,通过控制各项 api 参数控制列,如统计设备/内存/flops 等等
- chrome tracing 使用保存的 json 文件,适用于 timeline 相关信息分析,同时支持元素详细信息展示,如tensor shape 等
- 数据展示能力的发挥在于利用了 tensorbord,提供多种视图,多种形式的数据展示形式
- 目前关于 model/layer 的支持仅限 torchscript 模式,还不完善,由 with_modules 参数控制
- Highlight: 信息展示中有根据 profiler 分析数据,给出优化建议
Demo
体现基本流程的示例
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
# 创建模型,需要 profile 的对象
model = models.resnet18()
inputs = torch.randn(5, 3, 224, 224)
# 配置
prof = profile(activities=[ProfilerActivity.CPU], record_shapes=True)
prof.start()
model(inputs)
prof.stop()
# 结果分析和输出
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10))
prof.export_chrome_trace("trace.json")
其中 torch.profiler.profile 可以使用 with 语法
with profile(activities=[ProfilerActivity.CPU], record_shapes=True) as prof:
with record_function("model_inference"):
model(inputs)
输出
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
model_inferencex 0.10% 15.353ms 100.00% 14.951s 14.951s 1
aten::batch_norm 0.00% 292.000us 43.14% 6.449s 322.464ms 20
aten::_batch_norm_impl_index 0.00% 567.000us 43.13% 6.449s 322.450ms 20
aten::native_batch_norm 32.92% 4.921s 43.13% 6.448s 322.419ms 20
aten::conv2d 0.00% 310.000us 42.00% 6.279s 313.938ms 20
aten::convolution 0.00% 350.000us 41.99% 6.278s 313.923ms 20
aten::_convolution 0.00% 601.000us 41.99% 6.278s 313.905ms 20
aten::mkldnn_convolution 41.98% 6.276s 41.99% 6.278s 313.875ms 20
aten::mean 0.01% 1.209ms 10.54% 1.576s 75.043ms 21
aten::sum 10.45% 1.562s 10.45% 1.562s 74.386ms 21
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 14.951s
API
torch.profiler.profile
参数说明
activitieslist 类型,profile 的内容,支持torch.profiler.ProfilerActivity.CPU和torch.profiler.ProfilerActivity.CUDA,这里的设置需要和模型使用的 device 一致schedule默认会持续记录所有事件,使用 scheduler() 作为帮助函数生成 schedule 函数,自定义记录逻辑on_trace_ready配合schedule使用,在它返回ProfilerAction.RECORD_AND_SAVE后被调用record_shapes是否记录 input shapesprofile_memory是否记录 内存/显存, 和activities对应with_stack是否开启调用文件信息源的记录,包括代码文件和行号with_flops预估FLOPs,主要针对 matrix multiplication and 2D convolutionwith_modules层级记录,暂时只针对 TorchScript
ProfilerAction 用于状态的记录和转换
class ProfilerAction(Enum):
NONE = 0
WARMUP = 1
RECORD = 2
RECORD_AND_SAVE = 3
profile 对象
# torch/profiler/profiler.py
# Profiler context manager
class profile(_KinetoProfile):
def __init__(...):
# 记录函数
self.step_rec_fn: Optional[prof.record_function] = None
# 状态转换时会触发一系列操作,action_map 记录里任意两个状态转换时执行的动作
self.action_map: Dict[Tuple[ProfilerAction, Optional[ProfilerAction]], List[Any]] = {
(ProfilerAction.NONE, ProfilerAction.WARMUP): [self.prepare_trace],
(ProfilerAction.NONE, ProfilerAction.RECORD): [self.prepare_trace, self.start_trace],
...
}
def start(self):
self._transit_action(ProfilerAction.NONE, self.current_action)
if self.record_steps:
self.step_rec_fn = prof.record_function("ProfilerStep#" + str(self.step_num))
self.step_rec_fn.__enter__()
def stop(self):
if self.record_steps and self.step_rec_fn:
self.step_rec_fn.__exit__(None, None, None)
self._transit_action(self.current_action, None)
def step(self):
self.step_num += 1
# schedule 接受 step 数,返回当前 action
self.current_action = self.schedule(self.step_num)
# 转换状态,触发 map 中定义的动作
self._transit_action(prev_action, self.current_action)
if self.record_steps:
self.step_rec_fn = prof.record_function("ProfilerStep#" + str(cur_step))
self.step_rec_fn.__enter__()
schedule
def schedule(*, wait: int, warmup: int, active: int, repeat: int = 0, skip_first: int = 0) -> Callable:
# skip_fist + ( wait + warmup + active ) * repeat
# NONE WARMUP RECORD RECORD_AND_SAVE
def schedule_fn(step: int) -> ProfilerAction:
# 根据 step 返回 当前的状态
return schedule_fn
record_function
# torch/autograd/profiler.py
class record_function(ContextDecorator):
def __init__(self, name: str, args: Optional[str] = None):
self.record = torch.jit.annotate(Optional["torch.classes.profiler._RecordFunction"], None)
def __enter__(self):
self.record = torch.ops.profiler._record_function_enter_new(self.name, self.args)
def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any):
torch.ops.profiler._record_function_exit(self.record)
Reference
Hook
Summary
| Hook | 触发时机 | API |
|---|---|---|
| 反向 hook | 反向梯度计算完成后 | register_hook(hook) |
| 前向 after hook | forward() 调用之后 | register_forward_hook(hook) |
| 前向 before hook | forward() 调用之前 | register_forward_pre_hook(hook) |
| module hook | module inputs 反向梯度计算完成后 | register_full_backward_hook(hook) |
| 节点 hook | autograd hook, 节点计算后 | register_hook(hook) |
| 通信 hook | hook 参数 dist.GradBucket ready | register_comm_hook(state, hook) |
torch.nn.parallel.DistributedDataParallel.register_comm_hook Tensor.register_hook(hook) torch.nn.Module.register_forward_hook(hook) torch.nn.Module.register_forward_pre_hook(hook) torch.nn.Module.register_full_backward_hook(hook) Node.register_hook(hook) torch.nn.parallel.DistributedDataParallel.register_comm_hook(state, hook)
反向 hook
反向 hook 最为常用的 hook,但反向梯度生成后加入逻辑。
# hook signature
hook(grad) -> Tensor or None
def hook(grad):
return grad * 2
v = torch.tensor([0., 0., 0.], requires_grad=True)
h = v.register_hook(hook) # double the gradient
v.backward(torch.tensor([1., 2., 3.]))
v.grad # 2 4 6
h.remove() # removes the hook
Module hook
register_forward_hook(hook)
hook(module, input, output) -> None or modified output
register_forward_pre_hook(hook)
hook(module, input) -> None or modified input
register_full_backward_hook(hook)
hook(module, grad_input, grad_output) -> tuple(Tensor) or None
# 不允许修改参数 tensor,但是可以返回 tensor 用于后续梯度计算
Autograd Hook
autograd hook,node grad 经典用法来自 horovod optimizer
p_tmp = p.expand_as(p)
grad_acc = p_tmp.grad_fn.next_functions[0][0]
grad_acc.register_hook(self._make_hook(p))
# 示例
>>> p = torch.tensor([1,2,3], dtype=float, requires_grad=True)
>>> p
tensor([1., 2., 3.], dtype=torch.float64, requires_grad=True)
>>> pt = p.expand_as(p)
>>> pt
tensor([1., 2., 3.], dtype=torch.float64, grad_fn=<ExpandBackward0>)
>>> pg = pt.grad_fn.next_functions[0][0]
>>> pg
<AccumulateGrad object at 0x7fa7ade03710>
DDP 通信 hook
torch.nn.parallel.DistributedDataParallel.register_comm_hook(state, hook)
hook(state: object, bucket: dist.GradBucket) -> torch.futures.Future[torch.Tensor]
Example
def encode_and_decode(state: object, bucket: dist.GradBucket): -> torch.futures.Future[torch.Tensor]
encoded_tensor = encode(bucket.buffer()) # encode gradients
fut = torch.distributed.all_reduce(encoded_tensor).get_future()
# Define the then callback to decode.
def decode(fut):
decoded_tensor = decode(fut.value()[0]) # decode gradients
return decoded_tensor
return fut.then(decode)
Reference
- https://pytorch.org/docs/stable/generated/torch.Tensor.register_hook.html
- https://pytorch.org/docs/stable/ddp_comm_hooks.html
Ealstic
launch/run
python -m torch.distributed.run
模块实际调用 elastic_launch 函数启动
# torch/distributed/run.py
def run(args):
config, cmd, cmd_args = config_from_args(args)
elastic_launch(
config=config,
entrypoint=cmd,
)(*cmd_args)
@record
def main(args=None):
args = parse_args(args)
run(args)
if __name__ == "__main__":
main()
elastic_launch 调用 launch_agent 方法
- 创建 RendezvousParameters,只包含声明
- 创建 WorkerSpec, rdzv_handler 参数处理见 rendezvous 部分
- 创建 LocalElasticAgent
- 调用 agent.run()
# torch/distributed/launcher/api.py
class elastic_launch:
def __call__(self, *args):
return launch_agent(self._config, self._entrypoint, list(args))
def launch_agent(...)
run_id = str(uuid.uuid4().int)
entrypoint_name = _get_entrypoint_name(entrypoint, args)
rdzv_parameters = RendezvousParameters(...)
# 这里的 master 只有在 rdzv_backend == static 时等于 rdzv, 否则都是 None,将会在后面创建
master_addr, master_port = _get_addr_and_port(rdzv_parameters)
spec = WorkerSpec(
role=config.role,
local_world_size=config.nproc_per_node,
entrypoint=entrypoint,
args=tuple(args),
rdzv_handler=rdzv_registry.get_rendezvous_handler(rdzv_parameters),
max_restarts=config.max_restarts,
monitor_interval=config.monitor_interval,
redirects=config.redirects,
tee=config.tee,
master_addr=master_addr,
master_port=master_port,
)
agent = LocalElasticAgent(
spec=spec, start_method=config.start_method, log_dir=config.log_dir
)
result = agent.run()
rendezvous
rendezvous 模块在初始化时把默认支持的 handler 都进行了初始化,注册在 handler_registry 中。
# torch/distributed/elastic/rendezvous/__init__.py
from .registry import _register_default_handlers
_register_default_handlers()
即提供了对应关系,可以通过 handler key 获取到 create handler 方法。
# torch/distributed/elastic/rendezvous/registry.py
from .api import rendezvous_handler_registry as handler_registry
from .dynamic_rendezvous import create_handler
def _create_c10d_handler(params: RendezvousParameters) -> RendezvousHandler:
from .c10d_rendezvous_backend import create_backend
backend, store = create_backend(params)
return create_handler(store, backend, params)
def _register_default_handlers() -> None:
handler_registry.register("c10d", _create_c10d_handler)
handler_registry.register("static", _create_static_handler)
def get_rendezvous_handler(params: RendezvousParameters) -> RendezvousHandler:
return handler_registry.create_handler(params)
注意这里有两个 create_handler,一个从注册器中取出并调用,一个是 create backend 后的封装。
启动时调用的 rdzv_registry.get_rendezvous_handler(rdzv_parameters) 即通过 prameter 获取对应 handler 并初始化。
import torch.distributed.elastic.rendezvous.registry as rdzv_registry
# torch/distributed/elastic/rendezvous/api.py
rendezvous_handler_registry = RendezvousHandlerRegistry()
class RendezvousHandlerRegistry:
_registry: Dict[str, RendezvousHandlerCreator]
def register(self, backend: str, creator: RendezvousHandlerCreator) -> None:
self._registry[backend] = creator
def create_handler(self, params: RendezvousParameters) -> RendezvousHandler:
creator = self._registry[params.backend]
handler = creator(params)
return handler
以 c10d 为例说明 create_backend,即真正启动服务的部分
# torch/distributed/elastic/rendezvous/c10d_rendezvous_backend.py
def _create_tcp_store(params: RendezvousParameters) -> TCPStore:
host, port = parse_rendezvous_endpoint(params.endpoint, default_port=29400)
# 对于同一台机器多进程启动的 case,通过重试解决
store = TCPStore(host, port, is_master=is_server, timeout=timedelta(seconds=read_timeout))
return store
def create_backend(params: RendezvousParameters) -> Tuple[C10dRendezvousBackend, Store]:
store_type = params.get("store_type", "tcp").strip().lower()
store = _create_tcp_store(params)
backend = C10dRendezvousBackend(store, params.run_id)
return backend, store
# torch/distributed/elastic/rendezvous/dynamic_rendezvous.py
def create_handler(
store: Store, backend: RendezvousBackend, params: RendezvousParameters
) -> DynamicRendezvousHandler:
return DynamicRendezvousHandler.from_backend(...)
class DynamicRendezvousHandler(RendezvousHandler):
@classmethod
def from_backend(
cls,
run_id: str,
store: Store,
backend: RendezvousBackend,
min_nodes: int,
max_nodes: int,
timeout: Optional[RendezvousTimeout] = None,
):
return cls(node, settings, backend.name, store, state_holder)
def next_rendezvous(self) -> Tuple[Store, int, int]:
self._start_heartbeats()
rank, world_size = self._get_world()
store = self._get_store()
return store, rank, world_size
def _keep_alive(self) -> None:
...
def _start_heartbeats(self) -> None:
...
_keep_alive 是通过 _PeriodicTimer 启动线程依赖 backend 实现的。
链路逻辑,
_keep_alive_weak调用_keep_alive,_DistributedRendezvousOpExecutor.run方法声明更新_DistributedRendezvousOpExecutor初始化时需要传入_state_holderstate_holder: _RendezvousStateHolder在 DynamicRendezvousHandler` 初始化时传入- _BackendRendezvousStateHolder(backend, settings) 使用
backend
worker
TL;DR;
提供 WorkerSpec/Worker/WorkerGroup/WorkerState/RunResult 抽象, 封装 process 管理。
调用如前所述,初始化后使用 agent.run() 调用,
- run 调用 invoke_run
- invoke_run 调用 _initialize_workers 实际拉起 worker 进程,然后 while 循环监控状态
_initialize_workers
- 首先调用 _rendezvous: 0 号节点在 store 中写入 master 地址,所有节点从中取出 master 地址,并不使用,只为了做同步
- 调用 _start_workers 启动 worker
0 号节点写入的 master 地址在使用 c10d backend (非 static)时并不是 rendevous endpoint,默认情况会通过 socket bind 获取可用端口,然后写入 store,其余节点从 store 中获取。
# torch/distributed/elastic/agent/server/api.py
class SimpleElasticAgent(ElasticAgent):
def run(self, role: str = DEFAULT_ROLE) -> RunResult:
result = self._invoke_run(role)
return result
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
self._initialize_workers(self._worker_group)
rdzv_handler = spec.rdzv_handler
while True:
run_result = self._monitor_workers(self._worker_group)
state = run_result.state
if state == WorkerState.SUCCEEDED:
self._exit_barrier()
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
if self._remaining_restarts > 0:
self._remaining_restarts -= 1
self._restart_workers(self._worker_group)
else:
self._stop_workers(self._worker_group)
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
elif state == WorkerState.HEALTHY:
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
def _initialize_workers(self, worker_group: WorkerGroup) -> None:
self._rendezvous(worker_group)
worker_ids = self._start_workers(worker_group)
def _rendezvous(self, worker_group: WorkerGroup) -> None:
store, group_rank, group_world_size = spec.rdzv_handler.next_rendezvous()
workers = self._assign_worker_ranks(store, group_rank, group_world_size, spec)
if group_rank == 0:
self._set_master_addr_port(store, spec.master_addr, spec.master_port)
# 获取 master 地址,起到同步作用
master_addr, master_port = self._get_master_addr_port(store)
@staticmethod
def _set_master_addr_port(
store: Store, master_addr: Optional[str], master_port: Optional[int]
):
if master_port is None:
sock = _get_socket_with_port()
with closing(sock):
master_port = sock.getsockname()[1]
if master_addr is None:
master_addr = _get_fq_hostname()
store.set("MASTER_ADDR", master_addr.encode(encoding="UTF-8"))
store.set("MASTER_PORT", str(master_port).encode(encoding="UTF-8"))
@staticmethod
def _get_master_addr_port(store: Store) -> Tuple[str, int]:
master_addr = store.get("MASTER_ADDR").decode(encoding="UTF-8")
master_port = int(store.get("MASTER_PORT").decode(encoding="UTF-8"))
return (master_addr, master_port)
def _get_socket_with_port() -> socket.socket:
s = socket.socket(family, type, proto)
s.bind(("localhost", 0))
s.listen(0)
return s
_start_workers 为真正启动进程的模块,
- 首先获取 master 地址,这个地址在非 static backend 时是 0 号节点写入 store 的
- 为 process 准备多种配置,主要包括 env,args,然后调用进程封装模块启动进程返回进程 id
# torch/distributed/elastic/agent/server/local_elastic_agent.py
class LocalElasticAgent(SimpleElasticAgent):
def _start_workers(self, worker_group: WorkerGroup) -> Dict[int, Any]:
master_addr, master_port = super()._get_master_addr_port(store)
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),
"RANK": str(worker.global_rank),
"GROUP_RANK": str(worker_group.group_rank),
"ROLE_RANK": str(worker.role_rank),
"ROLE_NAME": spec.role,
"LOCAL_WORLD_SIZE": str(spec.local_world_size),
"WORLD_SIZE": str(worker.world_size),
"GROUP_WORLD_SIZE": str(worker_group.group_world_size),
"ROLE_WORLD_SIZE": str(worker.role_world_size),
"MASTER_ADDR": master_addr,
"MASTER_PORT": str(master_port),
"TORCHELASTIC_RESTART_COUNT": str(restart_count),
"TORCHELASTIC_MAX_RESTARTS": str(spec.max_restarts),
"TORCHELASTIC_RUN_ID": spec.rdzv_handler.get_run_id(),
"TORCHELASTIC_USE_AGENT_STORE": str(use_agent_store),
"NCCL_ASYNC_ERROR_HANDLING": os.getenv(
"NCCL_ASYNC_ERROR_HANDLING", str(1)
),
}
if "OMP_NUM_THREADS" in os.environ:
worker_env["OMP_NUM_THREADS"] = os.environ["OMP_NUM_THREADS"]
envs[local_rank] = worker_env
worker_args = list(spec.args)
worker_args = macros.substitute(worker_args, str(local_rank))
args[local_rank] = tuple(worker_args)
self._pcontext = start_processes(
name=spec.role,
entrypoint=spec.entrypoint,
args=args,
envs=envs,
log_dir=attempt_log_dir,
start_method=self._start_method,
redirects=spec.redirects,
tee=spec.tee,
)
return self._pcontext.pids()
子进程启动的用户脚本例如 trainer.py,会获取这里配置的环境运行。
process
对进程和线程的封装,主要是 process 和 multiprocessing 库的封装。
通过对 entrypoint 是否是 str 判断决定启动方式。
# torch/distributed/elastic/multiprocessing/__init__.py
def start_processes(
name: str,
entrypoint: Union[Callable, str],
) -> PContext:
context: PContext
if isinstance(entrypoint, str):
context = SubprocessContext(...)
else:
context = MultiprocessContext(...)
try:
context.start()
return context
except Exception:
context.close()
raise
# torch/distributed/elastic/multiprocessing/api.py
class SubprocessHandler:
def __init__(...):
self.proc: subprocess.Popen = self._popen(args_str, env_vars)
class SubprocessContext(PContext):
def __init__(...):
self._running_local_ranks: Set[int] = set(range(self.nprocs))
self._failures: Dict[int, ProcessFailure] = {}
self.subprocess_handlers: Dict[int, SubprocessHandler] = {}
def _start(self):
self.subprocess_handlers = { local_rank: SubprocessHandler(...) }
def _poll(self) -> Optional[RunProcsResult]:
for local_rank in self._running_local_ranks:
exitcode = handler.proc.poll()
if exitcode is not None:
done_local_ranks.add(local_rank)
self._running_local_ranks.difference_update(done_local_ranks)
def _close(self, death_sig: signal.Signals, timeout: int = 30) -> None:
for handler in self.subprocess_handlers.values():
if handler.proc.poll() is None:
handler.close(death_sig=death_sig)
class PContext(abc.ABC):
def __init__(...):
self.entrypoint = entrypoint
def start(self) -> None:
self._start()
def wait(self, timeout: float = -1, period: float = 1) -> Optional[RunProcsResult]:
expiry = time.time() + timeout
while time.time() < expiry:
pr = self._poll()
if pr: return pr
def close(
self, death_sig: Optional[signal.Signals] = None, timeout: int = 30
) -> None:
self._close(death_sig=death_sig, timeout=timeout)
import torch.multiprocessing as mp
class MultiprocessContext(PContext):
def __init__(..., entrypoint: Callable, ...):
self._ret_vals = {
local_rank: mp.get_context(self.start_method).SimpleQueue()
for local_rank in range(self.nprocs)
}
self._pc: Optional[mp.ProcessContext] = None
def _start(self):
self._pc = mp.start_processes(...)
def _poll(self) -> Optional[RunProcsResult]:
self._pc.join(-1)
def _close(self, death_sig: signal.Signals, timeout: int = 30) -> None:
for proc in self._pc.processes:
if proc.is_alive():
try:
os.kill(proc.pid, death_sig)
demo
上面部分的内容都是 run 模块的部分,下面是用户侧代码比如 train.py 的部分。
import torch
torch.distributed.init_process_group(backend="nccl", init_method="env://")
print(torch.distributed.get_world_size())
init_process_group 提供两种初始化方式
- 显式提供 store, rank, world_size 以初始化
- 指定 init_method, 默认为 env:// 使用环境变量,如 launch/run 模块已配置好了环境变量
在没有 store 的时候会通过 rendevous 创建 store 并获取 rank 和 size 信息。
然后根据这些信息创建 process group,
- mpi 从 orte 中获取信息,不需要通过这里指定
- gloo/nccl 通过 store, rank, size 初始化创建通信域
# torch/distributed/distributed_c10d.py
from .rendezvous import rendezvous
def init_process_group(
backend,
init_method=None,
timeout=default_pg_timeout,
world_size=-1,
rank=-1,
store=None,
group_name="",
pg_options=None,
):
backend = Backend(backend)
if backend == Backend.MPI:
default_pg = _new_process_group_helper(
-1, -1, [], Backend.MPI, None, group_name=group_name, timeout=timeout
)
_update_default_pg(default_pg)
else:
if store is None:
rendezvous_iterator = rendezvous(
init_method, rank, world_size, timeout=timeout
)
store, rank, world_size = next(rendezvous_iterator)
store = PrefixStore("default_pg", store)
default_pg = _new_process_group_helper(...)
_update_default_pg(default_pg)
if backend == Backend.MPI:
barrier()
else:
_store_based_barrier(rank, store, timeout)
def _new_process_group_helper(
world_size,
rank,
group_ranks,
backend,
store,
pg_options=None,
group_name=None,
timeout=default_pg_timeout,
):
backend = Backend(backend)
if backend == Backend.MPI:
pg = ProcessGroupMPI.create(group_ranks)
_pg_map[pg] = (Backend.MPI, None)
_pg_names[pg] = group_name
else:
prefix_store = PrefixStore(group_name, store)
if backend == Backend.GLOO:
pg = ProcessGroupGloo(prefix_store, rank, world_size, timeout=timeout)
_pg_map[pg] = (Backend.GLOO, store)
_pg_names[pg] = group_name
elif backend == Backend.NCCL:
pg = ProcessGroupNCCL(prefix_store, rank, world_size, pg_options)
_pg_map[pg] = (Backend.NCCL, store)
_pg_names[pg] = group_name
return pg
rendevous 会创建 store 并返回 rank, size 信息,创建 store 通过 _create_c10d_store 实现,
在调用c api 创建 TCPStore 时通过 start_daemon 指定是否在当前调用里创建服务。
# torch/distributed/rendezvous.py
_rendezvous_handlers = {}
def rendezvous(url: str, rank: int = -1, world_size: int = -1, **kwargs):
return _rendezvous_handlers[result.scheme](url, **kwargs)
def register_rendezvous_handler(scheme, handler):
_rendezvous_handlers[scheme] = handler
register_rendezvous_handler("tcp", _tcp_rendezvous_handler)
register_rendezvous_handler("env", _env_rendezvous_handler)
register_rendezvous_handler("file", _file_rendezvous_handler)
def _file_rendezvous_handler(url: str, **kwargs):
result = urlparse(url)
query_dict = _query_to_dict(result.query)
rank = int(query_dict["rank"])
world_size = int(query_dict["world_size"])
store = FileStore(path, world_size)
yield (store, rank, world_size)
def _create_c10d_store(hostname, port, rank, world_size, timeout) -> Store:
if _torchelastic_use_agent_store():
tcp_store = TCPStore(hostname, port, world_size, False, timeout)
return PrefixStore(f"/worker/attempt_{attempt}", tcp_store)
else:
start_daemon = rank == 0
return TCPStore(
hostname, port, world_size, start_daemon, timeout, multi_tenant=True
)
def _tcp_rendezvous_handler(
url: str, timeout: timedelta = default_pg_timeout, **kwargs
):
result = urlparse(url)
query_dict = _query_to_dict(result.query)
rank = int(query_dict["rank"])
world_size = int(query_dict["world_size"])
store = _create_c10d_store(result.hostname, result.port, rank, world_size, timeout)
yield (store, rank, world_size)
def _env_rendezvous_handler(
url: str, timeout: timedelta = default_pg_timeout, **kwargs
):
result = urlparse(url)
query_dict: Dict[str, Union[int, str]] = _query_to_dict(result.query)
if "rank" in query_dict:
rank = int(query_dict["rank"])
else:
rank = int(_get_env_or_raise("RANK"))
if "world_size" in query_dict:
world_size = int(query_dict["world_size"])
else:
world_size = int(_get_env_or_raise("WORLD_SIZE"))
master_addr = _get_env_or_raise("MASTER_ADDR")
master_port = int(_get_env_or_raise("MASTER_PORT"))
store = _create_c10d_store(master_addr, master_port, rank, world_size, timeout)
yield (store, rank, world_size)
rendezvous_handler 的实现使用了 iterator 可以避免被多次调用,同时有 lazy init 的效果。
PyTorch Patch
summary
这个库提供了一种对 pytorch 进行 patch/hack 的方式,在很多场景可以借鉴,例如容错弹性。
patch_apex()
patch_torch_classes() # [torch, torch.Tensor, torch.nn.functional, torch.distributed]
patch_torch_nn_forward_functions() # [torch.nn.RNN, torch.nn.RNNCell, torch.nn.LSTM, torch.nn.LSTMCell, torch.nn.GRU, torch.nn.GRUCell]
patch_apex --> patch_apex_c + patch_apex_pyt
patch_apex_c --> patchClass --> add_wrapper
patch_apex_pyt --> patch_apex_module --> patch_apex_class --> add_wrapper
patch_torch_classes --> patchClass --> add_wrapper
patch_torch_nn_forward_functions --> add_wrapper
patch_apex
def patch_apex():
patch_apex_c()
patch_apex_pyt()
def patch_apex_c():
if importlib.util.find_spec("amp_C") is not None:
import amp_C
patchClass(amp_C)
# fused_adam_cuda
# fused_lamb_cuda
# fused_layer_norm_cuda
# distributed_lamb_cuda
# xentropy_cuda
# mlp_cuda
def patch_apex_pyt():
if importlib.util.find_spec("apex") is not None:
patch_apex_module("apex.amp")
patch_apex_module("apex.contrib.groupbn")
patch_apex_module("apex.contrib.multihead_attn")
patch_apex_module("apex.contrib.optimizers")
patch_apex_module("apex.contrib.sparsity")
patch_apex_module("apex.contrib.xentropy")
patch_apex_module("apex.fp16_utils")
patch_apex_module("apex.mlp")
patch_apex_module("apex.multi_tensor_apply")
patch_apex_module("apex.optimizers")
patch_apex_module("apex.parallel")
def patch_apex_module(modstr):
"""
Patch all forward/backward/step functions in classes in the given apex module.
"""
if importlib.util.find_spec(modstr) is not None:
mod = importlib.import_module(modstr)
for _, v in ins.getmembers(mod):
# This makes sure we don't patch random other modules that are imported by the target module
if is_same_module_or_submodule(mod, ins.getmodule(v)):
if (ins.isclass(v)):
patch_apex_class(v)
def patch_apex_class(cls):
"""
Patch all forward/backward/step functions in the given apex class
"""
for f in cls.__dict__:
if (ins.isfunction(cls.__dict__[f])):
if f in ["forward", "backward", "step"]:
add_wrapper(cls, f)
patch_torch_classes
def patchClass(cls):
for f in dir(cls):
if isfunc(cls, f):
add_wrapper(cls, f)
def patch_torch_classes():
"""Monkey-patch all classes in torch"""
for cls in [torch, torch.Tensor, torch.nn.functional, torch.distributed]:
patchClass(cls)
patch_torch_nn_forward_functions
def patch_torch_nn_forward_functions():
"""Monkey-patch all forward functions in torch.nn libraries"""
for cls in [torch.nn.RNN, torch.nn.RNNCell, torch.nn.LSTM, torch.nn.LSTMCell, torch.nn.GRU, torch.nn.GRUCell]:
if isfunc(cls, 'forward'):
add_wrapper(cls, 'forward')
add_wrapper
def add_wrapper(mod, fn_name):
# Get a pointer to the original function
func = getattr(mod, fn_name)
# Check if the mod has a string representation
# and is not a Script or Traced module (used by JIT)
# yapf: disable
s = hasattr(mod, "extra_repr") and (type(mod) is not torch.jit.ScriptModule
) and (type(mod) is not torch.jit.TopLevelTracedModule)
# yapf: enable
def wrapper_func(*args, **kwargs):
# Extract the stacktrace
stack = traceback.extract_stack()
# Push trace marker
nvtx.range_push(traceMarker(stack))
# Push module marker
if s:
m = modMarker(mod, fn_name, args)
nvtx.range_push(m)
# Create and push argument marker
cadena = argMarker(mod, fn_name, args, kwargs)
nvtx.range_push(cadena)
# Call the original function
result = func(*args, **kwargs)
# Pop argumet marker
nvtx.range_pop()
# Pop module marker
if s:
nvtx.range_pop()
# Pop trace marker
nvtx.range_pop()
return result
setattr(mod, fn_name, wrapper_func)
Reference
- https://github.com/NVIDIA/PyProf.git
PyTorch
目录结构 code base structure
c10: core library; essential functionality; (moving ATen/core to it)
aten: cpp tensor library (no autograd)
src:
ATen:
- core: moving above
- native: operators
torch: python library (including csrc)
csrc:
- autograd: automatic differenctiation
- api: cpp api
- distributed: distributed training
tools: code generation script
View
narrow(), view(), expand() and transpose()
# aten/src/ATen/native/TensorShape.cpp
split: narrow
narrow: slice
slice: as_strided
.stride()
.shape .size()
.contiguous()
.is_contiguous()
narrow
// aten/src/ATen/BatchingRegistrations.cpp
TORCH_LIBRARY_IMPL(aten, Batched, m) {
// NB: static_cast because there's another variant of narrow. However, we don't
// want to support the other variant yet bc it isn't documented...
m.impl("narrow", static_cast<Tensor(*)(const Tensor&,int64_t,int64_t,int64_t)>(native::narrow)); // composite wrt autograd
}
// aten/src/ATen/native/TensorShape.cpp
Tensor narrow(const Tensor& self, int64_t dim, int64_t start, int64_t length) {
TORCH_CHECK(self.dim() > 0, "narrow() cannot be applied to a 0-dim tensor.");
auto cur_size = self.size(dim);
if (start != cur_size) { // start being the end is valid, but not a valid dim specification.
start = maybe_wrap_dim(start, cur_size);
}
TORCH_CHECK(length >= 0 && start <= cur_size - length,
"start (", start, ") + length (", length, ") exceeds dimension size (", cur_size, ").");
return at::slice(self, dim, start, start + length, 1);
}
Tensor narrow(const Tensor& self, int64_t dim, const Tensor& start, int64_t length) {
TORCH_CHECK(start.dim() == 0 && isIntegralType(start.scalar_type(), /*includeBool=*/false),
"start must be an 0-dim integral Tensor.");
int64_t st = start.item<int64_t>();
return at::narrow(self, dim, st, length);
}
内部使用 slice 函数,这个函数并没有 python 绑定。
// build/aten/src/ATen/RegisterFunctionalization_0.cpp
at::Tensor as_strided(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, at::IntArrayRef size, at::IntArrayRef stride, c10::optional<int64_t> storage_offset) {
auto self_ = at::functionalization::impl::from_functional_tensor(self);
at::Tensor tmp_output;
at::Tensor reference_tensor_output;
{
at::AutoDispatchSkipFunctionalize guard;
auto self_meta = at::native::empty_strided_meta(self.sizes(), self.strides(), /*dtype=*/c10::make_optional(self.scalar_type()), /*layout=*/c10:: make_optional(self.layout()), /*device=*/c10::make_optional(c10::Device(kMeta)), /*pin_memory=*/c10::nullopt);
reference_tensor_output = at::_ops::as_strided::call(self_meta, size, stride, storage_offset);
tmp_output = at::_ops::as_strided::redispatch(dispatchKeySet & c10::after_func_keyset, self_, size, stride, storage_offset);
// I'm fusing the [alias removal], [mutation removal], [add views back] passes together.
// Later, we'll want to turn them into separate passes (since e.g. vulkan only cares about alias removal).
}
at::functionalization::ViewMeta view_meta = at::functionalization::ViewMeta(
[size = size.vec(), stride = stride.vec(), storage_offset = storage_offset](const at::Tensor & base, int64_t mutated_view_idx) -> at::Tensor {
return at::_ops::as_strided::call(base, size, stride, storage_offset);
},
[size = size.vec(), stride = stride.vec(), storage_offset = storage_offset](const at::Tensor & base, const at::Tensor & mutated_view, int64_t mutated_view_idx) -> at::Tensor {
return at::functionalization::FunctionalInverses::as_strided_inverse(base, mutated_view, size, stride, storage_offset);
}
);
auto out = at::functionalization::impl::create_functional_tensor_with_view_meta(tmp_output, self, view_meta);
// See Note [Propagating strides in the functionalization pass]
at::functionalization::impl::set_sizes_strides_offset(out, reference_tensor_output);
return out;
}
Multiprocessing
定义在 torch/_tensor.py 中的 subclassed class 如果需要跨进程,需要修改torch/multiprocessing/reductions.py 中的 ForkingPickler 做序列化。
RPC 分布式
rpc 函数
-
rpc_async()
-
rpc_sync()
-
remote(), no return e.x. create table from driver
Remote reference :分布式共享指针
Distributed Autograd
Distibuted Optimizer
paddle
paddle ps 代码分析
python 前端
API
import paddle.distributed.fleet as fleet
fleet.init()
if fleet.is_server():
fleet.init_server()
fleet.run_server()
elif fleet.is_worker():
run_worker()
fleet.stop_worker()
def run_worker():
# paddle.static.Executor(place)
exe.run(paddle.static.default_startup_program())
fleet.init_worker()
exe.train_from_dataset(...)
# Fin, fleet is optimizer
fleet init/optimizer
# python/paddle/distributed/fleet/base/fleet_base.py
def init(self, role_maker=None, is_collective=False, strategy=None):
# 配置之集大成者,就是各种配置,细到训练参数,粗到训练模式,开关
strategy = DistributedStrategy()
# role maker 包含分布式信息,基本上对接 launch 信息
# 也负责初始化如 gloo 之类的工具
self._role_maker._generate_role()
def minimize(...)
def _minimize_impl(...)
# runtime handle 做映射 init_server/_init_server, run_server/_run_server
self._runtime_handle = RuntimeFactory()._create_runtime(context)
runtime
# 使用实例
# python/paddle/distributed/ps/the_one_ps.py
class TheOnePSRuntime(RuntimeBase):
def __init__(self):
super(TheOnePSRuntime, self).__init__()
self._communicator = None
self._server = None
self._worker = fluid.core.DistFleetWrapper()
self._server_sub_program = []
self._heter_client = None
self._send_ctx = None
pybind
void BindDistFleetWrapper(py::module* m) {
py::class_<FleetWrapper, std::shared_ptr<FleetWrapper>>(*m,
"DistFleetWrapper")
.def(py::init([]() { return FleetWrapper::GetInstance(); }))
.def("load_sparse", &FleetWrapper::LoadSparseOnServer)
.def("load_model", &FleetWrapper::LoadModel)
.def("load_one_table", &FleetWrapper::LoadModelOneTable)
.def("init_server", &FleetWrapper::InitServer)
.def("run_server",
(uint64_t (FleetWrapper::*)(void)) & FleetWrapper::RunServer)
.def("run_server", (uint64_t (FleetWrapper::*)( // NOLINT
const std::string&, uint32_t)) & // NOLINT
FleetWrapper::RunServer)
.def("init_worker", &FleetWrapper::InitWorker)
.def("push_dense_params", &FleetWrapper::PushDenseParamSync)
.def("pull_dense_params", &FleetWrapper::PullDenseVarsSync)
.def("save_all_model", &FleetWrapper::SaveModel)
.def("save_one_model", &FleetWrapper::SaveModelOneTable)
.def("recv_and_save_model", &FleetWrapper::RecvAndSaveTable)
.def("sparse_table_stat", &FleetWrapper::PrintTableStat)
.def("stop_server", &FleetWrapper::StopServer)
.def("stop_worker", &FleetWrapper::FinalizeWorker)
.def("barrier", &FleetWrapper::BarrierWithTable)
.def("shrink_sparse_table", &FleetWrapper::ShrinkSparseTable)
.def("set_clients", &FleetWrapper::SetClients)
.def("get_client_info", &FleetWrapper::GetClientsInfo)
.def("create_client2client_connection",
&FleetWrapper::CreateClient2ClientConnection);
}
fleet run_server
# runtime 层初始化
class TheOnePSRuntime(RuntimeBase):
def _init_server(self, dirname=None, var_names=None, **kwargs):
# cpp instance
self._server = fluid.core.DistFleetWrapper()
self._server.init_server(server_desc, self.string_hosts, role_id,
trainers, self._server_sub_program)
# load_sparse
for var_name in load_varnames:
table_id = sparse_table_maps[var_name]
self._server.load_sparse(dirname, "0", table_id)
def _run_server(self):
self._server.run_server(host, int(port))
FleetWrapper
// paddle/fluid/distributed/ps/wrapper/fleet.cc
// FleetWrapper 层
void FleetWrapper::InitServer(...){
pserver_ptr_ = std::shared_ptr<paddle::distributed::PSCore>(
new paddle::distributed::PSCore());
pserver_ptr_->init_server(...)
}
uint64_t FleetWrapper::RunServer(...){
auto ret = pserver_ptr_->run_server(ip, port);
}
void FleetWrapper::LoadSparseOnServer(...){
// _server_ptr is PSServer
pserver_ptr_->_server_ptr->table(table_id)->load(path, meta);
}
PSCore
// paddle/fluid/distributed/ps/service/ps_service/service.cc
// PSCore layer
int PSCore::init_server(...){
_ps_env = paddle::distributed::PaddlePSEnvironment();
_ps_env.set_ps_servers(host_sign_list, node_num);
_ps_env.set_trainers(trainers); // 没啥用
_server_ptr = std::shared_ptr<paddle::distributed::PSServer>(
paddle::distributed::PSServerFactory::create(_ps_param));
ret = _server_ptr->configure(_ps_param, _ps_env, index, server_sub_program);
}
uint64_t PSCore::run_server(const std::string& ip, uint32_t port) {
return _server_ptr->start(ip, port);
}
PSServer
// paddle/fluid/distributed/ps/service/server.cc
// PSServer layer
PSServer *PSServerFactory::create(const PSParameter &ps_config) {
PSServer *server =
CREATE_PSCORE_CLASS(PSServer, service_param.server_class());
TableManager::instance().initialize();
}
int32_t PSServer::configure(...){
// for i in downpour_param.downpour_table_param_size()
auto *table = CREATE_PSCORE_CLASS(
Table, downpour_param.downpour_table_param(i).table_class());
table->set_program_env(scope_.get(), place_, &server_sub_program);
table->set_shard(_rank, shard_num);
table->initialize(downpour_param.downpour_table_param(i),
config.fs_client_param());
_table_map[downpour_param.downpour_table_param(i).table_id()].reset(table);
return initialize();
}
BrpcPsServer
// paddle/fluid/distributed/ps/service/brpc_ps_server.h
class BrpcPsServer : public PSServer {
brpc::Server _server;
}
// paddle/fluid/distributed/ps/service/brpc_ps_server.cc
int32_t BrpcPsServer::initialize() {
auto *service =
CREATE_PSCORE_CLASS(PsBaseService, service_config.service_class());
_server.AddService(service, brpc::SERVER_DOESNT_OWN_SERVICE)
}
uint64_t BrpcPsServer::start(const std::string &ip, uint32_t port) {
auto trainers = _environment->get_trainers(); // 可以去掉
_server.Start(ip_port.c_str(), &options)
_environment->registe_ps_server(ip, port, _rank);
}
BrpcPsService
class BrpcPsService : public PsBaseService {
int32_t initialize_shard_info(...)
int32_t pull_dense(...)
int32_t push_dense(...)
int32_t push_dense_param(...)
int32_t push_sparse_param(...)
int32_t pull_sparse(...)
int32_t pull_geo_param(...)
int32_t barrier(...)
int32_t push_sparse(...)
int32_t load_one_table(...)
int32_t load_all_table(...)
int32_t save_one_table(...)
int32_t save_all_table(...)
int32_t shrink_table(...)
int32_t clear_one_table(...)
int32_t clear_all_table(...)
int32_t stop_server(...)
int32_t start_profiler(...)
int32_t stop_profiler(...)
int32_t print_table_stat(...)
int32_t push_global_step(...)
}
fleet run_worker
runtime
# runtime 层初始化
class TheOnePSRuntime(RuntimeBase):
def _init_worker(self, scopes=None):
# in init
# self._worker = fluid.core.DistFleetWrapper()
self._worker.init_worker(proto_txt, self.string_hosts, role_id)
# GEO mode
self._communicator = Communicator(...)
self._communicator.init_with_ctx(...)
#
info = self._worker.get_client_info()
self._worker.set_clients(all_info) # _all_gather info is all_info
self._worker.create_client2client_connection()
#
self._pull_all_dense(scopes, send_ctx, dense_map)
# GEO mode
self._communicator.start()
def _pull_all_dense(self, scopes, send_ctx, recv_map):
for name, ctx in send_ctx.items():
self._worker.pull_dense_params(scope, table_id, var_names)
init worker
FleetWrapper
// paddle/fluid/distributed/ps/wrapper/fleet.cc
void FleetWrapper::InitWorker(...){
ps_env_.set_ps_servers(&host_sign_list, servers);
worker_ptr_ = std::shared_ptr<paddle::distributed::PSClient>(
paddle::distributed::PSClientFactory::create(ps_param));
worker_ptr_->configure(ps_param, dense_pull_regions, ps_env_, index);
}
void FleetWrapper::PullDenseVarsSync(...){
auto status = worker_ptr_->pull_dense(regions.data(), regions.size(), tid);
status.wait();
}
int FleetWrapper::SetClients(std::vector<uint64_t>& host_sign_list) {
return ps_env_.set_ps_clients(host_sign_list.data(), node);
}
void FleetWrapper::CreateClient2ClientConnection() {
worker_ptr_->create_client2client_connection(...)
}
PSClient
// paddle/fluid/distributed/ps/service/ps_client.cc
PSClient *PSClientFactory::create(const PSParameter &ps_config) {
PSClient *client = CREATE_PSCORE_CLASS(PSClient, service_param.client_class());
TableManager::instance().initialize();
}
int32_t PSClient::configure(...){
// for i in work_param.downpour_table_param_size()
auto *accessor = CREATE_PSCORE_CLASS(
ValueAccessor,
work_param.downpour_table_param(i).accessor().accessor_class());
accessor->configure(work_param.downpour_table_param(i).accessor());
accessor->initialize();
_table_accessors[work_param.downpour_table_param(i).table_id()].reset(accessor);
return initialize();
}
BrpcPsClient
// paddle/fluid/distributed/ps/service/brpc_ps_client.cc
class BrpcPsClient : public PSClient {
brpc::Server _server;
DownpourPsClientService _service;
}
int32_t BrpcPsClient::initialize() {
// for i in server_list.size()
_server_channels[i][j].reset(new brpc::Channel());
_server_channels[i][j]->Init(server_ip_port.c_str(), "", &options)
// 启动client探听接口, 并相互建立连接
start_client_service();
// 异步push 请求队列初始化
_push_dense_task_queue_map[table_id] = paddle::framework::MakeChannel<DenseAsyncTask *>();
_push_sparse_task_queue_map[table_id] = paddle::framework::MakeChannel<SparseAsyncTask *>();
// 启动异步push线程
_async_push_sparse_thread = std::thread(std::bind(&BrpcPsClient::push_sparse_task_consume, this));
// _async_push_sparse_thread.detach();
_async_push_dense_thread = std::thread(std::bind(&BrpcPsClient::push_dense_task_consume, this));
}
// 启动client端RpcService 用于数据互发等操作
int32_t BrpcPsClient::start_client_service() {
_service.configure(this, _client_id)
_server.AddService(&_service, brpc::SERVER_DOESNT_OWN_SERVICE);
_server.Start(butil::my_ip_cstr(), brpc::PortRange(start_port, max_port), &options)
_env->registe_ps_client(...)
}
// how 弹性???
int32_t BrpcPsClient::create_client2client_connection(...){
// for i in client_list.size()
_client_channels[i].reset(new brpc::Channel());
_client_channels[i]->Init(server_ip_port.c_str(), "", &options)
}
DownpourPsClientService
// paddle/fluid/distributed/ps/service/brpc_ps_client.cc
class DownpourPsClientService : public PsService {
PSClient *_client;
void service(...)
}
communicator
# python/paddle/fluid/communicator.py
class Communicator(object):
def init_with_ctx(self,...):
self.communicator_ = core.DistCommunicator(self.mode,...)
def start(self):
# Start communicator. Should call before training process.
self.communicator_.start()
bind
// paddle/fluid/pybind/communicator_py.cc
void BindCommunicator(py::module* m) {
// Communicator is already used by nccl, change to DistCommunicator
py::class_<Communicator, std::shared_ptr<Communicator>>(*m, "DistCommunicator")
.def(py::init([](...){Communicator::InitInstance<GeoCommunicator>(...)}
.def("start", &Communicator::Start)
// paddle/fluid/distributed/ps/service/communicator/communicator.h
static Communicator *InitInstance(...){
std::call_once(init_flag_, &Communicator::InitWithRpcCtx<T>,...);
}
static void InitWithRpcCtx(...){
communicator_.reset(new T(std::ref(envs)));
communicator_->InitEnvs();
communicator_->InitBrpcClient(dist_desc, host_sign_list);
communicator_->InitImpl(send_ctx, recv_ctx, recv_scope);
}
// paddle/fluid/distributed/ps/service/communicator/communicator.cc
void Communicator::InitBrpcClient(...){
auto fleet = paddle::distributed::FleetWrapper::GetInstance();
_worker_ptr = fleet->worker_ptr_;
}
void AsyncCommunicator::InitImpl(...){
// for varnames
send_varname_to_queue_[var_name] = std::make_shared<BlockingQueue<std::shared_ptr<Variable>>>(send_queue_size_);
send_threadpool_.reset(new ::ThreadPool(thread_pool_size_));
}
void AsyncCommunicator::Start() {
main_thread_.reset(new std::thread(std::bind(&AsyncCommunicator::MainThread, this))); // MainThread/RecvThread
}
void AsyncCommunicator::MainThread() {
while (running_) {
SendByCommunicator();
RpcProfilerControl();
}
}
void AsyncCommunicator::RecvThread() {
while (running_) {
RecvByCommunicator();
}
}
train_from_dataset
# dataset
dataset = paddle.distributed.InMemoryDataset() # "MultiSlotInMemoryDataFeed"
dataset.load_into_memory()
dataset.init(...)
dataset.set_filelist(train_files_list)
# InMemoryDataset -- MultiSlotInMemoryDataFeed -- InMemoryDataFeed -- DataFeed
# QueueDataset -- MultiSlotDataFeed -- PrivateQueueDataFeed -- DataFeed
# python/paddle/fluid/executor.py
# class Executor(object):
def train_from_dataset(self,...):
return self._run_from_dataset(...)
def _run_from_dataset(self,...):
# dataset
dataset = paddle.fluid.DatasetFactory().create_dataset(...)
dataset.set_xxx(...)
dataset._prepare_to_run()
# trainer
scope, trainer = self._prepare_trainer(...)
trainer._gen_trainer_desc()
# self._default_executor = core.Executor(p)
trainer_instance = self._default_executor.init_for_dataset(
program.desc, trainer._desc(), scope, dataset.dataset)
# run
self._default_executor.run_from_dataset(trainer_instance)
def _prepare_trainer(self,...):
trainer = TrainerFactory()._create_trainer(program.program._fleet_opt)
# trainer._set_thread(thread)
excutor
// paddle/fluid/framework/executor.cc
std::shared_ptr<TrainerBase> Executor::InitForDataset(...){
// MultiTrainer
std::shared_ptr<TrainerBase> trainer;
trainer = TrainerFactory::CreateTrainer(trainer_desc.class_name());
// initialize trainer
trainer->Initialize(trainer_desc, dataset);
trainer->SetScope(scope);
// prepare training environment and helper environment
trainer->InitTrainerEnv(main_program, place_);
// Try to init other environment
trainer->InitOtherEnv(main_program);
}
void Executor::RunFromDataset(std::shared_ptr<TrainerBase> trainer) {
trainer->Run();
}
MultiTrainer
//paddle/fluid/framework/trainer.h
class MultiTrainer : public TrainerBase {
std::vector<DataFeed*> readers_;
std::vector<std::shared_ptr<DeviceWorker>> workers_;
}
// paddle/fluid/framework/multi_trainer.cc
void MultiTrainer::Initialize(const TrainerDesc& trainer_desc, Dataset* dataset) {
// Dataset -> DataFeed
const std::vector<paddle::framework::DataFeed*> readers = dataset->GetReaders();
thread_num_ = readers.size(); // !!! thread num
workers_.resize(thread_num_);
// for i in thread_num_
workers_[i] = DeviceWorkerFactory::CreateDeviceWorker(...)
workers_[i]->Setxxx()
workers_[i]->Initialize(trainer_desc);
workers_[i]->SetDataFeed(readers[i]);
}
void MultiTrainer::Run() {
// for i in thread_num_
threads_.push_back(std::thread(&DeviceWorker::TrainFiles, workers_[thidx].get()));
// for th in threads_
th.join();
}
HogwildWorker
// paddle/fluid/framework/device_worker.cc
void DeviceWorker::SetDataFeed(DataFeed* data_feed) {
device_reader_ = data_feed;
}
// paddle/fluid/framework/hogwild_worker.cc
void HogwildWorker::Initialize(const TrainerDesc &desc) {
}
void HogwildWorker::TrainFiles() {
device_reader_->Start();
while ((cur_batch = device_reader_->Next()) > 0) {
// for op in ops_
op->Run(*thread_scope_, place_);
}
}
MultiSlotInMemoryDataFeed
// paddle/fluid/framework/data_feed.cc
class InMemoryDataFeed : public DataFeed {
// 下面的 channel 赋值在 DatasetImpl<T>::CreateReaders()
// input 为全局,output 和 consume 独立
paddle::framework::ChannelObject<T>* input_channel_;
paddle::framework::ChannelObject<T>* output_channel_;
paddle::framework::ChannelObject<T>* consume_channel_;
}
bool InMemoryDataFeed<T>::Start() {
// input
channel
global channel
input_channel_->Read(data);
output_channel_->Write(std::move(data));
}
int InMemoryDataFeed<T>::Next() {
while (index < this->default_batch_size_) {
output_channel_->Get(instance);
ins_vec.push_back(instance);
++index;
consume_channel_->Put(std::move(instance));
}
PutToFeedVec(ins_vec);
}
class MultiSlotInMemoryDataFeed : public InMemoryDataFeed<Record> {
}
MultiSlotDataFeed
// paddle/fluid/framework/data_feed.cc
class PrivateQueueDataFeed : public DataFeed {
std::shared_ptr<paddle::framework::ChannelObject<T>> queue_;
}
bool PrivateQueueDataFeed<T>::Start() {
read_thread_ = std::thread(&PrivateQueueDataFeed::ReadThread, this);
}
void PrivateQueueDataFeed<T>::ReadThread() {
while (PickOneFile(&filename)) {
fp_ = fs_open_read(filename, &err_no, pipe_command_);
while (ParseOneInstanceFromPipe(&instance)) {
queue_->Put(instance);
}
}
}
int PrivateQueueDataFeed<T>::Next() {
while (index < default_batch_size_) {
queue_->Get(instance)
AddInstanceToInsVec(&ins_vec, instance, index++);
}
PutToFeedVec(ins_vec);
}
class MultiSlotDataFeed : public PrivateQueueDataFeed<std::vector<MultiSlotType>> {
}
Misc
- InMemoryDataset 流程分析
-
LoadIntoMemory 把文件读取进 input_channel_,注意 input_channel_ 是全局共享,由 GetReaders() 返回时设定;
-
Start() 从 input_channel_ 读取一份数据进 output_channel_
-
Next() 从 output_channel_ 取数据进 consume_channel_
- input_channel_ 在哪里初始化?
data_set.cc 中 DatasetImpl
::CreateChannel(),它是全局的,最终调用在 dataset.py 中 self.dataset.create_channel(),所以 InMemoryDataset 有调用,QueueDataset 没有调用
Framework
Program
Python Program 定义
# python/paddle/fluid/framework.py
class Program(object):
CPP 定义
core.ProgramDesc()
# paddle/fluid/framework/program_desc.h
class ProgramDesc {}
对应 proto 定义
# paddle/fluid/framework/framework.proto
全局 default program
paddle.static.default_startup_program()
# _main_program_ = Program()
paddle.static.default_main_program()
# _startup_program_ = Program()
- startup_program: 模型参数初始化、优化器参数初始化、reader初始化
- main_program: 前向计算、反向计算、模型参数更新、优化器参数更新
CompiledProgram 即 Graph
# python/paddle/fluid/compiler.py
class CompiledProgram(object):
Program to Graph
core.Graph(program.desc)
Graph to Program
compiled_program._compile(...)
compiled_graph = compiled_program._graph
fluid.framework.IrGraph(compiled_graph).to_program()
Demo
静态图demo
import paddle
import numpy as np
paddle.enable_static()
inputs = paddle.static.data(name='input', shape=[None, 100], dtype='float32')
outputs = paddle.static.data(name='output', shape=[None, 10], dtype='float32')
out = paddle.static.nn.fc(x=inputs, size=10, activation='relu')
cost = paddle.nn.functional.square_error_cost(input=out, label=outputs)
loss = paddle.mean(cost)
adam = paddle.optimizer.Adam(learning_rate=1e-3)
adam.minimize(loss)
startup_program = paddle.static.default_startup_program()
main_program = paddle.static.default_main_program()
op_types = [op.type for op in startup_program.global_block().ops]
print(op_types)
op_types = [op.type for op in main_program.global_block().ops]
print(op_types)
executor = paddle.static.Executor()
executor.run(startup_program)
compiled_program = paddle.static.CompiledProgram(main_program)
BATCH_NUM = 20
BATCH_SIZE = 32
for batch_id in range(BATCH_NUM):
input_data = np.random.random([BATCH_SIZE, 100]).astype('float32')
output_data = np.random.random([BATCH_SIZE, 10]).astype('float32')
loss_numpy, = executor.run(main_program, feed={'input': input_data, 'output': output_data}, fetch_list=[loss])
print("Batch {}, loss = {}".format(batch_id, loss_numpy))
startup_program 的 op
['uniform_random', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant', 'fill_constant']
main_program 的 op
['mul', 'elementwise_add', 'relu', 'elementwise_sub', 'square', 'reduce_mean', 'fill_constant', 'reduce_mean_grad', 'square_grad', 'elementwise_sub_grad', 'relu_grad', 'elementwise_add_grad', 'mul_grad', 'adam', 'adam']
CINN
Summary
PassManger
core.ProgramDesc(main_program.desc)
core.apply_pass(tmp_main_program, ...)
main_program._rebuild_from_desc(tmp_main_program)
# apply_pass
framework::ir::Pass::ApplyPassesToProgram(main_program, ...)
Graph graph(*main_program)
pass->Apply(&graph);
ConvertToPrograms(&graph, main_program, ...);
Excutor build
graph = core.Graph(program.desc)
graph = pass->Apply(graph)
ir_graph = fluid.framework.IrGraph(graph)
ir_graph.to_program()
PassManager
Usage
from paddle.distributed.passes import new_pass, PassManager
pass_manager = PassManager([
new_pass("build_cinn"),
new_pass("fuse_elewise_add_act"),
])
pass_manager.apply([main_prog], [startup_prog])
op_types = [op.type for op in main_prog.global_block().ops]
self.assertTrue('cinn_launch' in op_types)
# python/paddle/fluid/framework.py
from paddle.fluid.framework import core, _apply_pass
def _apply_pass(main_program,
startup_program,
pass_name,
pass_attrs={},
pass_attr_types={}):
assert isinstance(pass_attrs, dict), "pass_attrs must be dict"
assert isinstance(pass_attr_types, dict), "pass_attr_types must be dict"
tmp_main_program = core.ProgramDesc(main_program.desc)
tmp_startup_program = core.ProgramDesc(startup_program.desc)
attrs = core.apply_pass(tmp_main_program, tmp_startup_program, pass_name,
pass_attrs, pass_attr_types)
main_program._rebuild_from_desc(tmp_main_program)
startup_program._rebuild_from_desc(tmp_startup_program)
return attrs
// paddle/fluid/pybind/ir.cc
m->def("apply_pass",
[](framework::ProgramDesc *main_program,
framework::ProgramDesc *startup_program,
const py::object &py_pass_names,
const std::unordered_map<std::string, py::object> &pass_attrs,
std::unordered_map<std::string, std::string> pass_attr_types) {
auto pass_names = GetPassNames(py_pass_names);
std::vector<std::unique_ptr<framework::ir::Pass>> passes;
std::vector<const framework::ir::Pass *> passes_not_owned;
passes.reserve(pass_names.size());
passes_not_owned.reserve(pass_names.size());
for (const auto &name : pass_names) {
auto pass = framework::ir::PassRegistry::Instance().Get(name);
SetAttrsToPass(pass_attrs, &pass_attr_types, pass.get());
passes.push_back(std::move(pass));
passes_not_owned.push_back(passes.back().get());
}
framework::ir::Pass::ApplyPassesToProgram(
passes_not_owned, main_program, startup_program);
std::unordered_map<std::string, py::object> result_attrs;
for (const auto &pass : passes) {
for (const auto &name_and_value : pass_attrs) {
const auto &attr_name = name_and_value.first;
const auto &attr_type = pass_attr_types.at(attr_name);
result_attrs[attr_name] =
PassAttrGetterSetterRegistry::Instance().Get(
*pass, attr_name, attr_type);
}
}
return result_attrs;
});
// paddle/fluid/framework/ir/pass.cc
void Pass::ApplyPassesToProgram(const std::vector<const Pass *> &passes,
ProgramDesc *main_program,
ProgramDesc *startup_program) {
if (passes.size() == 1 && !passes[0]->SupportApplyProgramViaGraph()) {
// apply pass to program
passes[0]->ApplyImpl(main_program, startup_program);
FillNotSpecifiedOpRole(*main_program);
return;
}
Graph graph(*main_program);
for (auto *p : passes) {
p->Apply(&graph);
}
ConvertToPrograms(&graph, main_program, startup_program);
FillNotSpecifiedOpRole(*main_program);
}
Graph *Pass::Apply(Graph *graph) const {
ApplyImpl(graph);
return graph;
}
Excutor Apply
def _compile(program, loss_name=None):
build_strategy = paddle.static.BuildStrategy()
exec_strategy = paddle.static.ExecutionStrategy()
exec_strategy.num_threads = 1
compiled_program = paddle.static.CompiledProgram(
program).with_data_parallel(
loss_name=loss_name,
build_strategy=build_strategy,
exec_strategy=exec_strategy)
return compiled_program
executor = paddle.static.Executor()
compiled_program = _compile(program_with_fetch_op, loss_name)
compiled_program._compile(scope, paddle.framework._current_expected_place())
compiled_graph = compiled_program._graph
ir_graph = fluid.framework.IrGraph(compiled_graph, for_test=True)
ir_program = ir_graph.to_program()
# python/paddle/fluid/compiler.py
BuildStrategy = core.ParallelExecutor.BuildStrategy
class CompiledProgram(object):
# Static Graph
def __init__(self, program_or_graph, build_strategy=None):
self._graph = core.Graph(program_or_graph.desc)
self._program = program_or_graph
def _compile(self, scope, place):
self._executor = self._compile_data_parallel(...)
def _compile_data_parallel(self, places, use_device, scope=None):
self._build_strategy = BuildStrategy()
core.ParallelExecutor(...)
// paddle/fluid/pybind/parallel_executor.cc
py::class_<ParallelExecutor> pe(m, "ParallelExecutor");
py::class_<BuildStrategy> build_strategy(pe, "BuildStrategy", R"DOC(
// paddle/fluid/framework/parallel_executor.cc
ParallelExecutor::ParallelExecutor(const std::vector<platform::Place> &places,
const std::vector<std::string> &bcast_vars,
const std::string &loss_var_name,
Scope *scope,
const std::vector<Scope *> &local_scopes,
const ExecutionStrategy &exec_strategy,
const BuildStrategy &build_strategy,
ir::Graph *graph){
// ParallelExecutorPrivate *member_;
std::vector<ir::Graph *> async_graphs = CompileGraphWithBuildStrategy(graph, &graphs, loss_var_name);
graph = member_->ApplyMemoryOptimizePass(graph);
std::vector<ir::Graph *> final_graphs = CreateSSAGraphExecutor(exec_strategy, &async_graphs, graph);
if (!member_->build_strategy_.async_mode_) {
member_->executor_.reset(new details::ScopeBufferedSSAGraphExecutor(
exec_strategy,
member_->local_scopes_,
member_->local_exec_scopes_,
std::move(var_infos),
member_->places_,
std::move(member_->executor_)));
}
}
std::vector<ir::Graph *> ParallelExecutor::CompileGraphWithBuildStrategy(
ir::Graph *graph,
std::vector<ir::Graph *> *device_graphs,
const std::string &loss_var_name) {
graph = member_->build_strategy_.Apply(graph, ...);
}
// paddle/fluid/framework/details/build_strategy.cc
ir::Graph *BuildStrategy::Apply(ir::Graph *graph, ...){
// 这里使用 ParallelExecutorPassBuilder 添加 pass
CreatePassesFromStrategy(false);
for (std::shared_ptr<ir::Pass> &pass : pass_builder_->AllPasses()) {
if (FLAGS_convert_all_blocks) {
for (size_t i = 0; i < graph->SubGraphsSize(); ++i) {
pass->Apply(graph->GetSubGraph(i));
}
} else {
graph = pass->Apply(graph);
}
}
}
std::shared_ptr<ir::PassBuilder> BuildStrategy::CreatePassesFromStrategy(bool finalize_strategy) const {
pass_builder_.reset(new ParallelExecutorPassBuilder(*this));
return pass_builder_;
}
class ParallelExecutorPassBuilder : public ir::PassBuilder {
...
AppendPass("build_cinn_pass");
}
Build CINN Pass
cinn pass 通过转成 Graph 然后 apply
// paddle/fluid/framework/paddle2cinn/build_cinn_pass.cc
void BuildCinnPass::ApplyImpl(Graph* graph) const { SearchAllSubgraphs(graph); }
void SearchAllSubgraphs(Graph* graph) {
std::vector<GraphNodeVec> clusters = framework::ir::SubgraphDetector(graph, teller)();
for (const auto& node_vec : clusters) {
cinn_compiler->AddGraph(CreateNewSubGraph(...)
ReplaceSubGraphWithCinnOpNode(...)
}
}
void ReplaceSubGraphWithCinnOpNode(...){
// Add the cinn op node whose name is "kCinnLaunchOp" into graph
AddCinnOpToGraph(...);
// Remove the cinn subgraph from graph
RemoveSubGraphFromGraph(cluster, cluster_internals, graph);
}
// paddle/fluid/framework/ir/subgraph_detector.cc
std::vector<std::vector<Node *>> SubgraphDetector::operator()() {
MarkNodesInsideSubGraph();
return ExtractSubGraphs();
}
void SubgraphDetector::MarkNodesInsideSubGraph() {
for (auto &node : framework::ir::GraphTraits::DFS(*graph_)) {
if (node_inside_subgraph_teller_(&node)) {
Agent(&node).set_marked(true);
if (node.IsOp()) {
// If a function is inside the sub-graph, mark all the output variables
// to be inside too, so that two marked functions will be inside a same
// sub-graph, lets take a example: A_function->var->B_function, if
// A_function is marked, var should also be marked, so that B_function
// will be in the same sub-graph with A_function if B_function is
// marked.
MarkOutLinksInSubGraph(&node);
}
}
}
}
std::vector<std::vector<Node *>> SubgraphDetector::ExtractSubGraphs() {
}
Prim op
通过以下API操作全局变量使用
paddle.incubate.autograd.enable_prim()
paddle.incubate.autograd.disable_prim()
paddle.incubate.autograd.prim_enabled()
具体影响由使用 AD API 时体现
# python/paddle/incubate/autograd/primapi.py
paddle.incubate.autograd.grad()
# 调用 primx.orig2prim(block)
dataloader
# python/paddle/io/dataloader/dataloader_iter.py
class _DataLoaderIterBase:
"""
Iterator implement of DataLoader, will load and feed mini-batch
data by setting in given dataloader.
Args:
loader(instance of DataLoader): instance of `paddle.io.DataLoader`
"""
def __init__(self, loader):
self._dataset = loader.dataset
self._feed_list = loader.feed_list or []
self._places = loader.places
self._return_list = loader.return_list
self._batch_sampler = loader.batch_sampler
self._drop_last = loader.drop_last
self._auto_collate_batch = loader.auto_collate_batch
self._num_workers = loader.num_workers
self._use_buffer_reader = loader.use_buffer_reader
self._prefetch_factor = loader.prefetch_factor
self._use_shared_memory = loader.use_shared_memory
self._timeout = (
loader.timeout if loader.timeout > 0 else MP_STATUS_CHECK_INTERVAL
)
self._worker_init_fn = loader.worker_init_fn
self._dataset_kind = loader.dataset_kind
self._pin_memory = loader.pin_memory
# LoDTensorBlockingQueue instance for create_py_reader and a thread
# to put mini-batch data to self._blocking_queue, mini-batch data
# will be get from:
# 1. multi-process mode: get data from workers' result queue
# 2. single-process mode: read mini-batch data in main process
self._blocking_queue = None
self._thread = None
self._thread_done_event = threading.Event()
# python/paddle/io/dataloader/dataloader_iter.py
class _DataLoaderIterSingleProcess(_DataLoaderIterBase):
"""
Single process implement of DataLoaderIter, loading data from
loader.data in main process
"""
def __init__(self, loader):
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset, ...
)
# NOTE: _structrue_infos used to record the data structure of
# batch to restore batch structure after reading Tensor
# from blocking_queue in single-process mode. Note that
# only single process is used in single-process mode, we
# can record the data structure sequencely in a list without
# recording the send and recv index
self._structure_infos = []
self._blocking_queue_capacity = self._prefetch_factor * len(
self._places
)
self._init_thread()
def _init_thread(self):
self._blocking_queue = core.init_lod_tensor_blocking_queue(...)
self._reader = core.create_py_reader(...)
self._thread = threading.Thread(
target=self._thread_loop, args=(_current_expected_place(),)
)
self._thread.start()
def _thread_loop(self, legacy_expected_place):
while not self._thread_done_event.is_set():
try:
indices = next(self._sampler_iter)
batch = self._dataset_fetcher.fetch(
indices, self._thread_done_event
)
batch, structure = _flatten_batch(batch)
try:
# pack as LoDTensorArray
array = core.LoDTensorArray()
for slot in batch:
if isinstance(slot, (paddle.Tensor, core.eager.Tensor)):
slot = slot.value().get_tensor()
elif not isinstance(slot, core.LoDTensor):
tmp = core.LoDTensor()
tmp.set(slot, core.CPUPlace())
slot = tmp
array.append(slot)
try:
self._blocking_queue.push(array)
def __next__(self):
try:
if in_dygraph_mode():
data = core.eager.read_next_tensor_list(
self._reader.read_next_list()[0]
)
data = _restore_batch(data, self._structure_infos.pop(0))
else:
if self._return_list:
data = self._reader.read_next_list()
else:
data = self._reader.read_next()
return data
class _DataLoaderIterMultiProcess(_DataLoaderIterBase):
def __init__(self, loader):
super().__init__(loader)
self._data_queue = None
self._outstanding_capacity = self._prefetch_factor * max(
self._num_workers, len(self._places)
)
# see _try_put_indices
self._thread_lock = threading.Lock()
self._init_workers()
for _ in range(self._outstanding_capacity):
self._try_put_indices()
self._init_thread()
def _init_workers(self):
self._data_queue = multiprocessing.Queue()
for i in range(self._num_workers):
indices_queue = multiprocessing.Queue()
self._indices_queues.append(indices_queue)
worker = multiprocessing.Process( target=_worker_loop, args=(self._dataset, ...),)
worker.start()
self._workers.append(worker)
def _init_thread(self):
self._blocking_queue = core.init_lod_tensor_blocking_queue(
core.Variable(), self._outstanding_capacity, len(self._places) > 1
)
self._reader = core.create_py_reader(self._blocking_queue, ...)
self._thread = threading.Thread(
target=self._thread_loop, args=(_current_expected_place(),)
)
self._thread.start()
def _reset(self):
# resume iteration in following steps
# 1. Resume workers, clear worker caches
# put _ResumeIteration to all worker as resume iteration flag
with self._thread_lock:
self._resume_worker_cnt = self._num_workers
for worker_id in range(self._num_workers):
self._indices_queues[worker_id].put(_ResumeIteration())
self._batches_outstanding += 1
# all flag will be check in _thread_loop, simply wait here
while self._resume_worker_cnt > 0:
time.sleep(0.5)
# 2. clear blocking_queue caches
# in order not to restart the thread, we just clear
# the blocking_queue cachees instead of recreating one
while self._blocking_queue.size() >= len(self._places):
if in_dygraph_mode():
data = core.eager.read_next_tensor_list(
self._reader.read_next_list()[0]
)
else:
if self._return_list:
self._reader.read_next_list()
else:
data = self._reader.read_next()
# 3. reset all states
self._send_idx = 0
self._rcvd_idx = 0
self._batches_outstanding = 0
self._task_infos = {}
self._structure_infos = []
# set all worker status available
self._worker_status = [True] * self._num_workers
# 4. reset _sampler_iter and put prefetch indices to start next epoch
# init workers and indices queues and put 2 indices in each indices queue
self._sampler_iter = iter(self._index_sampler)
for _ in range(self._outstanding_capacity):
self._try_put_indices()
def _thread_loop(self, legacy_expected_place):
while not self._thread_done_event.is_set():
batch = self._get_data()
if not self._thread_done_event.is_set():
try:
# pack as LoDTensorArray
array = core.LoDTensorArray()
if self._use_shared_memory:
for tensor in batch:
array.append(tensor)
else:
# LoDTensor not in shared memory is not
# serializable, cannot be create in workers
for slot in batch:
if isinstance(
slot, (paddle.Tensor, core.eager.Tensor)
):
slot = slot.value().get_tensor()
elif not isinstance(slot, core.LoDTensor):
tmp = core.LoDTensor()
tmp.set(slot, core.CPUPlace())
slot = tmp
array.append(slot)
if not self._blocking_queue.push(array):
self._blocking_queue.close()
def _get_data(self):
while not self._thread_done_event.is_set():
# For IterableDataset, batch indices is generated infinitely
# for each worker to raise StopIteration, but a StopIteration
# raising process will discard a batch indices which is count
# in _send_idx but will not increase _rcvd_idx, so we check
# whether the worker is still alive here to skip the discarded
# batch indices and increase _rcvd_idx
if self._dataset_kind == _DatasetKind.ITER:
while self._rcvd_idx < self._send_idx:
info = self._task_infos[self._rcvd_idx]
if len(info) == 3 or self._worker_status[info[0]]:
break
del self._task_infos[self._rcvd_idx]
self._rcvd_idx += 1
self._batches_outstanding -= 1
else:
# NOTE: when _rcvd_idx catch up _send_idx, which means
# one of following:
# 1. all 2 * num_workers batches have been loaded
# and stored in _blocking_queue
# 2. all data drained
# we need to let _thread blocking at _data_queue
# get_data to inoccupy CPU, otherwise may occupy
# CPU time for model running
# NOTE: in persistent workers mode, do not check data
# drained here, simply let it go to _data_queue
# reading to get _ResumeIteration
if not self._persistent_workers:
# NOTE: _rcvd_idx and _send_idx only record batches among
# workers, if batches among workers drained, there
# may also be data in blocking queue
if self._batches_outstanding < len(self._places):
return None
if (
self._rcvd_idx in self._task_infos
and len(self._task_infos[self._rcvd_idx]) == 3
):
info = self._task_infos.pop(self._rcvd_idx)
self._structure_infos.append(info[2])
return info[1]
try:
# [ avoid hang ]: main process may blocking at _reader.read_next when
# KeyboardInterrupt, we do following tradeoff:
# 1. get data with timeout, MP_STATUS_CHECK_INTERVAL(5s) as timeout
# default, if KeyboardInterrupt blocking, failed workers will be
# checked and raise RuntimeError to quit DataLoader in timeout
# exception handling.
# 2. if get data timeout and check workers all alive, continue to
# get data again
data = self._data_queue.get(timeout=self._timeout)
except Exception as e:
# check if thread done event set when waiting data
if self._thread_done_event.is_set():
continue
# check failed workers
failed_workers = []
for i, w in enumerate(self._workers):
if self._worker_status[i] and not w.is_alive():
failed_workers.append(w)
self._shutdown_worker(i)
if len(failed_workers) > 0:
self._exit_thread_unexpectedly()
pids = ', '.join(str(w.pid) for w in failed_workers)
raise RuntimeError(
"DataLoader {} workers exit unexpectedly, "
"pids: {}".format(len(failed_workers), pids)
)
# get(timeout) will call _poll(timeout) and may raise IOError
if isinstance(e, queue.Empty) or isinstance(e, IOError):
# continue on timeout to keep getting data from queue
continue
self._exit_thread_unexpectedly()
logging.error(
"DataLoader reader thread failed({}) to read data from "
"workers' result queue.".format(e)
)
raise e
else:
if self._dataset_kind == _DatasetKind.ITER and isinstance(
data, _IterableDatasetStopIteration
):
# if a worker get StopIteraion, we shutdown this worker,
# note that this batch indices to trigger StopIteration
# is discard, outstanding batch number should be decrease
# and another indices should be put for other workers
# may still working.
if self._persistent_workers:
self._worker_status[data.worker_id] = False
else:
self._shutdown_worker(data.worker_id)
self._batches_outstanding -= 1
self._try_put_indices()
continue
idx, batch, structure = data
if (
isinstance(idx, _ResumeIteration)
and batch is None
and structure is None
):
return idx
if isinstance(batch, _WorkerException):
self._exit_thread_unexpectedly()
batch.reraise()
if idx == self._rcvd_idx:
del self._task_infos[idx]
self._structure_infos.append(structure)
return batch
else:
self._task_infos[idx] += (batch, structure)
continue
def _try_put_indices(self):
assert (
self._batches_outstanding <= self._outstanding_capacity
), "too many indices have been put to queue"
# In multi-process mode for IterableDataset, _try_put_indices will
# be called both in main process(for our implement has blocking queue,
# and blocking queue read is in main process) and thread, which may
# cause error following error
# 1. "ValueError: generator already executing" in next(self._sampler_iter)
# 2. re-enter in increase _send_idx
# add a lock for threading save, for _try_put_indices is only a slight
# function which is not in data reading pipeline, this lock almost no
# influence on performance
with self._thread_lock:
try:
indices = next(self._sampler_iter)
except StopIteration:
return
for i in range(self._num_workers):
worker_idx = next(self._workers_idx_cycle)
if self._worker_status[worker_idx]:
break
else:
return
self._indices_queues[worker_idx].put((self._send_idx, indices))
self._task_infos[self._send_idx] = (worker_idx,)
self._batches_outstanding += 1
self._send_idx += 1
def __del__(self):
self._try_shutdown_all()
def _shutdown_on_exit(self):
self._try_shutdown_all(1)
def __next__(self):
if in_profiler_mode():
trace_event = profiler.RecordEvent(
name="_DataLoaderIterMultiProcess",
event_type=profiler.TracerEventType.Dataloader,
)
trace_event.begin()
try:
benchmark().check_if_need_record(self)
benchmark().before_reader()
# _batches_outstanding here record the total batch data number
# in 'from after _try_put_indices to beforeoutput data', this
# value should be _outstanding_capacity if data is not drained,
# if _batches_outstanding is less than _places number, there are
# no enough data to generate next output, close blocking_queue and
# set _thread_done_event here, py_reader will raise StopIteration,
# end workers and indices_queues in StopIteration handling
if self._batches_outstanding < len(self._places):
if self._persistent_workers:
raise StopIteration
else:
self._thread_done_event.set()
self._blocking_queue.close()
if in_dygraph_mode():
data = core.eager.read_next_tensor_list(
self._reader.read_next_list()[0]
)
data = _restore_batch(data, self._structure_infos.pop(0))
else:
if self._return_list:
data = self._reader.read_next_list()
for i in range(len(data)):
data[i] = data[i]._move_to_list()
structs = [
self._structure_infos.pop(0)
for _ in range(len(self._places))
]
data = [_restore_batch(d, s) for d, s in zip(data, structs)]
# static graph organized data on multi-device with list, if
# place number is 1, there is only 1 device, extra the data
# from list for devices to be compatible with dygraph mode
if len(self._places) == 1:
data = data[0]
else:
data = self._reader.read_next()
self._on_output_batch()
benchmark().after_reader()
return data
except StopIteration:
if not self._persistent_workers:
self._reader.shutdown()
self._try_shutdown_all()
raise
finally:
if in_profiler_mode():
trace_event.end()
def _on_output_batch(self):
for _ in range(len(self._places)):
self._batches_outstanding -= 1
self._try_put_indices()
Horovod
Horovod core principles are based on MPI concepts such as size, rank, local rank, allreduce, allgather, broadcast, and alltoall
Run
启动
setup(name='horovod',
entry_points={
'console_scripts': [
'horovodrun = horovod.runner.launch:run_commandline'
]
})
# horovod/runner/launch.py
def run_commandline():
args = parse_args()
_run(args)
def _run(args):
# set args.hosts
if _is_elastic(args):
return _run_elastic(args)
else:
return _run_static(args)
非弹性启动
def _run_static(args):
settings = hvd_settings.Settings(...)
nics = driver_service.get_common_interfaces(settings, all_host_names,
remote_host_names, fn_cache)
if args.run_func:
executable = args.executable or sys.executable
command = [executable, '-m', 'horovod.runner.run_task', str(driver_ip), str(run_func_server_port)]
else:
command = args.command
_launch_job(args, settings, nics, command)
def _launch_job(args, settings, nics, command):
def gloo_run_fn():
driver_ip = network.get_driver_ip(nics)
gloo_run(settings, nics, env, driver_ip, command)
def mpi_run_fn():
mpi_run(settings, nics, env, command)
def js_run_fn():
js_run(settings, nics, env, command)
run_controller(args.use_gloo, gloo_run_fn,
args.use_mpi, mpi_run_fn,
args.use_jsrun, js_run_fn,
args.verbose)
def run_controller(use_gloo, gloo_run, use_mpi, mpi_run, use_jsrun, js_run, verbosity):
if use_gloo:
gloo_run()
elif use_mpi:
mpi_run()
elif use_jsrun:
js_run()
from horovod.runner.gloo_run import gloo_run, gloo_run_elastic
from horovod.runner.mpi_run import mpi_run
from horovod.runner.js_run import js_run, is_jsrun_installed
# horovod/runner/gloo_run.py
def gloo_run(settings, nics, env, server_ip, command):
# 启动命令通过 ssh 分发,如果出错所有进程将被 kill
# 先封装执行函数
exec_command = _exec_command_fn(settings)
# 再调用执行
launch_gloo(command, exec_command, settings, nics, env, server_ip)
def _exec_command_fn(settings):
def _exec_command(command, slot_info, events):
# 如果是需要分发到 remote 的节点
# from horovod.runner.util.remote import get_remote_command
# get_remote_command 提供 ssh 封装
if host_address not in local_addresses:
command = get_remote_command(local_command,...)
exit_code = safe_shell_exec.execute(command,...)
return _exec_command
def launch_gloo(command, exec_command, settings, nics, env, server_ip):
# exec_command 为执行的命令
# args_list 是执行的参数,由每个节点所需参数组成的列表
# 通过如下方法的调用实现多节点运行
res = threads.execute_function_multithreaded(exec_command, args_list, block_until_all_done=True)
# horovod/runner/util/threads.py
def execute_function_multithreaded(fn, args_list, block_until_all_done=True, max_concurrent_executions=1000):
worker_queue = queue.Queue()
result_queue = queue.Queue() # 结果池,用于放置结果,后续忽略
# 把任务放进任务池
for i, arg in enumerate(args_list):
worker_queue.put(arg)
# 只要任务池里还有任务就取出来执行之
def fn_execute():
while True:
arg = worker_queue.get(block=False)
exec_index = arg[-1]
res = fn(*arg[:-1])
# 启动多线程分发命令,感觉必要性不大
for _ in range(number_of_threads):
thread = in_thread(target=fn_execute, daemon=not block_until_all_done)
def in_thread(target, args=(), name=None, daemon=True, silent=False):
bg = threading.Thread(target=fn, args=args, name=name)
bg.daemon = daemon
bg.start()
# horovod/runner/common/util/safe_shell_exec.py
# 使用 multiprocessing.Process 启动进程
# 然后再使用 subprocess 启动进程执行
def execute(command, env=None, stdout=None, stderr=None, index=None, events=None,
prefix_output_with_timestamp=False):
ctx = multiprocessing.get_context('spawn')
exit_event = _create_event(ctx)
# 当 parent process 被 hard kill 时,这个 Pipe 会被关闭,然后 middleman 就会向子进程发送 SIGTERM,避免出现 orphaned process
(r, w) = ctx.Pipe(duplex=False)
middleman = ctx.Process(target=_exec_middleman, args=(command, env, exit_event, ..., (r, w)))
middleman.start()
middleman.join()
return middleman.exitcode
def _exec_middleman(command, env, exit_event, stdout, stderr, rw):
os.setsid()
executor_shell = subprocess.Popen(command, shell=True, env=env,
stdout=stdout_w, stderr=stderr_w)
# horovod/runner/mpi_run.py
def mpi_run(settings, nics, env, command, stdout=None, stderr=None):
mpirun_command = (
'mpirun {basic_args} '
'-np {num_proc}{ppn_arg}{hosts_arg} '
'{binding_args} '
'{mpi_args} '
'{mpi_ssh_args} '
'{tcp_intf_arg} '
'{nccl_socket_intf_arg} '
'{output_filename_arg} '
'{env} {extra_mpi_args} {command}'
)
if settings.run_func_mode:
exit_code = safe_shell_exec.execute(mpirun_command, env=env, stdout=stdout, stderr=stderr)
else:
os.execve('/bin/sh', ['/bin/sh', '-c', mpirun_command], env)
Workflow
本节关于 horovod 的主要工作流程,包含以下内容
- HorovodBasics 即 API 部分
- Operation 基于上述 API 的调用和调用后主要流程
TL;DR;
hvd.init()
- 调用 c api
horovod_init, 调用函数InitializeHorovodOnce创建 thread 运行BackgroundThreadLoop, 完成初始化后函数返回。 - 后台线程执行
BackgroundThreadLoop进行各种初始化操作,最后 while 循环RunLoopOnce(state). RunLoopOnce从队列中取出 tensor 驱动分布式通信。
allreduce_async_
- python api 是根据框架封装的,PyTorch 通过 pybind 调用
EnqueueTensorAllreduces,将 tensor 放如队列。
HorovodBasics
Python API
- horovod 的基础 API,会被具体实现 (torch/tf) 使用
- 提供 C 接口的 py 封装,通过 ctypes 实现调用
# horovod/common/basics.py
class HorovodBasics(object):
def __init__(self, pkg_path, *args):
# 加载 mpi lib 实现包
self.MPI_LIB_CTYPES = ctypes.CDLL(full_path, mode=ctypes.RTLD_GLOBAL)
def init(self, comm, process_sets):
initialization_ok = self.MPI_LIB_CTYPES.horovod_init(...)
# initialization_ok = self.MPI_LIB_CTYPES.horovod_init_multi_comm(...)
_init_process_sets(process_sets)
def shutdown(self):
def is_initialized(self):
def start_timeline(self, file_path, mark_cycles=False):
def stop_timeline(self):
def size(self):
def local_size(self):
def cross_size(self):
def rank(self):
def local_rank(self):
def cross_rank(self):
def is_homogeneous(self):
def mpi_threads_supported(self):
def mpi_enabled(self):
def mpi_built(self):
def gloo_enabled(self):
def gloo_built(self):
def nccl_built(self):
def ddl_built(self):
def ccl_built(self):
def cuda_built(self):
def rocm_built(self):
def _add_process_set_impl(self, ranks: Sequence[int]) -> Optional[int]:
def _remove_process_set_impl(self, process_set_id: int) -> Optional[int]:
def _process_set_rank(self, process_set_id: int) -> int:
def _process_set_size(self, process_set_id: int) -> int:
def _get_process_set_ids_and_ranks(self) -> Dict[int, List[int]]:
def _comm_process_set_id(self, comm: MPI.Comm) -> int:
C API
这里的接口有两个部分
- 系统相关的 C 接口,通过 py 的 ctypes 引用
- 通信相关的接口,直接被调用
// horovod/common/operations.h
namespace horovod {
namespace common {
extern "C" {
bool horovod_init(const int* ranks, int nranks, const int* process_set_ranks,
const int* process_set_sizes, int num_process_sets);
#if HAVE_MPI
// 使用 MPI communicators 初始化
bool horovod_init_multi_comm(MPI_Comm* comm, int ncomms,
const int* process_set_ranks_via_ranks,
const int* process_set_sizes_via_ranks,
int num_process_sets_via_ranks);
#endif
void horovod_shutdown();
int horovod_rank();
int horovod_local_rank();
int horovod_size();
int horovod_local_size();
// bool horovod_xxx_enabled();
// bool horovod_xxx_built();
int horovod_reduce_op_average();
int horovod_reduce_op_sum();
int horovod_reduce_op_adasum();
int horovod_add_process_set(const int *ranks, int nranks);
int horovod_remove_process_set(int process_set_id);
int horovod_process_set_rank(int process_set_id);
int horovod_process_set_size(int process_set_id);
int horovod_process_set_included(int process_set_id);
int horovod_number_of_process_sets();
void horovod_process_set_ids(int* ids_prealloc);
int horovod_process_set_ranks(int id, int* ranks_prealloc);
} // C API 结束
Status EnqueueTensorAllreduce(std::shared_ptr<OpContext> context,
std::shared_ptr<Tensor> tensor,
std::shared_ptr<Tensor> output,
ReadyEventList ready_event_list,
std::string name, int device,
StatusCallback callback,
ReduceOp reduce_op = ReduceOp::SUM,
double prescale_factor = 1.0,
double postscale_factor = 1.0,
int32_t process_set_id = 0);
Status EnqueueTensorAllreduces(std::vector<std::shared_ptr<OpContext>>& contexts,
std::vector<std::shared_ptr<Tensor>>& tensors,
std::vector<std::shared_ptr<Tensor>>& outputs,
std::vector<ReadyEventList>& ready_event_lists,
std::vector<std::string>& names,
int device,
std::vector<StatusCallback>& callbacks,
ReduceOp reduce_op = ReduceOp::SUM,
double prescale_factor = 1.0,
double postscale_factor = 1.0,
int32_t process_set_id = 0);
Status EnqueueTensorAllgather(std::shared_ptr<OpContext> context,
std::shared_ptr<Tensor> tensor,
ReadyEventList ready_event_list,
const std::string& name, int device,
StatusCallback callback,
int32_t process_set_id = 0);
Status EnqueueTensorBroadcast(std::shared_ptr<OpContext> context,
std::shared_ptr<Tensor> tensor,
std::shared_ptr<Tensor> output, int root_rank,
ReadyEventList ready_event_list,
const std::string& name, int device,
StatusCallback callback,
int32_t process_set_id = 0);
Status EnqueueTensorAlltoall(std::shared_ptr<OpContext> context,
std::shared_ptr<Tensor> tensor,
std::shared_ptr<Tensor> splits,
ReadyEventList ready_event_list,
const std::string& name, int device,
StatusCallback callback,
int32_t process_set_id = 0);
Status EnqueueTensorReducescatter(std::shared_ptr<OpContext> context,
std::shared_ptr<Tensor> tensor,
ReadyEventList ready_event_list,
const std::string& name, int device,
StatusCallback callback,
ReduceOp reduce_op = ReduceOp::SUM,
int32_t process_set_id = 0);
Status EnqueueJoin(std::shared_ptr<OpContext> context,
std::shared_ptr<Tensor> output_last_joined_rank,
ReadyEventList ready_event_list,
const std::string& name, int device,
StatusCallback callback,
int32_t process_set_id = 0);
Status EnqueueBarrier(StatusCallback callback,
int32_t process_set_id = 0);
} // namespace common
} // namespace horovod
#endif // HOROVOD_OPERATIONS_H
Operation
Horovod 的主要流程都在 horovod/common/operations.cc 中,主线包含两个方面
- init 接口调用启动后台进程,不断从 tensor_queue 中取出需要通信的 tensor 进行通信并返回结果
- 用户前端接口调用间接调用 EnqueueTensorAllreduces 以及类似的 API 不断将需要进行通信的 tensor 放入 tensor_queue
初始化和出 Queue
初始化接口的具体实现,启动一个后台进程,不断出发执行通信操作
// horovod/common/operations.cc
extern "C" {
bool horovod_init(const int* ranks, int nranks, const int* process_set_ranks,
const int* process_set_sizes, int num_process_sets) {
return InitializeHorovodOnce(...);
}
bool horovod_init_multi_comm(MPI_Comm* comm, int ncomms,
const int* process_set_ranks_via_ranks,
const int* process_set_sizes_via_ranks,
int num_process_sets_via_ranks) {
return InitializeHorovodOnce(std::vector<int>(), process_set_ranks_vecs);
}
// 启动 horovod 后台进程,只执行一次
bool InitializeHorovodOnce(
const std::vector<int>& ranks,
const std::vector<std::vector<int>>& process_set_ranks) {
EnrichProcessSetWithMPIController(global_process_set);
if (!horovod_global.initialize_flag.test_and_set()) {
horovod_global.initialization_done = false;
horovod_global.background_thread =
std::thread(BackgroundThreadLoop, std::ref(horovod_global));
}
while (!horovod_global.initialization_done &&
!horovod_global.initialization_failed) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
// 初始化 controller,将 global 中的多个对象赋值给 controller
void EnrichProcessSetWithMPIController(ProcessSet& process_set) {
process_set.controller.reset(new MPIController(
process_set.response_cache, process_set.tensor_queue,
horovod_global.timeline, horovod_global.parameter_manager,
process_set.group_table, horovod_global.timeline_controller,
process_set.mpi_context));
}
void BackgroundThreadLoop(HorovodGlobalState& state) {
auto mpi_ctx_manager = MPIContextManager();
if (global_mpi_context.IsEnabled()) {
global_mpi_context.Initialize(mpi_ctx_manager);
if (state.control_operation == LibType::MPI) {
// Initializes global controller
state.process_set_table.Initialize(global_mpi_context);
}
}
bool is_coordinator = state.global_controller->IsCoordinator();
bool is_homogeneous = state.global_controller->IsHomogeneous();
int size = state.global_controller->GetSize();
int local_size = state.global_controller->GetLocalSize();
int local_rank = state.global_controller->GetLocalRank();
# 一堆配置
state.parameter_manager.SetTensorFusionThresholdBytes(128 * 1024 * 1024);
state.parameter_manager.SetTensorFusionThresholdBytes(threshold, true);
state.parameter_manager.SetCycleTimeMs(1);
state.parameter_manager.SetCacheEnabled(true);
state.process_set_table.Get(0).response_cache.set_capacity(...)
state.parameter_manager.SetHierarchicalAllgather(false);
state.parameter_manager.SetHierarchicalAllreduce(false);
while (RunLoopOnce(state));
state.shut_down = true;
horovod_global.process_set_table.Finalize(global_mpi_context,...)
}
bool RunLoopOnce(HorovodGlobalState& state) {
state.process_set_table.InitializeRegisteredAndRemoveMarkedIfReady(global_mpi_context);
for (auto process_set_id : state.process_set_table.Ids()) {
auto& process_set = state.process_set_table.Get(process_set_id);
auto response_list = process_set.IsCurrentProcessIncluded()
? process_set.controller->ComputeResponseList(this_process_requested_shutdown, state, process_set)
: ResponseList();
if (process_set.IsCurrentProcessIncluded()) {
int global_rank = state.global_controller->GetRank();
for (auto& response : response_list.responses()) {
PerformOperation(response, process_set);
}
}
}
}
这里主要包含两个操作
- process_set.controller->ComputeResponseList 处理通信前的协同
- PerformOperation 从 process_set 的 tensor_queue 中取出内容执行通信
PerformOperation
// 执行通信操作,获取 Response
void PerformOperation(Response response, ProcessSet& process_set) {
std::vector<TensorTableEntry> entries;
process_set.tensor_queue.GetTensorEntriesFromResponse(response, entries, process_set.joined);
if (response.response_type() != Response::JOIN &&
response.response_type() != Response::BARRIER) {
if (entries.size() > 1) {
auto first_entry = entries[0];
// 创建 buffer
Status status = horovod_global.fusion_buffer.InitializeBuffer(
process_set.controller->TensorFusionThresholdBytes(),
first_entry.device, first_entry.context,
horovod_global.current_nccl_stream,
[&]() { timeline.ActivityStartAll(entries, INIT_FUSION_BUFFER); },
[&]() { timeline.ActivityEndAll(entries); });
}
}
// std::unique_ptr<OperationManager> op_manager;
Status status = op_manager->ExecuteOperation(entries, response, process_set);
}
OperationManager->ExecuteOperation 即调用对应 api 完成 op 的执行
ComputeResponseList
这是 controller 里最重要的函数,它在 worker 间进行 allreduce/allgather 的协同,返回准备好通信的 tensor 列表,其中
- 0 号 worker 作为 coordinator
- 每个 worker 都存有一份别的 worker 发送的准备好的 tensor 列表作为 cache
具体流程如下
- worker 所有计划的通信操作都会先发送给 coordinator,Request 类型,包括 (tensor, reduce/gather, shape, type)
- worker 发送 DONE 消息给 coordinator 当所有计划通信操作都已发送
- coordinator 接受来自 worker 的计划通信请求,直到收集到所有节点的 DONE 消息
- coordinator 为准备好的 tensor 构建并向 worker 发送 Response 消息,当发送完毕时发送 DONE 消息
- worker 监听来自 coordinator 的消息,执行对应的 reduce/gather 操作,直到收到 DONE 消息
// horovod/common/controller.cc
ResponseList Controller::ComputeResponseList(bool this_process_requested_shutdown,
HorovodGlobalState& state,
ProcessSet& process_set) {
CacheCoordinator cache_coordinator(response_cache_.num_active_bits());
// tensor_queue_ --> message_queue_tmp
std::deque<Request> message_queue_tmp;
tensor_queue_.PopMessagesFromQueue(message_queue_tmp);
// cache 机制
// tensor_queue_.PushMessagesToQueue(messages_to_replace);
ResponseList response_list;
if (!need_communication) {
std::deque<Response> responses;
for (auto bit : cache_coordinator.cache_hits()) {
responses.push_back(response_cache_.get_response(bit));
}
FuseResponses(responses, state, response_list);
} else {
std::vector<std::string> ready_to_reduce;
if (is_coordinator_) { // 0 号 worker
// message_queue_tmp --> ready_to_reduce
while (!message_queue_tmp.empty()) {
Request message = message_queue_tmp.front();
ready_to_reduce.push_back(message.tensor_name());
}
// Receive ready tensors from other ranks
std::vector<RequestList> ready_list;
RecvReadyTensors(ready_to_reduce, ready_list); // ready_to_reduce 未实际使用
// ready_list +-> ready_to_reduce 即把各 worker 收集到的和自己的合并
for (int i = 1; i < size_; ++i) {
auto received_message_list = ready_list[i];
for (auto& received_message : received_message_list.requests()) {
auto& received_name = received_message.tensor_name();
ready_to_reduce.push_back(received_name);
}
}
// 到此准备通信的 tensor 准备完毕
std::deque<Response> responses;
for (auto& tensor_name : ready_to_reduce) {
Response response = ConstructResponse(tensor_name, process_set.joined_size);
responses.push_back(std::move(response));
}
FuseResponses(responses, state, response_list);
// Broadcast final results to other ranks.
SendFinalTensors(response_list);
} else { // 非 0 号 worker
RequestList message_list;
while (!message_queue_tmp.empty()) {
message_list.add_request(message_queue_tmp.front());
}
// Send ready tensors to rank zero
SendReadyTensors(message_list);
// Receive final tensors to be processed from rank zero
RecvFinalTensors(response_list);
}
}
return response_list;
}
调用和入 Queue
主要流程如下
- 通过入参 process_set_id 从 global state 的 process_set_table 中取出 process_set 对象
- 使用入参 Tensor tensors 和 outputs 封装 Request 和 TensorTableEntry
- 把上述封装列表添加到 process_set 对象的 tensor_queue 中
// horovod/common/operations.cc
Status
EnqueueTensorAllreduces(std::vector<std::shared_ptr<OpContext>>& contexts,
std::vector<std::shared_ptr<Tensor>>& tensors,
std::vector<std::shared_ptr<Tensor>>& outputs,
std::vector<ReadyEventList>& ready_event_lists,
std::vector<std::string>& names, const int device,
std::vector<StatusCallback>& callbacks,
ReduceOp reduce_op, double prescale_factor,
double postscale_factor, int32_t process_set_id) {
auto& process_set = horovod_global.process_set_table.Get(process_set_id);
Status status;
std::vector<Request> messages;
std::vector<TensorTableEntry> entries;
for (int n = 0; n < (int)tensors.size(); ++n) {
Request message;
message.set_xxxx(...);
messages.push_back(std::move(message));
TensorTableEntry e;
e.tensor = tensors[n];
e.output = outputs[n];
e.process_set_id = process_set_id;
entries.push_back(std::move(e));
}
status = process_set.tensor_queue.AddToTensorQueueMulti(entries, messages);
return status;
}
Object
Object 列表
- OperationManager
- HorovodGlobalState
- ParameterManager
- FusionBufferManager
- ProcessSet & ProcessSetTable
- Controller
- TensorQueue
- GroupTable
HorovodGlobalState
全局状态类,用于保存全局信息,同时持有以下几个对象
// horovod/common/global_state.h
struct HorovodGlobalState {
// Background thread running MPI communication.
std::thread background_thread;
bool elastic_enabled = false;
ParameterManager parameter_manager;
// handles resizing and auto-tuning of buffer size.
FusionBufferManager fusion_buffer;
ProcessSetTable process_set_table;
std::shared_ptr<Controller> global_controller;
};
ParameterManager
WHAT ParameterManager 会记录 tunable 的变量,包括时间和 fusion buffer size 等,然后以获得高吞吐为目标对其进程动态调整
Manager 类主要包含几个部分
- manager 自身的配置包括开关、warmup 信息等等
- API 包括 update、tune 等
- 对可调整参数的封装,包括调整对象和调整方法
- 调整策略, 基于上述封装,实现怎样调整的策略
// horovod/common/parameter_manager.h
class ParameterManager {
// 根据 tensor 信息计算 score 和调用 Tune 调整参数
// 返回值决定是否将更新后的参数广播出去
bool Update(const std::vector<std::string>& tensor_names, int64_t bytes);
// 根据 score 调整参数
bool Tune(double score);
// Manager 的配置
struct Params {
bool hierarchical_allreduce;
bool hierarchical_allgather;
bool cache_enabled;
double tensor_fusion_threshold;
double cycle_time;
bool active;
};
Params GetParams();
// Interface used to represent a parameter (or group of parameters) being tuned.
class ITunableParameter {
public:
virtual bool Tune(double score, double* best_score) = 0;
virtual void UpdateBestValue(double score) = 0;
virtual double BestScore() const = 0;
virtual bool IsTunable() const = 0;
};
// Abstract base class used to implement hierarchical parameter tuning.
template <class T>
class TunableParameter : public ITunableParameter {
TunableParameter(T initial_value);
T initial_value_;
T value_;
T best_value_;
};
// 需要调整的参数对象
std::vector<ITunableParameter*> parameter_chain_;
// A parameter that optimizes over a finite set of discrete values to be tried sequentially.
template <class T>
class CategoricalParameter : public TunableParameter<T> {
CategoricalParameter(std::vector<T> values);
std::vector<T> values_;
};
enum BayesianVariable { fusion_buffer_threshold_mb, cycle_time_ms };
struct BayesianVariableConfig {
BayesianVariable variable;
std::pair<double, double> bounds;
};
// A set of numerical parameters optimized jointly using Bayesian Optimization.
class BayesianParameter : public TunableParameter<Eigen::VectorXd> {
std::unique_ptr<BayesianOptimization> bayes_;
};
CategoricalParameter<bool> hierarchical_allreduce_;
CategoricalParameter<bool> hierarchical_allgather_;
CategoricalParameter<bool> cache_enabled_;
BayesianParameter joint_params_;
};
FusionBufferManager
这里的 Buffer 会伴随进程的整个生命周期
// horovod/common/fusion_buffer_manager.h
class FusionBufferManager {
public:
Status InitializeBuffer(int64_t threshold,
int device, std::shared_ptr<OpContext> context,
int stream_id,
std::function<void()> on_start_init,
std::function<void()> on_end_init);
// Status status = context->AllocatePersistent(threshold, &buffer);
std::shared_ptr<PersistentBuffer> GetBuffer(int device, Framework framework, int stream_id);
// map key: device ID, framework, stream_id
std::unordered_map<std::tuple<int, Framework, int>,
std::pair<std::shared_ptr<PersistentBuffer>, int64_t>> tensor_fusion_buffers_;
};
ProcessSet & ProcessSetTable
ProcessSet 持有以下对象
- Controller controller
- TensorQueue tensor_queue
- GroupTable group_table
基本调用流程
- HorovodGlobalState 中的 ProcessSetTable 对象
- ProcessSetTable Ids() 方法获取 ProcessSet 的 id
- ProcessSetTable Get() 方法从 id_to_process_set_ 变量中获取 ProcessSet 对象
- ProcessSet 的 IsCurrentProcessIncluded() 方法判断可见性
// horovod/common/process_set.h
struct ProcessSet {
std::shared_ptr<Controller> controller;
TensorQueue tensor_queue;
// LRU cache of Responses
ResponseCache response_cache;
// Information on registered groups.
GroupTable group_table;
std::vector<int> registered_global_ranks;
MPIContext mpi_context;
bool Initialize(const MPIContext& global_mpi_context);
void Finalize(const Status& status);
bool IsCurrentProcessIncluded() const;
explicit ProcessSet(std::vector<int> global_ranks = {});
};
class ProcessSetTable {
ProcessSetTable();
void Initialize(const MPIContext& global_mpi_context);
int32_t RegisterProcessSet(std::vector<int> global_ranks = {});
std::vector<int32_t> Ids() const; // Returns copy to be threadsafe
bool Contains(int32_t id) const;
ProcessSet& Get(int32_t id);
// Returns -1 if no process set with these ranks has been registered.
int32_t FindId(const std::vector<int32_t>& ranks);
void MarkProcessSetForRemoval(int32_t process_set_id);
void DeregisterProcessSet(int32_t process_set_id);
// ProcessSet 对象
std::unordered_map<int32_t, ProcessSet> id_to_process_set_;
};
Controller
Controller 持有以下对象需要在创建时传入,即外部依赖
- TensorQueue& tensor_queue_
- ResponseCache& response_cache_
- ParameterManager& parameter_manager_
- GroupTable& group_table_
class Controller : public std::enable_shared_from_this<Controller> {
void Initialize();
virtual int GetTypeSize(DataType dtype) = 0;
virtual void CrossRankBitwiseAnd(std::vector<long long>& bitvector, int count) = 0;
virtual void CrossRankBitwiseOr(std::vector<long long>& bitvector, int count) = 0;
virtual void Bcast(void* buffer, size_t size, int root_rank, Communicator communicator) = 0;
virtual void AlltoallGetRecvSplits(const std::vector<int32_t>& splits, std::vector<int32_t>& recvsplits) = 0;
virtual void Barrier(Communicator communicator) = 0;
virtual void Allgather2Ints(std::array<int, 2> values, std::vector<int>& recv_values) = 0;
void SynchronizeParameters();
ResponseList ComputeResponseList(bool this_process_requested_shutdown, HorovodGlobalState& state, ProcessSet& process_set);
virtual void DoInitialization() = 0;
// For rank 0 to receive other ranks' ready tensors.
virtual void RecvReadyTensors(std::vector<std::string>& ready_to_reduce,
std::vector<RequestList>& ready_list) = 0;
// For other ranks to send their ready tensors to rank 0
virtual void SendReadyTensors(RequestList& message_list) = 0;
// For rank 0 to send final tensors ready to be allreduced/allgathered to other ranks.
virtual void SendFinalTensors(ResponseList& response_list) = 0;
// For other ranks to receive final ready tensors.
virtual void RecvFinalTensors(ResponseList& response_list) = 0;
// Once a tensor is ready to be reduced, the coordinator sends a Response
// instructing all ranks to start the reduction to all ranks. The Response
// also contains error messages in case the submitted Requests were not
// valid (for example, contained mismatched shapes or types).
// Constructing the Response, thus, requires a whole lot of error checking.
Response ConstructResponse(const std::string& name, int joined_size = 0);
// Routine to sync cache hit and invalid bit sets across workers.
// Also determines global shutdown state and whether uncached requests
// exist on any worker.
void CoordinateCacheAndState(CacheCoordinator& cache_coordinator);
void FuseResponses(std::deque<Response>& responses,
HorovodGlobalState& state,
ResponseList& response_list);
// Return the total byte size of the final allgathered output tensor
int64_t
TotalByteSizeOfAllgatherOutput(const std::vector<int64_t>& tensor_sizes,
const TensorTableEntry& entry);
// Store the Request for a name, and return whether the total count of
// Requests for that tensor is now equal to the HOROVOD size (and thus we are
// ready to reduce the tensor).
bool IncrementTensorCount(const Request& msg, int joined_size = 0);
bool is_initialized_ = false;
int rank_ = 0;
int local_rank_ = 0;
int cross_rank_ = 0;
int size_ = 1;
int local_size_ = 1;
int cross_size_ = 1;
bool is_coordinator_ = false;
bool is_homogeneous_ = false;
// Global rank of each process in the set associated to this controller.
std::vector<int> global_ranks_;
// Map (global rank) -> (process set controller rank) for each process in this
// set.
std::unordered_map<int,int> global_rank_to_controller_rank_;
// Controller process set ranks of processes running on this node.
std::vector<int> local_comm_ranks_;
StallInspector stall_inspector_;
// Only exists on the coordinator node (rank zero). Maintains a vector of
// requests to allreduce every tensor (keyed by tensor name).
MessageTable message_table_;
// Outside dependencies
TensorQueue& tensor_queue_;
ResponseCache& response_cache_;
ParameterManager& parameter_manager_;
GroupTable& group_table_;
};
TensorQueue
TensorQueue 被 Controller 持有,主要包含两个对象
- Request 的对象 message_queue_,在 controller 中被取出做准备工作
- TensorTableEntry 对象 tensor_table_ 真正需要进行通信的 tensor
// horovod/common/tensor_queue.h
class TensorQueue {
TensorQueue() = default;
Status AddToTensorQueue(TensorTableEntry& e, Request& message);
Status AddToTensorQueueMulti(std::vector<TensorTableEntry>& entries, std::vector<Request>& messages);
void FinalizeTensorQueue(const Status& status);
int64_t GetTensorDataForAutotuner(const ResponseList& response_list,
std::vector<std::string>& tensor_names);
void GetTensorEntriesFromResponse(const Response& response,
std::vector<TensorTableEntry>& entries,
bool joined = false);
const TensorTableEntry& GetTensorEntry(const std::string& tensor_name) const;
bool IsTensorPresentInTable (const std::string& tensor_name) const;
void PopMessagesFromQueue(std::deque<Request>& message_queue_buffer);
void PushMessageToQueue(Request& message);
void PushMessagesToQueue(std::deque<Request>& messages);
void RemoveJoinTensor();
// Tensors waiting to be allreduced or allgathered.
std::unordered_map<std::string, TensorTableEntry> tensor_table_;
// Queue of MPI requests waiting to be sent to the coordinator node.
std::queue<Request> message_queue_;
};
GroupTable
在 ProcessSet 中持有,
- EnqueueTensorAllreduces 中调用 RegisterGroup
- RunLoopOnce 中 PerformOperation 前会调用 DeregisterGroups
// horovod/common/group_table.h
class GroupTable {
public:
GroupTable() = default;
int32_t GetGroupIDFromTensorName(const std::string& tensor_name) const;
const std::vector<std::string>& GetGroupTensorNames(int32_t group_id) const;
bool empty(void) const;
int32_t RegisterGroup(std::vector<std::string>&& tensor_names);
void DeregisterGroups(const std::vector<std::string>& tensor_names);
std::unordered_map<std::string, int32_t> tensor_name_to_id_;
std::unordered_map<int32_t, std::vector<std::string>> id_to_tensor_names_;
// Queue of ids that can be reused
std::queue<int32_t> free_ids_;
// Next available group id (increases each time a group is added)
int32_t next_group_id_ = 0;
};
OperationManager
对通信 op 的一个封装,基本上通过调用 op->Excute 实现,为 horovod/common/ops 目录中的各个 op 实现提供了接口。
// horovod/common/ops/operation_manager.h
class OperationManager {
OperationManager(ParameterManager* param_manager,
std::vector<std::shared_ptr<AllreduceOp>> allreduce_ops,
std::vector<std::shared_ptr<AllgatherOp>> allgather_ops,
std::vector<std::shared_ptr<BroadcastOp>> broadcast_ops,
std::vector<std::shared_ptr<AlltoallOp>> alltoall_ops,
std::vector<std::shared_ptr<ReducescatterOp>> reducescatter_ops,
std::shared_ptr<JoinOp> join_op,
std::vector<std::shared_ptr<AllreduceOp>> adasum_ops,
std::shared_ptr<BarrierOp> barrier_op,
std::shared_ptr<ErrorOp> error_op);
Status ExecuteAllreduce(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteAllgather(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteBroadcast(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteAlltoall(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteReducescatter(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteError(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteJoin(std::vector<TensorTableEntry>& entries,
const Response& response, ProcessSet& process_set) const;
Status ExecuteAdasum(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteBarrier(std::vector<TensorTableEntry>& entries, const Response& response) const;
Status ExecuteOperation(std::vector<TensorTableEntry>& entries,
const Response& response,
ProcessSet& process_set) const;
ParameterManager* param_manager_;
std::vector<std::shared_ptr<AllreduceOp>> allreduce_ops_;
std::vector<std::shared_ptr<AllgatherOp>> allgather_ops_;
std::vector<std::shared_ptr<BroadcastOp>> broadcast_ops_;
std::vector<std::shared_ptr<AlltoallOp>> alltoall_ops_;
std::vector<std::shared_ptr<ReducescatterOp>> reducescatter_ops_;
std::shared_ptr<JoinOp> join_op_;
std::vector<std::shared_ptr<AllreduceOp>> adasum_ops_;
std::shared_ptr<BarrierOp> barrier_op_;
std::shared_ptr<ErrorOp> error_op_;
};
Develop
这里列的 horovod 对象是用于二次开发的接口。
Horovod 对象
# horovod/common/common.h
enum Framework { TENSORFLOW, PYTORCH, MXNET, XLA };
enum StatusType { OK, UNKNOWN_ERROR, PRECONDITION_ERROR, ABORTED, INVALID_ARGUMENT, IN_PROGRESS };
enum DeviceType { CPU, GPU };
// for gpu
struct Event {
std::shared_ptr<gpuEvent_t> event;
uint64_t event_idx;
gpuStream_t stream = nullptr;
};
class Status {
public:
Status();
static Status OK();
static Status UnknownError(const std::string& message);
static Status PreconditionError(const std::string& message);
static Status Aborted(const std::string& message);
static Status InvalidArgument(const std::string& message);
static Status InProgress();
bool ok() const;
bool in_progress() const;
StatusType type() const;
const std::string& reason() const;
Event event;
private:
StatusType type_ = StatusType::OK;
std::string reason_;
Status(StatusType type, std::string reason);
};
class TensorShape {
public:
TensorShape() : shape_() {}
TensorShape(std::vector<int64_t> vec) : shape_(vec) {}
void AddDim(int64_t dim);
void AppendShape(TensorShape& other);
std::string DebugString() const;
int dims() const;
int64_t dim_size(int idx) const;
int64_t num_elements() const;
const std::vector<int64_t>& to_vector() const;
inline bool operator==(const TensorShape& rhs) const {
return shape_ == rhs.shape_;
}
inline bool operator!=(const TensorShape& rhs) const {
return shape_ != rhs.shape_;
}
private:
std::vector<int64_t> shape_;
};
class ReadyEvent {};
class ReadyEventList {};
class PersistentBuffer {
public:
virtual const void* AccessData(std::shared_ptr<OpContext> context) const = 0;
virtual ~PersistentBuffer() = default;
};
class Tensor {
public:
virtual const DataType dtype() const = 0;
virtual const TensorShape shape() const = 0;
virtual const void* data() const = 0;
virtual int64_t size() const = 0;
virtual ~Tensor() = default;
};
class OpContext {
public:
// These allocators are fully synchronous, unlike TensorFlow counterparts.
virtual Status
AllocatePersistent(int64_t size,
std::shared_ptr<PersistentBuffer>* tensor) = 0;
virtual Status AllocateOutput(TensorShape shape,
std::shared_ptr<Tensor>* tensor,
std::shared_ptr<ReadyEvent>* event = nullptr) = 0;
virtual Status AllocateOutput(int output_index, TensorShape shape,
std::shared_ptr<Tensor>* tensor,
std::shared_ptr<ReadyEvent>* event = nullptr) {
if (output_index == 0) {
return AllocateOutput(std::move(shape), tensor);
} else {
throw std::logic_error("output_index != 0 not supported");
}
}
virtual Status AllocateZeros(int64_t num_elements, DataType dtype,
std::shared_ptr<Tensor>* tensor) = 0;
virtual Framework framework() const = 0;
virtual ~OpContext() = default;
};
// A callback to call after the communication completes. Since the
// allreduce and allgather ops are asynchronous, this callback is what resumes
// computation after the reduction is completed.
using StatusCallback = std::function<void(const Status&)>;
// Table storing Tensors to be reduced, keyed by unique name.
// This table contains everything necessary to do the distributed operation.
struct TensorTableEntry {
std::string tensor_name;
std::shared_ptr<OpContext> context;
std::shared_ptr<Tensor> tensor;
std::shared_ptr<Tensor> output;
// Identifier for the subset of Horovod processes partaking in this operation.
int32_t process_set_id = 0;
// Root rank for broadcast operation (relative to process set).
int root_rank = 0;
// List of events indicating that data is ready.
ReadyEventList ready_event_list;
// GPU to do reduction on, or CPU_DEVICE_ID in case of CPU.
int device = CPU_DEVICE_ID;
// A callback to call with the status.
StatusCallback callback;
// If we build with NVTX support: A range marking the start
// and end of the distributed op for this tensor (may be
// shared by multiple tensors).
SharedNvtxOpRange nvtx_op_range;
// Alltoall splits (if tensor is for an Alltoall operation)
// Note: splits are stored in TensorTableEntry to avoid N^2
// storage complexity of collecting all worker split arrays
// on coordinator rank.
std::vector<int32_t> splits;
std::shared_ptr<Tensor> received_splits;
void FinishWithCallback(const Status& status);
};
Message
Request
// horovod/common/message.h
// Request 是非 0 worker 向 0 号 worker 即 coordinator 发送消息的消息体
class Request {
enum RequestType {
ALLREDUCE = 0,
ALLGATHER = 1,
BROADCAST = 2,
JOIN = 3,
ADASUM = 4,
ALLTOALL = 5,
BARRIER = 6,
REDUCESCATTER = 7
};
static const std::string& RequestType_Name(RequestType value);
int32_t request_rank() const;
void set_request_rank(int32_t value);
RequestType request_type() const;
void set_request_type(RequestType value);
DataType tensor_type() const;
void set_tensor_type(DataType value);
const std::string& tensor_name() const;
void set_tensor_name(const std::string& value);
int32_t root_rank() const;
void set_root_rank(int32_t value);
int32_t device() const;
void set_device(int32_t value);
int32_t group_id() const;
void set_group_id(int32_t value);
const std::vector<int64_t>& tensor_shape() const;
void set_tensor_shape(const std::vector<int64_t>& value);
void add_tensor_shape(int64_t value);
double prescale_factor() const;
double postscale_factor() const;
void set_prescale_factor(double prescale_factor);
void set_postscale_factor(double postscale_factor);
static void ParseFromBytes(Request& request, const uint8_t* input);
static void SerializeToString(const Request& request, std::string& output);
int32_t request_rank_ = 0;
RequestType request_type_ = RequestType::ALLREDUCE;
DataType tensor_type_ = DataType::HOROVOD_UINT8;
int32_t root_rank_ = 0;
int32_t device_ = 0;
int32_t group_id_ = NULL_GROUP_ID;
std::string tensor_name_;
std::vector<int64_t> tensor_shape_;
double prescale_factor_ = 1.0;
double postscale_factor_ = 1.0;
};
class RequestList {
const std::vector<Request>& requests() const;
void set_requests(const std::vector<Request>& value);
void add_request(const Request& value);
void emplace_request(Request&& value);
bool shutdown() const;
void set_shutdown(bool value);
static void ParseFromBytes(RequestList& request_list, const uint8_t* input);
static void SerializeToString(const RequestList& request_list, std::string& output);
std::vector<Request> requests_;
bool shutdown_ = false;
};
Response
// Response 是 0 号 worker 即 coordinator 向非 0 worker 发送消息的消息体
class Response {
public:
enum ResponseType {
ALLREDUCE = 0,
ALLGATHER = 1,
BROADCAST = 2,
JOIN = 3,
ADASUM = 4,
ALLTOALL = 5,
BARRIER = 6,
REDUCESCATTER = 7,
ERROR = 8
};
static const std::string& ResponseType_Name(ResponseType value);
ResponseType response_type() const;
void set_response_type(ResponseType value);
const std::vector<std::string>& tensor_names() const;
DataType tensor_type() const;
void set_tensor_type(DataType value);
const std::string tensor_names_string() const;
void set_tensor_names(const std::vector<std::string>& value);
void add_tensor_name(const std::string& value);
void add_tensor_name(std::string&& value);
const std::string& error_message() const;
void set_error_message(const std::string& value);
const std::vector<int32_t>& devices() const;
void set_devices(const std::vector<int32_t>& value);
void add_device(int32_t value);
const std::vector<int64_t>& tensor_sizes() const;
void set_tensor_sizes(const std::vector<int64_t>& value);
void add_tensor_size(int64_t value);
void add_allgather_response(const Response& response);
double prescale_factor() const;
double postscale_factor() const;
void set_prescale_factor(double prescale_factor);
void set_postscale_factor(double postscale_factor);
int last_joined_rank() const;
void set_last_joined_rank(int value);
static void ParseFromBytes(Response& response, const uint8_t* input);
static void SerializeToString(const Response& response, std::string& output);
ResponseType response_type_ = ResponseType::ALLREDUCE;
std::vector<std::string> tensor_names_;
DataType tensor_type_ = DataType::HOROVOD_UINT8;
std::string error_message_;
std::vector<int32_t> devices_;
std::vector<int64_t> tensor_sizes_;
double prescale_factor_ = 1.0;
double postscale_factor_ = 1.0;
int last_joined_rank_ = -1;
};
class ResponseList {
const std::vector<Response>& responses() const;
void set_responses(const std::vector<Response>& value);
void add_response(const Response& value);
void add_response(Response&& value);
void emplace_response(Response&& value);
bool shutdown() const;
void set_shutdown(bool value);
static void ParseFromBytes(ResponseList& response_list, const uint8_t* input);
static void SerializeToString(const ResponseList& response_list, std::string& output);
std::vector<Response> responses_;
bool shutdown_ = false;
};
ResponseCache
// horovod/common/response_cache.h
struct TensorParams {
DataType dtype;
std::vector<int64_t> shape;
int32_t device;
};
// LRU cache of Responses
class ResponseCache {
public:
ResponseCache() = default;
ResponseCache(const ResponseCache&) = delete;
enum CacheState { MISS = 0, HIT = 1, INVALID = 2 };
void clear();
void set_capacity(uint32_t capacity);
uint32_t capacity() const;
size_t num_active_bits() const;
CacheState cached(const Request& message) const;
CacheState cached(const Response& response, const TensorParams& params,
bool joined = false) const;
void put(const Response& response, TensorQueue& tensor_queue,
bool joined = false);
const Response& get_response(uint32_t cache_bit);
const Response& peek_response(uint32_t cache_bit) const;
uint32_t peek_cache_bit(const Request& message) const;
uint32_t peek_cache_bit(const std::string& tensor_name) const;
std::vector<uint32_t> list_all_bits() const;
void erase_response(uint32_t cache_bit);
void update_cache_bits();
private:
void put_(const Response& response, TensorParams& params,
bool joined = false);
uint32_t capacity_ = 0;
// List containing cached entries. Each entry in the cache is a pair
// of a Response and a TensorParams struct.
std::list<std::pair<Response, TensorParams>> cache_;
// Vector of iterators to cache entries. Indexed by cache bit.
std::vector<std::list<std::pair<Response, TensorParams>>::iterator>
cache_iters_;
// Lookup table mapping tensor names to assigned cache bits.
std::unordered_map<std::string, uint32_t> tensor_name_to_bit_;
bool bits_outdated_ = false;
bool print_warning_ = true;
};
// Helper class to coordinate cache and state information
// across workers. Uses global controller operations on a bit vector
// for cheaper coordination.
class CacheCoordinator {
public:
explicit CacheCoordinator(size_t num_active_bits_);
void record_hit(uint32_t bit);
void record_invalid_bit(uint32_t bit);
void erase_hit(uint32_t bit);
void set_should_shut_down(bool should_shut_down);
void set_uncached_in_queue(bool uncached_in_queue);
const std::set<uint32_t>& cache_hits() const;
const std::set<uint32_t>& invalid_bits() const;
const std::set<uint32_t>& timeline_bits() const;
bool should_shut_down() const;
bool uncached_in_queue() const;
// Method to sync state and bit sets across workers.
void sync(std::shared_ptr<Controller> controller, bool timeline_enabled);
private:
enum StatusBit {
SHOULD_SHUT_DOWN = 0,
UNCACHED_IN_QUEUE = 1,
INVALID_IN_QUEUE = 2
};
// Number of active bits in the cache. Required to size the
// bitvector identically across workers.
size_t num_active_bits_;
// Set of cache hit bits. After sync(), contains only common
// cache hit bits across workers.
std::set<uint32_t> cache_hits_;
// Set of invalid bits. After sync(), contains only common
// invalid bits across workers.
std::set<uint32_t> invalid_bits_;
// Set of bits for timeline handling. After sync(), contains bits
// where at least one worker recorded a cache hit. This indicates
// that the timeline negotion phase should be started/continued.
std::set<uint32_t> timeline_bits_;
// States used externally in cycle loop.
bool should_shut_down_ = false;
bool uncached_in_queue_ = false;
// State used internally to trigger second bit vector communication
// to sync invalid bits.
bool invalid_in_queue_ = false;
std::vector<long long> bitvector_;
bool synced_ = false;
};
PyTorch
API
horovod.torch api
大部分 api 从 mpi_ops 中引入
# horovod/torch/__init__.py
from horovod.torch import elastic
from horovod.torch.compression import Compression
from horovod.torch.functions import allgather_object, broadcast_object, broadcast_optimizer_state, broadcast_parameters
from horovod.torch.mpi_ops import allreduce, allreduce_async, allreduce_, allreduce_async_
from horovod.torch.mpi_ops import grouped_allreduce, grouped_allreduce_async, grouped_allreduce_, grouped_allreduce_async_
from horovod.torch.mpi_ops import sparse_allreduce_async
from horovod.torch.mpi_ops import allgather, allgather_async
from horovod.torch.mpi_ops import broadcast, broadcast_async, broadcast_, broadcast_async_
from horovod.torch.mpi_ops import alltoall, alltoall_async
from horovod.torch.mpi_ops import reducescatter, reducescatter_async
from horovod.torch.mpi_ops import join
from horovod.torch.mpi_ops import barrier
from horovod.torch.mpi_ops import poll, synchronize
from horovod.torch.mpi_ops import init, shutdown
from horovod.torch.mpi_ops import is_initialized, start_timeline, stop_timeline
from horovod.torch.mpi_ops import size, local_size, cross_size, rank, local_rank, cross_rank
from horovod.torch.mpi_ops import mpi_threads_supported, mpi_enabled, mpi_built
from horovod.torch.mpi_ops import gloo_enabled, gloo_built
from horovod.torch.mpi_ops import nccl_built, ddl_built, ccl_built, cuda_built, rocm_built
from horovod.torch.mpi_ops import ProcessSet, global_process_set, add_process_set, remove_process_set
from horovod.torch.mpi_ops import Average, Sum, Adasum
from horovod.torch.optimizer import DistributedOptimizer
from horovod.torch.sync_batch_norm import SyncBatchNorm
mpi_ops
这里的 api 分为两部分
- 一部分从 mpi_lib_v2 library 中通过 C api 暴露,然后通过 basic 引入
- 通信 api 通过 pybind 调用
# horovod/torch/mpi_ops.py
# so library
from horovod.torch import mpi_lib_v2 as mpi_lib
_basics = _HorovodBasics(__file__, 'mpi_lib_v2')
# import basic methods
# mpi_ops 中会包含 basic 中的 api
# 重要
# handle 会被放在 map 中,避免被 gc
# 在 synchronize 之后被释放
_handle_map = {}
# inplace allreduce
# allreduce_ -> allreduce_async_ + synchronize -> _allreduce_async -> mpi_lib.horovod_torch_allreduce_async_
# allreduce
# allreduce -> HorovodAllreduce.apply -> allreduce_async + synchronize -> _allreduce_async -> mpi_lib.horovod_torch_allreduce_async_
def _allreduce_function_factory(tensor):
return 'horovod_torch_allreduce_async_' + tensor.type().replace('.', '_')
def _allreduce_async(tensor, output, name, op, prescale_factor, postscale_factor, process_set: ProcessSet):
function = _check_function(_allreduce_function_factory, tensor)
try:
handle = getattr(mpi_lib, function)(tensor, output, divisor,
name.encode() if name is not None else _NULL, op,
prescale_factor, postscale_factor, process_set.process_set_id)
except RuntimeError as e:
raise HorovodInternalError(e)
return handle
def allreduce_async(tensor, average=None, name=None, op=None,
prescale_factor=1.0, postscale_factor=1.0,
process_set=global_process_set):
output = tensor.new(tensor.shape)
return _allreduce_async(tensor, output, name, op, prescale_factor, postscale_factor, process_set)
class HorovodAllreduce(torch.autograd.Function):
@staticmethod
def forward(ctx, tensor, average, name, op, prescale_factor, postscale_factor, process_set):
ctx.average = average
ctx.op = op
ctx.prescale_factor = prescale_factor
ctx.postscale_factor = postscale_factor
ctx.process_set = process_set
handle = allreduce_async(tensor, average, name, op, prescale_factor, postscale_factor, process_set)
return synchronize(handle)
@staticmethod
def backward(ctx, grad_output):
return allreduce(grad_output, average=ctx.average, op=ctx.op,
prescale_factor=ctx.prescale_factor,
postscale_factor=ctx.postscale_factor,
process_set=ctx.process_set), None, None, None, None, None, None
def allreduce(tensor, average=None, name=None, compression=Compression.none, op=None,
prescale_factor=1.0, postscale_factor=1.0, process_set=global_process_set):
"""
This acts as a thin wrapper around an autograd function. If your input
tensor requires gradients, then callings this function will allow gradients
to be computed and backpropagated.
"""
tensor_compressed, ctx = compression.compress(tensor)
summed_tensor_compressed = HorovodAllreduce.apply(tensor_compressed, average, name, op,
prescale_factor, postscale_factor,
process_set)
return compression.decompress(summed_tensor_compressed, ctx)
def allreduce_async_(tensor, average=None, name=None, op=None,
prescale_factor=1.0, postscale_factor=1.0,
process_set=global_process_set):
op = handle_average_backwards_compatibility(op, average)
return _allreduce_async(tensor, tensor, name, op, prescale_factor, postscale_factor, process_set)
def allreduce_(tensor, average=None, name=None, op=None,
prescale_factor=1.0, postscale_factor=1.0,
process_set=global_process_set):
handle = allreduce_async_(tensor, average, name, op, prescale_factor, postscale_factor, process_set)
return synchronize(handle)
这里最终调用的例如 mpi_lib.horovod_torch_allreduce_async_ api 来自 cpp api 的 pybind.
cpp api
// horovod/torch/mpi_ops_v2.cc
PYBIND11_MODULE(mpi_lib_v2, m) {
m.def("horovod_torch_allreduce_async_torch_IntTensor", &DoAllreduce);
...
}
int DoAllreduce(::torch::Tensor tensor, ::torch::Tensor output, int divisor,
const std::string& name, int reduce_op_int,
double prescale_factor, double postscale_factor,
int process_set_id) {
auto handle = handle_manager.AllocateHandle();
common::ReadyEventList ready_event_list;
auto hvd_tensor = std::make_shared<TorchTensor>(tensor);
auto hvd_context = std::make_shared<TorchOpContext>(device, output);
auto hvd_output = std::make_shared<TorchTensor>(output);
ReduceOp reduce_op = static_cast<ReduceOp>(reduce_op_int);
auto enqueue_result = EnqueueTensorAllreduce(hvd_context, hvd_tensor, hvd_output, ready_event_list, ... handle);
return handle;
}
这里主要包括两个内容
- torch tensor 到 horovod tensor 的转换
- 调用来自 horovod/common/operations.h 的
EnqueueTensorAllreduce将计划通信的 tensor 加入队列
HandleManager
HandleManager 用于记录通信操作的返回结果 Status, 通过它可以知道操作完成情况和进行同步。
// horovod/torch/handle_manager.h
class HandleManager {
std::unordered_map<int, std::shared_ptr<Status>> results_;
};
TorchTensor
TorchTensor 是 horovod tensor 的子类,它实现了对应的接口,horovod 的通信中可以直接使用该对象.
// horovod/torch/adapter_v2.h
class TorchPersistentBuffer : public PersistentBuffer {
AccessData(std::shared_ptr<OpContext> context) const override;
::torch::Tensor tensor_;
};
class TorchTensor : public Tensor {
::torch::Tensor tensor_;
};
class TorchOpContext : public OpContext {
std::vector<::torch::Tensor> outputs_;
};
Develop
总结 PyTorch 接入 Horovod 框架需要做的工作
- API 封装,暴露拓展的 API 给用户,可以使用 torch 的 tensor 作为参数传递等;在
horovod/torch/mpi_ops.py中实现 - API 对接,前端 API 调用 horovod API 以及绑定 py API;在
horovod/torch/mpi_ops_v2.cc中实现 - Tensor 适配,即 torch 的 tensor 能够在 horovord 框架中使用;在
horovod/torch/adapter_v2.*中实现
DistributedOptimizer
Demo
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.synchronize()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
with optimizer.skip_synchronize():
optimizer.step()
class _DistributedOptimizer(torch.optim.Optimizer):
def __init__(self, ...):
self._register_hooks()
def _register_hooks(self):
for param_group in self.param_groups:
for p in param_group['params']:
if p.requires_grad:
self._requires_update.add(p)
# p_tmp 和 p 使用同样的 storage,不占用额外显存
p_tmp = p.expand_as(p)
grad_acc = p_tmp.grad_fn.next_functions[0][0]
grad_acc.register_hook(self._make_hook(p))
self._grad_accs.append(grad_acc)
def _make_hook(self, p):
def hook(*ignore):
handle, ctx = None, None
self._allreduce_delay[p] -= 1
if self._allreduce_delay[p] == 0:
handle, ctx = self._allreduce_grad_async(p)
self._handles[p] = (handle, ctx)
return hook
def _allreduce_grad_async(self, p):
name = self._parameter_names.get(p)
tensor = p.grad
if p.grad.is_sparse:
if self.sparse_as_dense:
tensor = tensor.to_dense()
else:
return self._sparse_allreduce_grad_async(p, name)
tensor_compressed, ctx = self._compression.compress(tensor)
handle = allreduce_async_(tensor_compressed, name=name, op=self.op,
prescale_factor=prescale_factor,
postscale_factor=postscale_factor,
process_set=self.process_set)
return handle, ctx
def _sparse_allreduce_grad_async(self, p, name):
handle = sparse_allreduce_async(p.grad, name=name, op=self.op,
process_set=self.process_set)
return handle, None
def synchronize(self):
if not self.process_set.included():
self._synchronized = True
return
completed = set()
for x in self._handles.keys():
completed.update(x) if isinstance(x, tuple) else completed.add(x)
missing_p = self._requires_update - completed
# 处理 hook 注册不成功,或者说 hook 没有被调用
# hook 被调用后会添加 self._handles
for p in missing_p:
handle, ctx = self._allreduce_grad_async(p)
self._handles[p] = (handle, ctx)
# handle 为 None 的 hook 跳过又不跳过了?
# 需要注意 synchronize 函数每个 step 被调用,但不是每次 backward 都会被调用
# 在之前的 train 中有每个 step 会多次 backward,所以 grad 的 hook 会被多次调用,次数匹配
# 所以代码执行到这里 handle 应该是一次调用_allreduce_grad_async 如果不是就补上
for p, (handle, ctx) in self._handles.items():
if handle is None:
handle, ctx = self._allreduce_grad_async(p)
self._handles[p] = (handle, ctx)
# for 循环处理异步通信的结果
for p, (handle, ctx) in self._handles.items():
# When handle is a callable function, it returns the aggregated tensor result
output = synchronize(handle) if not callable(handle) else handle()
self._allreduce_delay[p] = self.backward_passes_per_step
if p.grad.is_sparse:
aggregated = self._compression.decompress(output, ctx)
if not aggregated.is_sparse:
aggregated = aggregated.to_sparse()
# Sparse grads do not support set_ for some reason, so we do this as an equivalent
p.grad.zero_().add_(aggregated)
else:
p.grad.set_(self._compression.decompress(output, ctx))
self._handles.clear()
self._synchronized = True
def DistributedOptimizer(optimizer, named_parameters=None,
compression=Compression.none,
backward_passes_per_step=1,
op=Average,
gradient_predivide_factor=1.0,
num_groups=0, groups=None,
sparse_as_dense=False,
process_set=global_process_set):
if op != Adasum or size() == 1:
cls = type(optimizer.__class__.__name__, (optimizer.__class__,),
dict(_DistributedOptimizer.__dict__))
return cls(optimizer.param_groups, named_parameters, compression, backward_passes_per_step, op,
gradient_predivide_factor, groups, sparse_as_dense, process_set)
else:
cls = type(optimizer.__class__.__name__, (optimizer.__class__,),
dict(_DistributedAdasumOptimizer.__dict__))
return cls(optimizer.param_groups, named_parameters, compression, backward_passes_per_step)
Adasum 是 allreduce 时一种计算合并 gradient 的方法,可以让结果更加稳定。
Tensorflow
Demo
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
# horovod/tensorflow/mpi_ops.py
def init(*args, **kwargs):
_basics.init(*args, **kwargs)
_setup_process_sets(_basics)
Elastic
弹性启动
前述接正常启动部分,弹性使用 gloo 启动
def _run_elastic(args):
settings = elastic_settings.ElasticSettings(discovery=discover_hosts,...)
return gloo_run_elastic(settings, env, args.run_func if args.run_func else args.command, executable)
from horovod.runner.gloo_run import gloo_run, gloo_run_elastic
# horovod/runner/gloo_run.py
def gloo_run_elastic(settings, env, command_or_func, executable) -> Optional[Any]:
rendezvous = RendezvousServer(settings.verbose)
return launch_gloo_elastic(command_or_func, exec_command, settings, env, get_common_interfaces, rendezvous, executable)
def launch_gloo_elastic(command_or_func, exec_command, settings, env, get_common_interfaces, rendezvous, executable):
driver = ElasticDriver(rendezvous, settings.discovery,
settings.min_num_proc, settings.max_num_proc,
timeout=settings.elastic_timeout,
reset_limit=settings.reset_limit,
cooldown_range=settings.cooldown_range,
verbose=settings.verbose)
handler = create_rendezvous_handler(driver)
global_rendezv_port = rendezvous.start(handler)
driver.wait_for_available_slots(settings.num_proc)
run_command = get_run_command(command, server_ip, nics, global_rendezv_port, elastic=True)
create_worker = _create_elastic_worker_fn(exec_command, run_command, env, event)
driver.start(settings.num_proc, create_worker)
res = driver.get_results()
driver.stop()
Driver
ElasticDriver 中有两个线程
- 一个线程 while 循环执行
_discover_hosts监控、报告节点更新 - 一个线程执行
run_worker启动 worker
注意 driver 不会阻塞,启动 worker 后返回 launch 函数,等待获取 results, 具体地,driver.get_results() 是一个 while 循环会造成阻塞。
# horovod/runner/elastic/driver.py
class ElasticDriver(object):
def __init__(self, rendezvous, ...):
self._worker_registry = WorkerStateRegistry(self, self._host_manager, reset_limit=reset_limit)
self._results = ResultsRecorder()
self._discovery_thread = threading.Thread(target=self._discover_hosts)
def start(self, num_proc, create_worker_fn):
self._activate_workers(num_proc)
def get_results(self):
return self._results.get_results()
def register_worker_server(self, host, slot, addresses, secret_key):
self._worker_clients[(host, slot)] = WorkerNotificationClient(
addresses, secret_key, self._verbose)
def _activate_workers(self, min_num_proc):
current_hosts = self.wait_for_available_slots(min_num_proc)
pending_slots = self._update_host_assignments(current_hosts)
self._worker_registry.reset(self.world_size())
self._start_worker_processes(pending_slots)
def _discover_hosts(self):
while not self._shutdown.is_set():
self._wait_hosts_cond.acquire()
try:
update_res = self._host_manager.update_available_hosts()
if update_res != HostUpdateResult.no_update:
self._notify_workers_host_changes(self._host_manager.current_hosts, update_res)
self._wait_hosts_cond.notify_all()
finally:
self._wait_hosts_cond.release()
self._shutdown.wait(DISCOVER_HOSTS_FREQUENCY_SECS)
def _notify_workers_host_changes(self, current_hosts, update_res):
coordinator_client.notify_hosts_updated(timestamp, update_res)
def _start_worker_processes(self, pending_slots):
for slot_info in pending_slots:
self._start_worker_process(slot_info)
def _start_worker_process(self, slot_info):
def run_worker():
res = create_worker_fn(slot_info, [shutdown_event, host_event])
exit_code, timestamp = res
self._handle_worker_exit(slot_info, exit_code, timestamp)
thread = threading.Thread(target=run_worker)
thread.daemon = True
thread.start()
self._results.expect(thread)
Usage
hvd.init()
torch.cuda.set_device(hvd.local_rank())
dataset = ...
model = ...
optimizer = optim.SGD(model.parameters(), lr * hvd.size())
optimizer = hvd.DistributedOptimizer(optimizer)
@hvd.elastic.run
def train(state):
batch_offset = state.batch
for state.epoch in range(state.epoch, epochs):
for state.batch in range(state.batch, batches_per_epoch):
data, target = get_random_batch()
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if state.batch % batches_per_commit == 0:
state.commit()
state.batch = 0
def on_state_reset():
# adjust learning rate on reset
for param_group in optimizer.param_groups:
param_group['lr'] = lr * hvd.size()
state = hvd.elastic.TorchState(model, optimizer, batch=0, epoch=0)
state.register_reset_callbacks([on_state_reset])
train(state)
Implementation
在训练的循环函数上会有装饰器,用于识别错误和自身的恢复,另外通过 notification_manager 别的节点也会感知到错误的发生。
# horovod/common/elastic.py
notification_manager = WorkerNotificationManager()
def run_fn(func, reset):
@functools.wraps(func)
def wrapper(state, *args, **kwargs):
notification_manager.init()
notification_manager.register_listener(state)
try:
while True:
try:
if not skip_sync:
state.sync()
return func(state, *args, **kwargs)
except HorovodInternalError:
state.restore()
skip_sync = False
except HostsUpdatedInterrupt as e:
skip_sync = e.skip_sync
reset()
state.on_reset()
return wrapper
# horovod/common/elastic.py
class State(object):
def register_reset_callbacks(self, callbacks):
pass
def on_reset(self):
self._host_messages = queue.Queue()
self.reset()
for callback in self._reset_callbacks:
callback()
def on_hosts_updated(self, timestamp, update_res):
self._host_messages.put((timestamp, update_res))
def commit(self):
self.save()
self.check_host_updates()
def check_host_updates(self):
raise HostsUpdatedInterrupt(all_update == HostUpdateResult.removed)
def save(self):
pass
def restore(self):
pass
def sync(self):
pass
def reset(self):
pass
class ObjectState(State):
def restore(self):
self._set_attrs()
def sync(self):
if self._saved_state:
self._saved_state = self._bcast_object(self._saved_state)
self._set_attrs()
# horovod/torch/elastic/state.py
class TorchState(ObjectState):
def restore(self):
for handler in self._handlers.values():
handler.restore()
super(TorchState, self).restore()
因为 hvd.init() 之后,一直会有后台进程在负责真正的通信过程,在有节点变化时,通信组需要重建,具体实现如下。
// horovod/common/operations.cc
bool RunLoopOnce(HorovodGlobalState& state) {
if (state.dynamic_process_sets) {
// Initialize any newly added process set that has been registered by all
// Horovod processes and remove a process set that has been marked for
// removal by all Horovod processes.
if (state.control_operation == LibType::GLOO) {
state.process_set_table.InitializeRegisteredAndRemoveMarkedIfReady(
global_gloo_context);
}
}
}
Reinitialize Horovod context performing a new round of rendezvous.
负责重建通信域
// horovod/common/process_set.cc
template <class Context>
int32_t ProcessSetTable::InitializeRegisteredAndRemoveMarkedIfReady_(
const Context& global_context, const Status& removal_status) {
if (registered_count_agreement) {
for (auto id : Ids()) {
bool newly_registered = Get(id).Initialize(global_context);
}
}
if (id_to_be_removed_agreement) {
id_to_process_set_[id_to_be_removed_].Finalize(removal_status);
DeregisterProcessSet(id_to_be_removed_);
}
}
ProcessSetTable::ProcessSetTable() {
auto process_set_id = RegisterProcessSet();
}
int32_t ProcessSetTable::RegisterProcessSet(std::vector<int> global_ranks) {
// ProcessSet
ids_.push_back(id);
}
bool ProcessSet::Initialize(const GlooContext& global_gloo_context) {
gloo_context.InitializeForProcessSet(global_gloo_context,
registered_global_ranks);
}
// horovod/common/gloo/gloo_context.cc
void GlooContext::InitializeForProcessSet(const GlooContext& global_context,
const std::vector<int>& registered_ranks) {
ctx = Rendezvous(HOROVOD_GLOO_GLOBAL_PREFIX + process_set_suffix,
rendezvous_addr_env, rendezvous_port, rank, size, dev,
timeout_);
}
接口的调用顺序
# horovod/common/process_sets.py
def add_process_set(process_set: Union[ProcessSet, Sequence[int]]) -> ProcessSet:
process_set_id = _basics._add_process_set_impl(process_set.ranks)
# horovod/common/basics.py
class HorovodBasics(object):
def _add_process_set_impl(self, ranks: Sequence[int]) -> Optional[int]:
result = int(self.MPI_LIB_CTYPES.horovod_add_process_set(
(ctypes.c_int * nrank)(*ranks), ctypes.c_int(nrank)))
// horovod/common/operations.cc
int horovod_add_process_set(const int* ranks, int nrank) {
ProcessSet* process_set = nullptr;
{
process_set = &GetProcessSetOrAddUnitialized(
ranks && nrank > 0 ? std::vector<int>(ranks, ranks + nrank) : std::vector<int>(),
id);
}
}
ProcessSet& GetProcessSetOrAddUnitialized(std::vector<int> ranks, int& id) {
id = horovod_global.process_set_table.FindId(ranks);
id = horovod_global.process_set_table.RegisterProcessSet(std::move(ranks));
auto& process_set = horovod_global.process_set_table.Get(id);
EnrichProcessSetWithGlooController(process_set);
}
void EnrichProcessSetWithGlooController(ProcessSet& process_set) {
process_set.controller.reset(new GlooController(
process_set.response_cache, process_set.tensor_queue,
horovod_global.timeline, horovod_global.parameter_manager,
process_set.group_table, horovod_global.timeline_controller,
process_set.gloo_context));
}
Workflow Summary
hvd.elastic.rundecorator- process
HorovodInternalError - reinitialize context, new rendezvous
- restore state, broadcasting from new worker-0
Reference
- https://horovod.readthedocs.io/en/stable/elastic_include.html
Ray
Reference
源代码和官方文档永远是最好的学习资料,总结和学习笔记能辅助快速理解,抓住重点,提高效率。
| API | Description | Example |
|---|---|---|
| ray.init() | Initialize Ray context. | |
| @ray.remote | Function or class decorator specifying that the function will be executed as a task or the class as an actor in a different process. | @ray.remote @ray.remote def fun(x): class Actor(object): … def method(y) … |
| .remote | Postfix to every remote function, remote class declaration, or invocation of a remote class method. Remote operations are asynchronous. | ret_id = fun.remote(x) a = Actor.remote() ret_id = a.method.remote(y) |
| ray.put() | Store object in object store, and return its ID. This ID can be used to pass object as an argument to any remote function or method call. This is a synchronous operation. | x_id = ray.put(x) |
| ray.get() | Return an object or list of objects from the object ID or list of object IDs. This is a synchronous (i.e., blocking) operation. | x = ray.get(x_id) … objects = ray.get(object_ids) |
| ray.wait() | From a list of object IDs returns (1) the list of IDs of the objects that are ready, and (2) the list of IDs of the objects that are not ready yet. By default it returns one ready object ID at a time. | ready_ids, not_ready_ids = ray.wait(object_ids) |
特点
- 分布式异步调用
- 内存调度
- Pandas/Numpy 的分布式支持
- 支持 Python
- 整体性能出众
Ray (pickle5 + cloudpickle)
GitHub - ray-project/plasma: A minimal shared memory object store design
GitHub - cloudpipe/cloudpickle: Extended pickling support for Python objects
- Plasma is an in-memory object store that is being developed as part of Apache Arrow
- Ray uses Plasma to efficiently transfer objects across different processes and different nodes
Actor
- An actor is essentially a stateful worker(or a service)
- A new actor is instantiated, a new worker is created
- When an actor contains async methods, the actor will be converted to async actors. This means all the ray’s tasks will run as a coroutine.
## 1
@ray.remote
class Counter(object):
def __init__(self):
self.value = 0
Counter = ray.remote(Counter)
## 1
class Counter(object):
def __init__(self):
self.value = 0
## then
counter_actor = Counter.remote()
Actor vs Worker
Actor: a worker instantiated at runtime
Worker: python process, execute multiple tasks or actor (dedicated)
Fault Tolerance
- task retry
- actor retry
- object retrieve or reconstruction
Airflow
Airflow can be act as job manager in Ray
Overview
BUILD
Ray 的编译使用 bazel,其中大量的 proto 编译也依赖于此,
具体定义在 src/ray/protobuf/BUILD 文件中,参考 文档.
启动部署
安装完成后,可以直接运行的相关命令如下
# python/setup.py
entry_points={
"console_scripts": [
"ray=ray.scripts.scripts:main",
"rllib=ray.rllib.scripts:cli [rllib]",
"tune=ray.tune.scripts:cli",
"ray-operator=ray.ray_operator.operator:main",
"serve=ray.serve.scripts:cli",
]
}
常驻模式启动 ray 集群
# 启动 head 节点
ray start --head
# 启动 worker 节点
ray start --address=RAY_HEAD_IP:6379
ray start --head --redis-password="" --port=6389
start 命令的解析如下
# python/ray/scripts/scripts.py
# args 解析用的是 click
@cli.command()
@click.option("--head",...)
def start(...,head,...):
ray_params = ray._private.parameter.RayParams(...)
if head:
# 启动 head 节点
ray_params.update_if_absent(...)
node = ray.node.Node(ray_params, head=True,...)
else:
# 启动 worker 节点
bootstrap_address = services.canonicalize_bootstrap_address(address)
ray_params.gcs_address = bootstrap_address
node = ray.node.Node(ray_params, head=False,...)
cli.add_command(start)
def main():
return cli()
可以看出本质上都是初始化了节点 Node 对象,是否为 head 则通过参数指定。
Node
Node 节点的初始化
# python/ray/node.py
class Node:
def __init__(self, ray_params, head=False,...):
self.head = head
if not head:
# GCS GRPC client, 确保 gcs 已启动
self.get_gcs_client()
# 初始化持久化存储
storage._init_storage(ray_params.storage, is_head=head)
if head:
self.validate_external_storage()
if ...:
# 启动 reaper 进程,负责在主进程意外退出后回收进程
self.start_reaper_process()
if head:
self.start_head_processes()
# 尝试写入 gcs
self.get_gcs_client().internal_kv_put(...)
if not connect_only:
self.start_ray_processes()
ray._private.services.wait_for_node(...)
Node 的初始化包括启动 start_head_processes 和 start_ray_processes 两部分。
# python/ray/node.py
class Node:
def start_head_processes(self):
# 如果使用外部 redis,需要配置
# 这里的逻辑目前有点 confuse,external 和 local 不够明确
if self._ray_params.external_addresses is not None:
self.start_or_configure_redis()
self.create_redis_client()
# 启动 gcs,包含 redis 服务, 默认端口 6379
self.start_gcs_server()
self.start_ray_client_server()
def start_or_configure_redis(self):
# 如果 external 有配置,并不真正启动
ray._private.services.start_redis(...)
def start_gcs_server(self):
process_info = ray._private.services.start_gcs_server(self.redis_address,...)
# 等待启动
self.get_gcs_client()
def start_ray_client_server(self):
process_info = ray._private.services.start_ray_client_server(self.address, self._node_ip_address, ...)
def start_ray_processes(self):
# 启动节点上所有的进程
self.destroy_external_storage()
# 启动 raylet
self.start_raylet(plasma_directory, object_store_memory)
def start_raylet(self, ...):
process_info = ray._private.services.start_raylet(
self.redis_address,
self.gcs_address,
self._node_ip_address,
...)
- Head 节点启动 gcs 服务和 ray_client 服务
- Head 和 Worker 节点都启动 raylet 服务
这些服务的具体启动都被封装在 services 里。
Services
Services 提供多种服务启动的封装,包括 redis 服务启动。
1.11 之前的版本 ray 通过启动 redis-server 二进制启动 redis,新版本中已经移除。
# python/ray/_private/services.py
def start_gcs_server(redis_address, ...):
# 调用 gcs 二进制启动服务,包含 redis 服务
# GCS_SERVER_EXECUTABLE "core/src/ray/gcs/gcs_server"
command = [GCS_SERVER_EXECUTABLE, "--redis_xxxx=", ...]
process_info = start_ray_process(command, ...)
def start_ray_client_server(address, ray_client_server_ip,...):
command = [
sys.executable, # python
setup_worker_path, # ray/workers/setup_worker.py
"-m",
"ray.util.client.server",
...]
process_info = start_ray_process(command, ...)
def start_raylet(redis_address, gcs_address, ...):
# 启动 raylet,包括 local scheduler 和 object manager
# 支持 python、java 和 cpp
# RAYLET_EXECUTABLE "core/src/ray/raylet/raylet"
command = [
RAYLET_EXECUTABLE,
f"--python_worker_command={subprocess.list2cmdline(start_worker_command)}", # noqa
f"--java_worker_command={subprocess.list2cmdline(java_worker_command)}", # noqa
f"--cpp_worker_command={subprocess.list2cmdline(cpp_worker_command)}", # noqa
...]
command.append("--agent_command={}".format(subprocess.list2cmdline(agent_command)))
process_info = start_ray_process(command, ...)
def start_ray_process(command, ...):
process = ConsolePopen(
command,
env=modified_env,
cwd=cwd,
stdout=stdout_file,
stderr=stderr_file,
stdin=subprocess.PIPE if pipe_stdin else None,
preexec_fn=preexec_fn if sys.platform != "win32" else None,
creationflags=CREATE_SUSPENDED if win32_fate_sharing else 0,
)
class ConsolePopen(subprocess.Popen):
pass
setup worker & runtime env context
setup worker 的作用是执行不同的程序,
# ray/workers/setup_worker.py
parser.add_argument("--serialized-runtime-env-context",...)
parser.add_argument("--language", ...)
if __name__ == "__main__":
args, remaining_args = parser.parse_known_args()
runtime_env_context = RuntimeEnvContext.deserialize(
args.serialized_runtime_env_context or "{}"
)
runtime_env_context.exec_worker(remaining_args, Language.Value(args.language))
# python/ray/_private/runtime_env/context.py
class RuntimeEnvContext:
def exec_worker(self, passthrough_args: List[str], language: Language):
os.environ.update(self.env_vars)
# exec [python] passthrough_args
command_str = " && ".join(...)
if sys.platform == "win32":
os.system(command_str)
else:
os.execvp("bash", args=["bash", "-c", command_str])
client server
python -m ray.util.client.server --address=x.x.x.x:6379 --host=0.0.0.0 --port=10001 --mode=proxy --redis-password=
# python/ray/util/client/server/__main__.py
# -> server.py main
# python/ray/util/client/server/server.py
def main():
server = serve(hostport, ray_connect_handler)
while True:
ray.experimental.internal_kv._internal_kv_put(..., HEALTHCHECK)
def serve(connection_str, ray_connect_handler=None):
server = grpc.server(
futures.ThreadPoolExecutor(
max_workers=CLIENT_SERVER_MAX_THREADS,
thread_name_prefix="ray_client_server",
),
)
# mode proxy
task_servicer = RayletServicerProxy(None, proxy_manager)
data_servicer = DataServicerProxy(proxy_manager)
logs_servicer = LogstreamServicerProxy(proxy_manager)
# else
task_servicer = RayletServicer(ray_connect_handler)
data_servicer = DataServicer(task_servicer)
logs_servicer = LogstreamServicer()
ray_client_pb2_grpc.add_RayletDriverServicer_to_server(task_servicer, server)
ray_client_pb2_grpc.add_RayletDataStreamerServicer_to_server(data_servicer, server)
ray_client_pb2_grpc.add_RayletLogStreamerServicer_to_server(logs_servicer, server)
server.start()
# python/ray/util/client/server/server.py
# class RayletServicerProxy(ray_client_pb2_grpc.RayletDriverServicer):
class RayletServicer(ray_client_pb2_grpc.RayletDriverServicer):
def KVPut(self, request, context=None) -> ray_client_pb2.KVPutResponse:
def KVGet(self, request, context=None) -> ray_client_pb2.KVGetResponse:
def KVDel(self, request, context=None) -> ray_client_pb2.KVDelResponse:
def KVList(self, request, context=None) -> ray_client_pb2.KVListResponse:
def ListNamedActors(...):
def ClusterInfo(self, request, context=None) -> ray_client_pb2.ClusterInfoResponse:
def release(self, client_id: str, id: bytes) -> bool:
def release_all(self, client_id):
def Terminate(self, req, context=None):
def GetObject(self, request: ray_client_pb2.GetRequest, context):
def PutObject( self, request: ray_client_pb2.PutRequest, context=None) -> ray_client_pb2.PutResponse:
def WaitObject(self, request, context=None) -> ray_client_pb2.WaitResponse:
def Schedule( self, task: ray_client_pb2.ClientTask, context=None) -> ray_client_pb2.ClientTaskTicket:
def lookup_or_register_func( self, id: bytes, client_id: str, options: Optional[Dict]) -> ray.remote_function.RemoteFunction:
def lookup_or_register_actor( self, id: bytes, client_id: str, options: Optional[Dict]):
def unify_and_track_outputs(self, output, client_id):
总结
ray start [--head], 将启动以下进程
# 以下进程只在 head 节点运行
# GCS_SERVER_EXECUTABLE
/usr/local/lib/python3.7/dist-packages/ray/core/src/ray/gcs/gcs_server
/usr/bin/python3.7 -m ray.util.client.server --host=0.0.0.0 --port=10001 --mode=proxy
# worker 进程
# RAYLET_EXECUTABLE
/usr/local/lib/python3.7/dist-packages/ray/core/src/ray/raylet/raylet
/usr/bin/python3.7 -u /usr/local/lib/python3.7/dist-packages/ray/dashboard/agent.py
/usr/bin/python3.7 -u /usr/local/lib/python3.7/dist-packages/ray/autoscaler/_private/monitor.py
/usr/bin/python3.7 -u /usr/local/lib/python3.7/dist-packages/ray/dashboard/dashboard.py
/usr/bin/python3.7 -u /usr/local/lib/python3.7/dist-packages/ray/_private/log_monitor.py
# 新版本中的以下进程已被移除
/usr/local/lib/python3.7/dist-packages/ray/core/src/ray/thirdparty/redis/src/redis-server *:6379
/usr/local/lib/python3.7/dist-packages/ray/core/src/ray/thirdparty/redis/src/redis-server *:64712
# java worker command
python ray/workers/setup_worker.py java -Dx=x -cp xx RAY_WORKER_DYNAMIC_OPTION_PLACEHOLDER io.ray.runtime.runner.worker.DefaultWorker
# cpp worker command
cpp/default_worker
GCS Server
服务由以下二进制启动
"core/src/ray/gcs/gcs_server"
程序入口
// src/ray/gcs/gcs_server/gcs_server_main.cc
int main(int argc, char *argv[]) {
// 初始化配置
RayConfig::instance().initialize(config_list);
// 启动 IO service
// class instrumented_io_context : public boost::asio::io_context {...}
instrumented_io_context main_service;
boost::asio::io_service::work work(main_service);
// 初始化状态模块
ray::stats::Init(global_tags, metrics_agent_port);
// 启动 grpc 服务
ray::gcs::GcsServerConfig gcs_server_config;
gcs_server_config.grpc_server_name = "GcsServer";
ray::gcs::GcsServer gcs_server(gcs_server_config, main_service);
gcs_server.Start();
main_service.run();
}
主服务
// src/ray/gcs/gcs_server/gcs_server.cc
// 服务初始化,根据配置使用外置 redis 存储或者内置存储
GcsServer::GcsServer(...) {
if (storage_type_ == "redis") {
gcs_table_storage_ = std::make_shared<gcs::RedisGcsTableStorage>(GetOrConnectRedis());
} else if (storage_type_ == "memory") {
gcs_table_storage_ = std::make_shared<InMemoryGcsTableStorage>(main_service_);
}
}
void GcsServer::Start() {
// 异步加载 gcs tables 数据
auto gcs_init_data = std::make_shared<GcsInitData>(gcs_table_storage_);
gcs_init_data->AsyncLoad([this, gcs_init_data] { DoStart(*gcs_init_data); });
}
void GcsServer::DoStart(const GcsInitData &gcs_init_data) {
// Init cluster resource scheduler.
// Init gcs resource manager.
// Init synchronization service
// Init gcs node manager.
// Init gcs heartbeat manager.
// Init KV Manager
// Init function manager
// Init Pub/Sub handler
// Init RuntimeENv manager
// Init gcs job manager.
// Init gcs placement group manager.
// Init gcs actor manager.
// Init gcs worker manager.
// Init stats handler.
// Install event listeners.
// 启动 rpc 服务,依赖 tables 数据加载完成
// rpc::GrpcServer rpc_server_;
rpc_server_.Run();
// 心跳服务
gcs_heartbeat_manager_->Start();
RecordMetrics();
}
Table storage
// src/ray/gcs/gcs_server/gcs_table_storage.h
class GcsTable {}
class GcsTableWithJobId : public GcsTable<Key, Data> {}
class GcsTableStorage {};
class RedisGcsTableStorage : public GcsTableStorage {};
class InMemoryGcsTableStorage : public GcsTableStorage {};
Raylet
服务由以下二进制启动
core/src/ray/raylet/raylet
程序入口
// src/ray/raylet/main.cc
int main(int argc, char *argv[]) {
// 启动 IO service
// class instrumented_io_context : public boost::asio::io_context {...}
instrumented_io_context main_service;
boost::asio::io_service::work main_work(main_service);
std::unique_ptr<ray::raylet::Raylet> raylet;
ray::raylet::NodeManagerConfig node_manager_config;
ray::ObjectManagerConfig object_manager_config;
raylet = std::make_unique<ray::raylet::Raylet>(main_service,
raylet_socket_name,
node_ip_address,
node_manager_config,
object_manager_config,
gcs_client,
metrics_export_port);
raylet->Start();
main_service.run();
}
主服务类
// src/ray/raylet/raylet.cc
class Raylet {
// 用于和 gcs 连接的客户端
std::shared_ptr<gcs::GcsClient> gcs_client_;
NodeManager node_manager_;
}
void Raylet::Start() {
RAY_CHECK_OK(RegisterGcs());
// Start listening for clients.
DoAccept();
}
ray::Status Raylet::RegisterGcs() {
node_manager_.RegisterGcs();
gcs_client_->Nodes().RegisterSelf(self_node_info_, register_callback);
}
void Raylet::DoAccept() {
acceptor_.async_accept(
socket_,
boost::bind(&Raylet::HandleAccept, this, boost::asio::placeholders::error));
}
void Raylet::HandleAccept(const boost::system::error_code &error) {
// 建立本地连接并分发到 node manager 处理
auto new_connection = ClientConnection::Create(
client_handler, // node_manager_.ProcessNewClient(client);
message_handler, // node_manager_.ProcessClientMessage(client, message_type, message.data());
std::move(socket_),
"worker",
node_manager_message_enum,
static_cast<int64_t>(protocol::MessageType::DisconnectClient),
message_data);
// 处理连接
DoAccept();
}
Node Manager
NodeManager 本身是一个 ServiceHandler,所以在初始化 node_manager_service_ 时,使用 this 作为 handler 传递。
// src/ray/raylet/node_manager.h
class NodeManager : public rpc::NodeManagerServiceHandler {
std::shared_ptr<gcs::GcsClient> gcs_client_;
std::unique_ptr<HeartbeatSender> heartbeat_sender_;
WorkerPool worker_pool_;
ObjectManager object_manager_;
rpc::GrpcServer node_manager_server_;
rpc::NodeManagerGrpcService node_manager_service_;
std::unique_ptr<rpc::AgentManagerServiceHandler> agent_manager_service_handler_;
rpc::AgentManagerGrpcService agent_manager_service_;
std::shared_ptr<ClusterResourceScheduler> cluster_resource_scheduler_;
std::shared_ptr<LocalTaskManager> local_task_manager_;
std::shared_ptr<PlacementGroupResourceManager> placement_group_resource_manager_;
}
// src/ray/raylet/node_manager.cc
// Push
// Pull
NodeManager::NodeManager(...) {
// 非常多的初始化配置
node_manager_service_(io_service, *this),
// 然后注册服务并启动
node_manager_server_.RegisterService(node_manager_service_);
node_manager_server_.RegisterService(agent_manager_service_);
node_manager_server_.Run();
}
NodeManager 的 rpc 接口
// src/ray/rpc/node_manager/node_manager_server.h
// `NodeManagerService` 的接口, 对应 `src/ray/protobuf/node_manager.proto`.
class NodeManagerServiceHandler {}
// 目前有以下接口
// UpdateResourceUsage
// RequestResourceReport
// RequestWorkerLease
// ReportWorkerBacklog
// ReturnWorker
// ReleaseUnusedWorkers
// CancelWorkerLease
// PinObjectIDs
// GetNodeStats
// GlobalGC
// FormatGlobalMemoryInfo
// PrepareBundleResources
// CommitBundleResources
// CancelResourceReserve
// RequestObjectSpillage
// ReleaseUnusedBundles
// GetSystemConfig
// GetGcsServerAddress
// ShutdownRaylet
class NodeManagerGrpcService : public GrpcService {
NodeManagerGrpcService(instrumented_io_context &io_service,
NodeManagerServiceHandler &service_handler)
}
关于怎么增加新的接口可以参考:
src/ray/core_worker/core_worker.h.
ObjectManager
// src/ray/object_manager/object_manager.h
class ObjectManager : public ObjectManagerInterface, public rpc::ObjectManagerServiceHandler {
instrumented_io_context rpc_service_;
boost::asio::io_service::work rpc_work_;
rpc::GrpcServer object_manager_server_;
rpc::ObjectManagerGrpcService object_manager_service_;
}
// 主要接口
// Push
// Pull
// src/ray/object_manager/object_manager.cc
ObjectManager::ObjectManager(...){
rpc_work_(rpc_service_),
object_manager_server_("ObjectManager",...)
object_manager_service_(rpc_service_, *this),
StartRpcService();
}
void ObjectManager::StartRpcService() {
// for i in config_.rpc_service_threads_number
rpc_threads_[i] = std::thread(&ObjectManager::RunRpcService, this, i);
object_manager_server_.RegisterService(object_manager_service_);
object_manager_server_.Run();
}
void ObjectManager::RunRpcService(int index) {
rpc_service_.run();
}
// src/ray/rpc/object_manager/object_manager_server.h
class ObjectManagerGrpcService : public GrpcService {
ObjectManagerGrpcService(instrumented_io_context &io_service,
ObjectManagerServiceHandler &service_handler)
: GrpcService(io_service), service_handler_(service_handler){};
Worker Pool
// src/ray/raylet/worker_pool.cc
API
import ray
ray.init()
# ray.init(address='ray://localhost:10001')
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
# python/ray/__init__.py
from ray.worker import ( # noqa: E402,F401
get,
init,
put,
remote,
wait,
)
API ray.init, ray.remote, ray.get 都来自 ray.worker.
# python/ray/worker.py
def init(address: Optional[str] = None, ...):
# if address
builder = ray.client(address, _deprecation_warn_enabled=False)
builder._init_args(**passed_kwargs)
return builder.connect()
# if bootstrap_address is None:
_global_node = ray.node.Node(head=True, shutdown_at_exit=False, spawn_reaper=True, ray_params=ray_params)
# else
_global_node = ray.node.Node(ray_params, head=False, shutdown_at_exit=False, spawn_reaper=False, connect_only=True)
connect(...)
return RayContext(...)
def connect(node, worker=global_worker, ...):
worker.node = node
worker.core_worker = ray._raylet.CoreWorker(...)
CoreWorker
// src/ray/core_worker/core_worker.h
class CoreWorker : public rpc::CoreWorkerServiceHandler {
instrumented_io_context io_service_;
boost::asio::io_service::work io_work_;
rpc::CoreWorkerGrpcService grpc_service_;
std::unique_ptr<rpc::GrpcServer> core_worker_server_;
// std::unique_ptr<ObjectRecoveryManager> object_recovery_manager_;
std::shared_ptr<TaskManager> task_manager_;
std::unique_ptr<ActorManager> actor_manager_;
/// Implements gRPC server handler.
void HandleXxxx(const rpc::PushTaskRequest &request,
rpc::PushTaskReply *reply,
rpc::SendReplyCallback send_reply_callback) override;
}
// src/ray/core_worker/core_worker.cc
CoreWorker::CoreWorker(...) {
io_work_(io_service_),
grpc_service_(io_service_, *this),
core_worker_server_->RegisterService(grpc_service_);
core_worker_server_->Run();
}
Ray
First Glance
-
通过装饰器实现功能
https://rise.cs.berkeley.edu/blog/ray-tips-for-first-time-users/
| API | Description | Example |
|---|---|---|
| ray.init() | Initialize Ray context. | |
| @ray.remote | Function or class decorator specifying that the function will be executed as a task or the class as an actor in a different process. | @ray.remote @ray.remote def fun(x): class Actor(object): … def method(y) … |
| .remote | Postfix to every remote function, remote class declaration, or invocation of a remote class method. Remote operations are asynchronous. | ret_id = fun.remote(x) a = Actor.remote() ret_id = a.method.remote(y) |
| ray.put() | Store object in object store, and return its ID. This ID can be used to pass object as an argument to any remote function or method call. This is a synchronous operation. | x_id = ray.put(x) |
| ray.get() | Return an object or list of objects from the object ID or list of object IDs. This is a synchronous (i.e., blocking) operation. | x = ray.get(x_id) … objects = ray.get(object_ids) |
| ray.wait() | From a list of object IDs returns (1) the list of IDs of the objects that are ready, and (2) the list of IDs of the objects that are not ready yet. By default it returns one ready object ID at a time. | ready_ids, not_ready_ids = ray.wait(object_ids) |
特点
- 分布式异步调用
- 内存调度
- Pandas/Numpy 的分布式支持
- 支持 Python
- 整体性能出众
vs DASK
Ray (pickle5 + cloudpickle)
GitHub - ray-project/plasma: A minimal shared memory object store design
GitHub - cloudpipe/cloudpickle: Extended pickling support for Python objects
-
Plasma is an in-memory object store that is being developed as part of Apache Arrow
-
Ray uses Plasma to efficiently transfer objects across different processes and different nodes
Actor
-
An actor is essentially a stateful worker(or a service)
-
A new actor is instantiated, a new worker is created
-
When an actor contains async methods, the actor will be converted to async actors. This means all the ray’s tasks will run as a coroutine.
## 1
@ray.remote
class Counter(object):
def __init__(self):
self.value = 0
Counter = ray.remote(Counter)
## 1
class Counter(object):
def __init__(self):
self.value = 0
## then
counter_actor = Counter.remote()
Actor vs Worker
Actor: a worker instantiated at runtime
Worker: python process, execute multiple tasks or actor (dedicated)
Fault Tolerance
-
task retry
-
actor retry
-
object retrieve or reconstruction
Airflow
Airflow can be act as job manager in Ray
Code Structure
main.cc
int main(int argc, char *argv[]) {
// IO Service for node manager.
instrumented_io_context main_service;
// Ensure that the IO service keeps running. Without this, the service will exit as soon
// as there is no more work to be processed.
boost::asio::io_service::work main_work(main_service);
// Initialize gcs client
std::shared_ptr<ray::gcs::GcsClient> gcs_client;
gcs_client = std::make_shared<ray::gcs::GcsClient>(client_options);
RAY_CHECK_OK(gcs_client->Connect(main_service));
std::unique_ptr<ray::raylet::Raylet> raylet;
raylet = std::make_unique<ray::raylet::Raylet>(
main_service, raylet_socket_name, node_ip_address, node_manager_config,
object_manager_config, gcs_client, metrics_export_port);
raylet->Start();
main_service.run();
}
Reference
Welcome to the Ray documentation — Ray 1.11.0
Ray 1.x Architecture - Google 文档
llama
# example_text_completion.py
def main(...):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
prompts: List[str] = [
"I believe the meaning of life is",
"Simply put, the theory of relativity states that ",
]
results = generator.text_completion(
prompts,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for prompt, result in zip(prompts, results):
print(prompt)
# llama/generation.py
class Llama:
@staticmethod
def build(...) -> "Llama":
tokenizer = Tokenizer(model_path=tokenizer_path)
model_args.vocab_size = tokenizer.n_words
model = Transformer(model_args)
return Llama(model, tokenizer)
@torch.inference_mode()
def generate(self, prompt_tokens: List[List[int]], max_gen_len, temperature, top_p, logprobs) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
pad_id = self.tokenizer.pad_id
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
if logprobs:
token_logprobs = torch.zeros_like(tokens, dtype=torch.float)
prev_pos = 0
eos_reached = torch.tensor([False] * bsz, device="cuda")
input_text_mask = tokens != pad_id
if min_prompt_len == total_len:
logits = self.model.forward(tokens, prev_pos)
token_logprobs = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens,
reduction="none",
ignore_index=pad_id,
)
for cur_pos in range(min_prompt_len, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
if logprobs:
token_logprobs[:, prev_pos + 1 : cur_pos + 1] = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens[:, prev_pos + 1 : cur_pos + 1],
reduction="none",
ignore_index=pad_id,
)
eos_reached |= (~input_text_mask[:, cur_pos]) & (
next_token == self.tokenizer.eos_id
)
prev_pos = cur_pos
if all(eos_reached):
break
if logprobs:
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
# cut to max gen len
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start : len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start : len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
out_tokens.append(toks)
out_logprobs.append(probs)
return (out_tokens, out_logprobs if logprobs else None)
def text_completion(...) -> List[CompletionPrediction]:
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
generation_tokens, generation_logprobs = self.generate(...)
if logprobs:
return [
{
"generation": self.tokenizer.decode(t),
"tokens": [self.tokenizer.decode(x) for x in t],
"logprobs": logprobs_i,
}
for t, logprobs_i in zip(generation_tokens, generation_logprobs)
]
return [{"generation": self.tokenizer.decode(t)} for t in generation_tokens]
nccl
Example
one device per process/thread 为常用模式
- ncclGetUniqueId 生成 ID,
NCCL 建立通信域需要依赖共同的 nccl ID, 通常在 0 号节点上调用 ncclGetUniqueId API 生成 ID, 然后 broadcast 到所有节点上,这里 broadcast 的媒介 NCCL 并未提供方法,也没有限制。 可以通过 mpi、gloo、tcp 等方式在节点间同步。
ncclUniqueId id;
if (myRank == 0) ncclGetUniqueId(&id);
- ncclCommInitRank 建立通信域
NCCL 使用 (id, rank, size) 三元组建立通信域。
ncclComm_t comm;
ncclCommInitRank(&comm, nRanks, id, myRank);
- ncclAllReduce 使用 NCCL 通信
通过建立好的通信域,可以调用 NCCL 提供的 API 进行集合通信。
ncclAllReduce( ... , comm);
- ncclCommDestroy 销毁通信域
使用 ncclCommDestroy API 销毁通信域,释放资源,另 ncclCommAbort 可用于标记释放通信域,实现容错等流程。
ncclCommDestroy(comm);
API
重点使用的 API, 可以说是使用 NCCL 的目的就是使用这些 API 进行通信交换数据。
- Collective Communication Functions
- ncclAllReduce
- ncclBroadcast
- ncclReduce
- ncclAllGather
- ncclReduceScatter
为了实现上述操作需要建立基本的连接等等操作,重点围绕通信域概念。
- Communicator Creation and Management Functions
- ncclGetVersion
- ncclGetUniqueId
- ncclCommInitRank
- ncclCommInitAll
- ncclCommInitRankConfig
- ncclCommDestroy
- ncclCommAbort
- ncclCommGetAsyncError
- ncclCommCount
- ncclCommCuDevice
- ncclCommUserRank
为了讲述,进行如下定义,才有前述的操作。
- Types
- ncclComm_t
- ncclResult_t
- ncclDataType_t
- ncclRedOp_t
- ncclConfig_t
为了高效和优化引入逻辑上的组概念。
- Group Calls
- ncclGroupStart
- ncclGroupEnd
引入点对点通信,可以实现比如 all-to-all 操作。
- Point To Point Communication Functions
- ncclSend
- ncclRecv
Workflow
ncclGetUniqueId
创建 ncclGetUniqueId 时会首先调用初始化函数 ncclInit 确认网络已经初始化, 然后调用 bootstrapGetUniqueId 创建 ncclUniqueId。
// nccl/src/init.cc
ncclResult_t ncclGetUniqueId(ncclUniqueId* out) {
NCCLCHECK(ncclInit());
return bootstrapGetUniqueId(out);
}
ncclInit 分为两部分
bootstrapNetInit调用ncclFindInterfaces完成获取 Interface 信息,赋值ncclSocketAddress bootstrapNetIfAddrncclNetPluginInit加载 net plugin
// nccl/src/init.cc
static ncclResult_t ncclInit() {
NCCLCHECK(bootstrapNetInit());
NCCLCHECK(ncclNetPluginInit());
return ncclSuccess;
}
从定义
#define NCCL_UNIQUE_ID_BYTES 128
typedef struct { char internal[NCCL_UNIQUE_ID_BYTES]; } ncclUniqueId;
可以看出 ncclUniqueId 就是 128 个 char 构成的 struct。
// nccl/src/bootstrap.cc
static union socketAddress bootstrapNetIfAddr;
ncclResult_t bootstrapGetUniqueId(ncclUniqueId* id) {
memset(id, 0, sizeof(ncclUniqueId));
char* env = getenv("NCCL_COMM_ID");
if (env) {
if (ncclGetSocketAddrFromString(connectAddr, env) != ncclSuccess) {
return ncclInvalidArgument;
}
} else {
memcpy(id, &bootstrapNetIfAddr, sizeof(union ncclSocketAddress));
NCCLCHECK(bootstrapCreateRoot(id, false));
}
return ncclSuccess;
}
创建主节点监听线程,ncclUniqueId 的本质是 socketAddress,
ncclResult_t bootstrapCreateRoot(ncclUniqueId* id, bool idFromEnv) {
union socketAddress* connectAddr = (union socketAddress*) id;
int listenFd;
NCCLCHECK(createListenSocket(&listenFd, connectAddr));
pthread_t thread;
pthread_create(&thread, NULL, bootstrapRoot, (void*)(uint64_t)listenFd);
return ncclSuccess;
}
使用
NCCL_COMM_ID时,该函数在ncclCommInitRankDev里调用启动 root 上的 tcp 监听服务。
ncclCommInitRank
ncclCommInitRank 初始化调用 ncclCommInitRankDev 完成初始化,包括
- 如果使用
NCCL_COMM_ID且 rank 为 0 则需要启动 root 服务; - 确保已经
ncclInit - 调用
ncclCommInitRankFunc初始化,主要调用initTransportsRank完成rendezvous.
// nccl/src/init.cc
ncclResult_t ncclCommInitRank(ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank) {
NCCLCHECK(ncclCommInitRankDev(newcomm, nranks, commId, myrank, cudaDev, NULL));
return ncclSuccess;
}
static ncclResult_t ncclCommInitRankDev(ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank, int cudaDev, ncclConfig_t *config) {
char* env = getenv("NCCL_COMM_ID");
if (env && myrank == 0) {
NCCLCHECKGOTO(bootstrapCreateRoot(&commId, true), res, fail);
}
NCCLCHECKGOTO(ncclInit(), res, fail);
struct ncclCommInitRankAsyncJob *job = NULL;
NCCLCHECKGOTO(ncclAsyncLaunch(&job->base, ncclCommInitRankFunc, NULL, free, comm), res, fail);
return ncclGroupErrCheck(res);
}
static ncclResult_t ncclCommInitRankFunc(struct ncclAsyncJob* job_) {
NCCLCHECKGOTO(initTransportsRank(*newcomm, &commId), res, cleanup);
comm->initState = ncclSuccess;
return ncclSuccess;
}
initTransportsRank 是初始化中最为复杂的部分,主要包括
- 通过 bootstrapAllGather 把所有 peer 的信息收集在一起
- 计算 3 个 ncclTopoGraph: ring/tree/colnet
- 建立 p2p/ring/tree 等链接
static ncclResult_t initTransportsRank(struct ncclComm* comm, ncclUniqueId* commId) {
// We use 2 AllGathers
// 1. { peerInfo, comm, compCap}
// 2. { nChannels, graphInfo, topoRanks }
NCCLCHECK(bootstrapInit(commId, comm));
NCCLCHECK(bootstrapAllGather(comm->bootstrap, comm->peerInfo, sizeof(struct ncclPeerInfo)));
// Topo detection / System graph creation
NCCLCHECK(ncclTopoGetSystem(comm, &comm->topo));
// Compute paths between GPUs and NICs
NCCLCHECK(ncclTopoComputePaths(comm->topo, comm));
// Remove inaccessible GPUs and unused NICs
NCCLCHECK(ncclTopoTrimSystem(comm->topo, comm));
// Recompute paths after trimming
NCCLCHECK(ncclTopoComputePaths(comm->topo, comm));
// Init search
NCCLCHECK(ncclTopoSearchInit(comm->topo));
// Print final topology
NCCLCHECK(ncclTopoPrint(comm->topo));
// Set Affinity to a CPU local the our GPU, so that all memory we allocate
// on the host is local.
NCCLCHECK(ncclTopoGetCpuAffinity(comm->topo, comm->rank, &comm->cpuAffinity));
// Launch proxy service thread
NCCLCHECK(ncclProxyCreate(comm));
// Get rings and trees
struct ncclTopoGraph ringGraph;
NCCLCHECK(ncclTopoCompute(comm->topo, &ringGraph));
NCCLCHECK(ncclTopoPrintGraph(comm->topo, &ringGraph));
struct ncclTopoGraph treeGraph;
NCCLCHECK(ncclTopoCompute(comm->topo, &treeGraph));
NCCLCHECK(ncclTopoPrintGraph(comm->topo, &treeGraph));
struct ncclTopoGraph collNetGraph;
NCCLCHECK(ncclTopoCompute(comm->topo, &collNetGraph));
NCCLCHECK(ncclTopoPrintGraph(comm->topo, &collNetGraph));
// Determine local CollNet support before all-gather
// AllGather3 - begin
struct ncclGraphInfo {
int pattern;
int nChannels;
int sameChannels;
float bwIntra;
float bwInter;
int typeIntra;
int typeInter;
};
struct {
int netDev;
int collNetSupport;
struct ncclGraphInfo tree;
struct ncclGraphInfo ring;
struct ncclGraphInfo collNet;
struct ncclTopoRanks topoRanks;
} *allGather3Data;
NCCLCHECK(bootstrapAllGather(comm->bootstrap, allGather3Data, sizeof(*allGather3Data)));
// Connect with prev/next for each ring
for (int c=0; c<comm->nChannels; c++) {
NCCLCHECKGOTO(setupChannel(comm, c, rank, nranks, rings+c*nranks), ret, affinity_restore);
NCCLCHECKGOTO(ncclTransportP2pConnect(comm, c, 1, &channel->ring.prev, 1, &channel->ring.next, 0), ret, affinity_restore);
}
NCCLCHECKGOTO(ncclTransportP2pSetup(comm, &ringGraph, 0), ret, affinity_restore);
// Connect Trees
for (int c=0; c<comm->nChannels; c++) {
NCCLCHECKGOTO(ncclTransportP2pConnect(comm, c, NCCL_MAX_TREE_ARITY, channel->tree.down, 1, &channel->tree.up, 0), ret, affinity_restore);
NCCLCHECKGOTO(ncclTransportP2pConnect(comm, c, 1, &channel->tree.up, NCCL_MAX_TREE_ARITY, channel->tree.down, 0), ret, affinity_restore);
}
NCCLCHECKGOTO(ncclTransportP2pSetup(comm, &treeGraph, 0), ret, affinity_restore);
// Compute nChannels per peer for p2p
NCCLCHECK(ncclTopoComputeP2pChannels(comm));
/* Local intra-node barrier */
NCCLCHECK(bootstrapBarrier(comm->bootstrap, comm->localRankToRank, comm->localRank, comm->localRanks, comm->localRankToRank[0]));
return ncclSuccess;
}
其中 bootstrapInit 和 bootstrapAllGather 完成建立 socket 和连接的操作。
// src/bootstrap.cc
ncclResult_t bootstrapInit(ncclUniqueId * id, struct ncclComm* comm) {
// Create socket for other ranks to contact me
NCCLCHECK(ncclSocketListen(&state->listenSock));
memcpy(&info.extAddressListen, &state->listenSock.addr, sizeof(union ncclSocketAddress));
// Create socket for root to contact me
NCCLCHECK(ncclSocketListen(&listenSockRoot));
memcpy(&info.extAddressListenRoot, &listenSockRoot.addr, sizeof(union ncclSocketAddress));
// send info on my listening socket to root
NCCLCHECK(ncclSocketConnect(&sock));
NCCLCHECK(bootstrapNetSend(&sock, &info, sizeof(info)));
// get info on my "next" rank in the bootstrap ring from root
NCCLCHECK(ncclSocketAccept(&sock, &listenSockRoot));
NCCLCHECK(bootstrapNetRecv(&sock, &state->ringSendSocket.addr, sizeof(union ncclSocketAddress)));
NCCLCHECK(ncclSocketConnect(&state->ringSendSocket));
// Accept the connect request from the previous rank in the AllGather ring
NCCLCHECK(ncclSocketAccept(&state->ringRecvSocket, &state->listenSock));
// AllGather all listen handlers
NCCLCHECK(ncclCalloc(&state->peerCommAddresses, nranks));
memcpy(state->peerCommAddresses+rank, &state->listenSock.addr, sizeof(union ncclSocketAddress));
NCCLCHECK(bootstrapAllGather(state, state->peerCommAddresses, sizeof(union ncclSocketAddress)));
// Create the service proxy
NCCLCHECK(ncclCalloc(&state->peerProxyAddresses, nranks));
struct ncclSocket* proxySocket;
NCCLCHECK(ncclCalloc(&proxySocket, 1));
NCCLCHECK(ncclSocketInit(proxySocket, &bootstrapNetIfAddr, NULL, 0));
NCCLCHECK(ncclSocketListen(proxySocket));
memcpy(state->peerProxyAddresses+rank, &proxySocket->addr, sizeof(union ncclSocketAddress));
NCCLCHECK(bootstrapAllGather(state, state->peerProxyAddresses, sizeof(union ncclSocketAddress)));
NCCLCHECK(ncclProxyInit(comm, proxySocket, state->peerProxyAddresses));
return ncclSuccess;
}
ncclResult_t bootstrapAllGather(void* commState, void* allData, int size) {
/* Simple ring based AllGather
* At each step i receive data from (rank-i-1) from left
* and send previous step's data from (rank-i) to right
*/
for (int i=0; i<nranks-1; i++) {
size_t rslice = (rank - i - 1 + nranks) % nranks;
size_t sslice = (rank - i + nranks) % nranks;
// Send slice to the right
NCCLCHECK(bootstrapNetSend(&state->ringSendSocket, data+sslice*size, size));
// Recv slice from the left
NCCLCHECK(bootstrapNetRecv(&state->ringRecvSocket, data+rslice*size, size));
}
return ncclSuccess;
}
NCCL init
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include <unistd.h>
#include <stdint.h>
#include <stdlib.h>
#define CUDACHECK(cmd) do { \
cudaError_t e = cmd; \
if( e != cudaSuccess ) { \
printf("Failed: Cuda error %s:%d '%s'\n", \
__FILE__,__LINE__,cudaGetErrorString(e)); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define NCCLCHECK(cmd) do { \
ncclResult_t r = cmd; \
if (r!= ncclSuccess) { \
printf("Failed, NCCL error %s:%d '%s'\n", \
__FILE__,__LINE__,ncclGetErrorString(r)); \
exit(EXIT_FAILURE); \
} \
} while(0)
static uint64_t getHostHash(const char *string) {
// Based on DJB2, result = result * 33 + char
uint64_t result = 5381;
for (int c = 0; string[c] != '\0'; c++) {
result = ((result << 5) + result) + string[c];
}
return result;
}
static void getHostName(char *hostname, int maxlen) {
gethostname(hostname, maxlen);
for (int i = 0; i < maxlen; i++) {
if (hostname[i] == '.') {
hostname[i] = '\0';
return;
}
}
}
int main(int argc, char *argv[]) {
int bsize = 32 * 1024 * 1024;
const int rank = atoi(getenv("RANK"));
const int size = atoi(getenv("SIZE"));
ncclUniqueId id;
ncclComm_t comm;
float *sendbuff, *recvbuff;
cudaStream_t s;
ncclGetUniqueId(&id);
// picking a GPU based on localRank, allocate device buffers
CUDACHECK(cudaSetDevice(rank));
CUDACHECK(cudaMalloc(&sendbuff, bsize * sizeof(float)));
CUDACHECK(cudaMalloc(&recvbuff, bsize * sizeof(float)));
CUDACHECK(cudaStreamCreate(&s));
// initializing NCCL
NCCLCHECK(ncclCommInitRank(&comm, size, id, rank));
// communicating using NCCL
NCCLCHECK(ncclAllReduce((const void *) sendbuff, (void *) recvbuff,
bsize, ncclFloat, ncclSum,
comm, s));
// completing NCCL operation by synchronizing on the CUDA stream
CUDACHECK(cudaStreamSynchronize(s));
// free device buffers
CUDACHECK(cudaFree(sendbuff));
CUDACHECK(cudaFree(recvbuff));
// finalizing NCCL
ncclCommDestroy(comm);
printf("[Rank %d] Success \n", rank);
return 0;
}
NCCL INFO Bootstrap : Using eth0:10.10.1.1<0>
NCCL INFO NET/Plugin : Plugin load returned 17 : libnccl-net.so: cannot open shared object file: No such file or directory.
NCCL INFO cudaDriverVersion 11020
NCCL version 2.14.3+cuda11.2
56.247345 bootstrapRoot:103 NCCL TRACE BEGIN
NCCL INFO Failed to open libibverbs.so[.1]
NCCL INFO NET/Socket : Using [0]eth0:10.10.1.1<0>
NCCL INFO Using network Socket
62.445105 commAlloc:333 NCCL TRACE comm 0x212a200 rank 0 nranks 2 cudaDev 0 busId 3f000
62.464643 initTransportsRank:515 NCCL TRACE comm 0x212a200, commHash 17da27e246bdeae5, rank 0 nranks 2 - BEGIN
62.472759 bootstrapInit:225 NCCL TRACE rank 0 nranks 2
64.823384 bootstrapRoot:134 NCCL TRACE Received connect from rank 0 total 1/2
713528.501653 bootstrapRoot:134 NCCL TRACE Received connect from rank 1 total 2/2
713528.526803 bootstrapRoot:136 NCCL TRACE COLLECTED ALL 2 HANDLES
713533.526805 bootstrapRoot:149 NCCL TRACE SENT OUT ALL 2 HANDLES
713533.563041 bootstrapRoot:158 NCCL TRACE DONE
713534.258114 bootstrapAllGather:296 NCCL TRACE rank 0 nranks 2 size 28
713536.434154 bootstrapAllGather:312 NCCL TRACE rank 0 nranks 2 size 28 - DONE
713536.462180 bootstrapAllGather:296 NCCL TRACE rank 0 nranks 2 size 28
713536.483120 bootstrapAllGather:312 NCCL TRACE rank 0 nranks 2 size 28 - DONE
713536.493973 bootstrapInit:285 NCCL TRACE rank 0 nranks 2 - DONE
713536.544262 getHostHash:112 NCCL TRACE unique hostname 'xxx.xxx.xxx.xxx'
713536.568319 getPidHash:132 NCCL TRACE unique PID '36548pid:[4026534279]'
713563.230542 bootstrapAllGather:296 NCCL TRACE rank 0 nranks 2 size 64
713563.325008 bootstrapAllGather:312 NCCL TRACE rank 0 nranks 2 size 64 - DONE
715298.136366 ncclTopoGetCpuAffinity:754 NCCL TRACE Current affinity for GPU 0 is ff,ffffffff
715298.149614 ncclTopoGetCpuAffinity:765 NCCL TRACE CPU GPU affinity for GPU 0 is 0fffff
NCCL INFO Setting affinity for GPU 0 to 0fffff
715305.454682 bootstrapAllGather:296 NCCL TRACE rank 0 nranks 2 size 988
715305.544090 bootstrapAllGather:312 NCCL TRACE rank 0 nranks 2 size 988 - DONE
715305.552080 initTransportsRank:698 NCCL TRACE hostHash[0] 69ce2bece884b496 localRank 0 localRanks 2 localRank0 0
NCCL INFO Channel 00/04 : 0 1
NCCL INFO Channel 01/04 : 0 1
NCCL INFO Channel 02/04 : 0 1
NCCL INFO Channel 03/04 : 0 1
715305.591060 initTransportsRank:768 NCCL TRACE rank 0 nranks 2 - BUILT 4 TREES/RINGS
NCCL INFO Trees [0] 1/-1/-1->0->-1 [1] 1/-1/-1->0->-1 [2] 1/-1/-1->0->-1 [3] 1/-1/-1->0->-1
715305.603265 setupChannel:458 NCCL TRACE rank 0 nranks 2
715334.994056 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 1
715335.016927 setupChannel:458 NCCL TRACE rank 0 nranks 2
715335.038300 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 1
715335.042547 setupChannel:458 NCCL TRACE rank 0 nranks 2
715335.059655 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 1
715335.062755 setupChannel:458 NCCL TRACE rank 0 nranks 2
715335.078080 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 1
NCCL INFO Channel 00/0 : 0[3f000] -> 1[40000] via P2P/IPC
NCCL INFO Channel 01/0 : 0[3f000] -> 1[40000] via P2P/IPC
NCCL INFO Channel 02/0 : 0[3f000] -> 1[40000] via P2P/IPC
NCCL INFO Channel 03/0 : 0[3f000] -> 1[40000] via P2P/IPC
NCCL INFO Connected all rings
715759.057432 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 3
715759.070377 ncclTransportP2pConnect:43 NCCL TRACE nsend 3 nrecv 1
715759.078084 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 3
715759.085182 ncclTransportP2pConnect:43 NCCL TRACE nsend 3 nrecv 1
715759.095093 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 3
715759.104299 ncclTransportP2pConnect:43 NCCL TRACE nsend 3 nrecv 1
715759.113734 ncclTransportP2pConnect:43 NCCL TRACE nsend 1 nrecv 3
715759.122855 ncclTransportP2pConnect:43 NCCL TRACE nsend 3 nrecv 1
NCCL INFO Connected all trees
715760.166631 initTransportsRank:885 NCCL TRACE rank 0 nranks 2 - CONNECTED 4 RINGS AND TREES
NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512
NCCL INFO 4 coll channels, 4 p2p channels, 4 p2p channels per peer
715821.176226 initTransportsRank:1006 NCCL TRACE pidHash[0] 6dfbb6f42b423cdb intraProcRank 0 intraProcRanks 1 intraProcRank0 0
715890.912294 bootstrapBarrier:331 NCCL TRACE rank 0 nranks 2 tag 0 - ENTER
715895.718005 bootstrapBarrier:346 NCCL TRACE rank 0 nranks 2 tag 0 - DONE
715895.838650 initTransportsRank:1054 NCCL TRACE rank 0 nranks 2 - DONE
NCCL INFO comm 0x212a200 rank 0 nranks 2 cudaDev 0 busId 3f000 - Init COMPLETE
715939.466883 ncclCommDestroy:1476 NCCL TRACE comm 0x212a200 rank 0 nRanks 2 cudaDev 0 busId 3f000
715939.492722 commReclaim:1408 NCCL TRACE commReclaim: reclaim comm 0x212a200 rank 0 state 0
715939.500821 commDestroySync:1309 NCCL TRACE Destroying comm 0x212a200 rank 0 abortFlag 0 asyncResult 0
NCCL INFO comm 0x212a200 rank 0 nranks 2 cudaDev 0 busId 3f000 - Destroy COMPLETE
[Rank 0] Success
Cuda Graph
cudaGraph_t graph;
cudaStreamBeginCapture(stream);
kernel_A<<< ..., stream >>>(...);
kernel_B<<< ..., stream >>>(...);
ncclAllreduce(..., stream);
kernel_C<<< ..., stream >>>(...);
cudaStreamEndCapture(stream, &graph);
cudaGraphExec_t instance;
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
bool graphCreated=false;
cudaGraph_t graph;
cudaGraphExec_t instance;
for(int istep=0; istep<NSTEP; istep++){
if(!graphCreated){
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
graphCreated=true;
}
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
}
ENV
NCCL_GRAPH_DUMP_FILE可以保存网络拓扑信息到文件
References
Megatron
Megatron 三篇论文
- 1909.08053 : tensor parallel
- 2104.04473 : pipeline, 1F1B, virtual pipeline
- 2205.05198 : sequence parallel, selective recompute
Tensor parallel
- MLP 切分的核心在于两个 Linear 层中间存在非线形 activation 如 relu,所以前切 col 后切 row 可解
- Attention 切分的核心在于 multi-head 的 head 间是独立的,简单切分即可
Pipeline
- G-pipe,基本的 pipeline,有比较多的 bubble,提出了 re-materialization 减少显存占用
- PipeDream,提出 1F1B 模式,及时调度反向,减少 bubble,减少显存占用
- Virtual pipeline,提出 virtual_pipeline_stage 减小切分粒度,通过增加 pipeline 内通信减少 bubble
Sequence-parallel
在 Tensor parallel 模式下,dropout + layer-norm 部分并没有切分,占用显存非常高,通过添加数据切分+通信算子达到降低显存占用的目的。
- MP: allreduce
- SP: allgather + reduce-scatter
Selective Activation Recomputation
计算量小数据量大的 activation 不保存,使用 recompute。
main grad
layer_norm / batch_norm
deepspeed
nanochat
Overview
Tokenizer
rustbpe: ligthtweight BPE tokenizer in Rust
tiktoken: fast BPE tokenizer in Rust with Python bindings by OpenAI
import tiktoken
enc = tiktoken.get_encoding("o200k_base")
assert enc.decode(enc.encode("hello world")) == "hello world"
# To get the tokeniser corresponding to a specific model in the OpenAI API:
enc = tiktoken.encoding_for_model("gpt-4o")
minbpe: both training and inference in inefficient Python
References
papers
Pollux
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Aurick Qiao et al. Petuum, Inc, CMU, UCB, MBZUAI.
Award: Jay Lepreau Best Paper
集群调度的目标是为任务分配资源使得
- 训练时间小
- 集群资源利用率高
- 同时保证公平
一般的调度场景是提交任务时声明所需要的资源, 但是在深度学习任务中,资源分配之后如何高效地利用这些资源取决于如 batch size 和 learning rate 之类的配置, 这些配置一般是不属于调度器管理的。
由此,推出
Pollux: Co-adaptive Cluster Scheduler for DL
Pollux, 一个深度学习模型训练的互适应集群调度器。
它自动且动态地,
- 从整个集群性能和公平性的角度进行资源分配
- 动态地为每个训练任务调整 batch size 和 learning rate
什么是互适用呢?
- 从整个集群的角度做调度决策,同时在任务级别来调整配置参数
- 单个任务会根据分配到的资源进行动态地调整
结果:减少用户对任务的手动配置,缩短平均训练时常达 37-50%.
背景
分布式-深度学习模型训练-数据并行
- mini-batch 组装 [batch size]
- 计算梯度 [计算密集]
- 梯度聚合 [通信密集]
- 更新参数 [learning rate]
batch size 对系统吞吐量的影响
总体而言,大 batch size 能够获得更高的吞吐,同时,这个关系
- 次/非线性 sub-linearly
- 一定量后,系统吞吐量不再随 gpu 数量提高
问题在与多少 gpu 合适呢?这取决于
- 模型结构
- 集群硬件
- batch size 等等
batch size 对实际效率(statistical efficiency)的影响
batch size 并不是越大越好,因为
- 需要同时调整 lr 确保模型质量(quality)[应该包括精度等指标],而且很困难
- 增大 batch size 会降低训练的实际效率
- 大 batch size 训练的模型往往泛化能力较差
对于同样的数据吞吐量,大 batch size 所需要的训练步数较少(二者乘积一定), 但从模型实际效率上看,大 batch size 需要更多步数才能取得同样的效果。
整体训练性能
经过以上分析可以看出,系统的吞吐和实际的训练效率相对于 batch size 存在经典的 trade-off 曲线关系, 所以,我们需要也可以找出他们的交叉点以获得优化的整体训练性能。
然而,这个优化的 batch size 在不同的训练阶段是不一样的(即随时间变化),最多能差 10 倍多 [McCandlish et al. 2018], 即需要随训练进度动态地调整 batch size 以获得最优。
集群调度
- 所需的 GPU 的取决于 batch size,反过来,合适的 batch size 取决于分配到的 GPU 资源
- 集群的 GPU 分配是一个全局的决策,需要考虑公平和竞争
- batch size 的选取还取决于具体的任务,如拓展性和实际效率等
用户在提交任务时决定上述配置是困难的,所以由集群调度器来调整这些配置参数可以优化深度学习模型的训练。
Pollux 集群调度器
- 计算模型训练性能
- 计算最优的资源需求、batch size、learning rate
- 重新调整资源分配,相应地调整任务的 batch size 和 learning rate
Key Idea: Goodput, not Throughput
Pollux 的优化目标是新定义的深度学习训练性能指标 goodput
其中,
- 资源分配向量,如 a_n = #GPU, 表示节点 n 上分配的 gpu 数
- 每个 gpu 的 batch size
- 梯度聚合步数
- 总 batch size,
会在训练过程中由 Pollux 自动计算, 表示的是系统吞吐量(examples/second), 表示实际训练效率(progress/example).
系统吞吐
其中,
- 每步训练的时间
- 计算梯度的时间
- 网络通信的时间
- 梯度聚合的步数
- 计算和通信重合度
Pollux 自动,
- 确定合适的 gpu 数量和 batch size
- 使用梯度聚合提高 batch size 达到 gpu 显存上限
- 把任务尽可能放置(pack)在尽量少的节点上以减少网络负载
实际训练效率
每一个任务的实际训练效率可以表示为
其中,
- 表示用户定义的 baseline batch size
- 表示 batch size
- 梯度噪声 [McCandlish et al. 2018]
用户可以选择较小的初始 batch size ,Pollux 会选择不同的 bs 去平衡系统吞吐和实际训练效率。
关于梯度噪声 Gradient noise scale
- 较大的梯度噪声 -> 使用较大的 mini-batch 能够获得较高的实际效率
- 接近收敛的低信噪比 -> 更好的实际训练效率
Pollux 能够在不进行提前训练的情况下使用 计算出任务的 GOODPUT.
任务优化
在特定分配 gpu 为 a 的前提下,计算最优
改变 batch size 的同时,learning rate 也需要同步改变。 Pollux 为用户提供更新策略
- Linear scaling
- Square-root scaling
- AdaScale (Johnson et al. 2020)
集群优化
优化目标
其中,
p 是可变参数,用于控制任务间的公平性。
找到分配矩阵 , 表示节点 n 上分配给任务 j 的 gpu 数量。
- 对 A 的寻找使用 metaheuristic algorithm
- 调度要避免频繁的重新分配
- 避免分布式任务共享节点
Pollux 效果评估
Pollux 带来的主要收益是在共享集群上自动配置任务。
重点评估目标:即使任务已经给定理想的静态配置,Pollux 仍然能够相比于传统集群调度器有所提升。 包括以下方面,
- 真实的 Microsoft 深度学习分布式训练集群 (Jeon et al. 2019).
- 不同场景训练任务混合:图像分类、目标检测、语音识别、问答、推荐
- 手动配置 gpu 数量、batch size、learning rate、梯度聚合参数 (不使用Pollux,设定强baseline)
实验数据表明 Pollux 能比专家配置的任务缩短 37-50% 的平均训练时间。
总结
- Pollux 同时从集群和任务的角度对任务参数进行优化
- Pollux 引入 goodput 概念,一种结合系统吞吐和实际效率的衡量标准
- Pollux 实测缩短 37-50% 的平均训练时间
Scaling distributed training with adaptive summation
Saeed Maleki et al. Microsoft Research
Key point
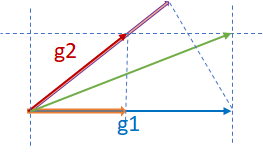
Reference
Adaptation 调研
分布式训练的参数调整基本有以下共识:
- learning rate 需要根据 batch size 调整,以保证训练速度和收敛速度
- learning rate 需要在不同的训练阶段进行调整以保证收敛速度 这个方向早期已经有比较多的研究,包括
- Adam 2015,在 variance 较大时使用较小的 lr
- LARS 2017,在每一层上根据 wieghts 和 gradient 适配 lr
- LARM 2019,LARS + Adam
Summary
最新的一些参数适配相关的研究进展:
| 方法 | 年份 | 适用 | 作用于 | Key Idea | 会议 | 开源 |
|---|---|---|---|---|---|---|
| GNS | 2018 | |||||
| K-FAC | 2019 | - | gradients | Gradient second-order | cvpr2019 | |
| AdaScale | 2020 | SGD | lr | Gradient variance | ICML2020 | |
| Resource Elasticity... | 2020 | tf | framework | Worker performance | mlsys2020 | |
| Kungfu | 2020 | tf/torch | - | implementation | osdi20 | KungFu |
| Pollux | 2021 | osdi21 | adaptdl | |||
| Adasum | 2021 | Momentum-SGD, Adam, and LAMB | gradients | combine gradient | mlsys2021 | horovod |
| DeepPool | 2022 | burst parallelism | gpu multiplexing | mlsys2022 | DeepPool |
An Empirical Model of Large-Batch Training Sam McCandlish et al. OpenAI 总结:文章提出了 gradient noise scale (GNS) 指标,
- GNS 较小,保持 batch size
- GNS 较大,增大 batch size GNS 定义如下:
其中:
- true gradient
- true Hessian at parameter values
- covariance matrix
AdaScale SGD: A Scale-Invariant Algorithm for Distributed Training
Tyler B. Johnson et al. APPLE
Key: Gradient variance
总结:adascale 根据 gradient variance 来调整 learning rate,提供稳定算法保证在不同的 batch size 下都能找到合适的 lr 保证快速收敛。
Scaling distributed training with adaptive summation
Saeed Maleki et al. Microsoft Research
总结:adasum 利用 gradients 自身的数学性质,提出了一种新的 combine 方法,使得 merge 结果受 outlier 影响较小,更加“合理”,从而加快收敛。 算法公式
示意图
Large-Scale Distributed Second-Order Optimization Using Kronecker-Factored Approximate Curvature for Deep Convolutional Neural Networks
Kazuki Osawa et al. Tokyo Institute of Technology, NVIDIA
Key: Gradient second-order metrics
总结:通过计算 Fisher 矩阵二阶信息来更新梯度,每一步的计算速度会慢于sgd,但收敛所需步数减少,特别是在large scale 的场景,整体效率接近。
Resource Elasticity in Distributed Deep Learning
Andrew Or et al. Princeton University, Google AI
autoscaling engine/system
总结:文章对分布式场景深度学习场景下的弹性系统进行了比较全面的梳理,着墨较多在弹性触发条件,但是对系统实现没有什么深入描述,这块创新性存疑。文中提到了依赖 tensorflow 和 horovod,姑且认为,默认实现方案为 horovod 吧。 文中涉及到了类似慢节点检测的机制(STRAGGLER DETECTION)。
KungFu: Making Training in Distributed Machine Learning Adaptive
Luo Mai et al. Imperial College London
总结:kungfu 提供了一个统一的框架/库用来在分布式训练场景下进行不同 adaptation 操作,包括 api、monitor、control 等部分。
- 提供 adaption policies 来定义不同 adaption
- 内置 monitoring,使得依赖各种 metric 做 adapt 决策变得容易
- 分布式参数 adpating 机制:提供弹性、异步 collective
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Aurick Qiao et al. Petuum, Inc, CMU, UCB, MBZUAI.
总结:提出 goodput 指标用于计算优化配置,包括资源和参数 lr、bs。兼容其他如 adascale 策略。
Efficient Strong Scaling Through Burst Parallel Training
Seo Jin Park et al.
DeepPool key ideas: 引入 foreground/background jobs
- burst parallelism
- GPU multiplixing : gpu 共享
batch-optimal scaling : find (throughtput , sample efficienncy) for best time to accuracy
- Optimizing time-to-accuracy requires small per-GPU batches at large scale
- Strong scaling and small per-GPU batches are more effective with fast networks
- None of the approaches achieve perfect linear scaling
实现特点:
- 控制粒度到 layer 级别
- 针对静态图,生成 parallel training plan
- stage 级别分配 gpu
- backgroud job 为单机低优任务,现实场景中可能比较难有这样类型任务
总结:依靠并行调度和 gpu 共享技术,引入foreground/background 区分任务优先级,计算最优资源需求和参数配置以获得高资源利用率和任务完成时效。 有点偏向于自动并行和 gpu 共享的混合产物。
strong scaling : hold global batch size constant, decrease per-GPU batch size weak scaling: increase the global batch size correspondingly, per-GPU batch size kept constant
Gradient Descent
An overview of gradient descent optimization algorithms
Sebastian Ruder, Insight Centre for Data Analytics, NUI Galway Aylien Ltd., Dublin, 2017
Gradient Descent
Multi-variable function , defined differentiable in a neighborhood of a point , for small enough,
leads to .
If convex and Lipschitz, converge to a local mimimum.
Optimization : Momentum
Let ,
The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.
Optimization : Nesterov
Version with correction,
This anticipatory update prevents us from going too fast and results in increased responsiveness, which has significantly increased the performance of RNNs on a number of tasks.
Adagrad
It adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. For this reason, it is well-suited for dealing with sparse data.
Application : learned to recognize cats in Youtube videos; GloVe word embeddings.
Adadelta
Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size w.
RMSprop
RMSprop and Adadelta have both been developed independently around the same time stemming from the need to resolve Adagrad’s radically diminishing learning rates. RMSprop in fact is identical to the first update vector of Adadelta.
Adam
Adaptive Moment Estimation (Adam) is another method that computes adaptive learning rates for each parameter. In addition to storing an exponentially decaying average of past squared gradients like Adadelta and RMSprop, Adam also keeps an exponentially decaying average of past gradients , similar to momentum.
PyTorch Implementation
SGD, Momentum
The implementation of SGD with Momentum/Nesterov subtly differs from Sutskever et. al. and implementations in some other frameworks.
Considering the specific case of Momentum, the update can be written as
where , , and denote the parameters, gradient, velocity, and momentum respectively.
This is in contrast to Sutskever et. al. and other frameworks which employ an update of the form
The Nesterov version is analogously modified.
# torch/optim/sgd.py
def _single_tensor_sgd(params: List[Tensor],
d_p_list: List[Tensor],
momentum_buffer_list: List[Optional[Tensor]],
*,
weight_decay: float,
momentum: float,
lr: float,
dampening: float,
nesterov: bool,
maximize: bool,
has_sparse_grad: bool):
for i, param in enumerate(params):
d_p = d_p_list[i]
if weight_decay != 0:
d_p = d_p.add(param, alpha=weight_decay)
if momentum != 0:
buf = momentum_buffer_list[i]
if buf is None:
buf = torch.clone(d_p).detach()
momentum_buffer_list[i] = buf
else:
buf.mul_(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
d_p = d_p.add(buf, alpha=momentum)
else:
d_p = buf
alpha = lr if maximize else -lr
param.add_(d_p, alpha=alpha)
Adagrad
Algorithm
# torch/optim/adagrad.py
def _single_tensor_adagrad(params: List[Tensor],
grads: List[Tensor],
state_sums: List[Tensor],
state_steps: List[Tensor],
*,
lr: float,
weight_decay: float,
lr_decay: float,
eps: float,
has_sparse_grad: bool):
for (param, grad, state_sum, step_t) in zip(params, grads, state_sums, state_steps):
# update step
step_t += 1
step = step_t.item()
if weight_decay != 0:
if grad.is_sparse:
raise RuntimeError("weight_decay option is not compatible with sparse gradients")
grad = grad.add(param, alpha=weight_decay)
clr = lr / (1 + (step - 1) * lr_decay)
if grad.is_sparse:
grad = grad.coalesce() # the update is non-linear so indices must be unique
grad_indices = grad._indices()
grad_values = grad._values()
size = grad.size()
state_sum.add_(_make_sparse(grad, grad_indices, grad_values.pow(2)))
std = state_sum.sparse_mask(grad)
std_values = std._values().sqrt_().add_(eps)
param.add_(_make_sparse(grad, grad_indices, grad_values / std_values), alpha=-clr)
else:
is_complex = torch.is_complex(param)
if is_complex:
grad = torch.view_as_real(grad)
state_sum = torch.view_as_real(state_sum)
param = torch.view_as_real(param)
state_sum.addcmul_(grad, grad, value=1)
std = state_sum.sqrt().add_(eps)
param.addcdiv_(grad, std, value=-clr)
if is_complex:
param = torch.view_as_complex(param)
state_sum = torch.view_as_complex(state_sum)
Adam
Algorithm
# torch/optim/adam.py
def _single_tensor_adam(params: List[Tensor],
grads: List[Tensor],
exp_avgs: List[Tensor],
exp_avg_sqs: List[Tensor],
max_exp_avg_sqs: List[Tensor],
state_steps: List[Tensor],
*,
amsgrad: bool,
beta1: float,
beta2: float,
lr: float,
weight_decay: float,
eps: float,
maximize: bool):
for i, param in enumerate(params):
grad = grads[i] if not maximize else -grads[i]
exp_avg = exp_avgs[i]
exp_avg_sq = exp_avg_sqs[i]
step_t = state_steps[i]
# update step
step_t += 1
step = step_t.item()
bias_correction1 = 1 - beta1 ** step
bias_correction2 = 1 - beta2 ** step
if weight_decay != 0:
grad = grad.add(param, alpha=weight_decay)
# Decay the first and second moment running average coefficient
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
exp_avg_sq.mul_(beta2).addcmul_(grad, grad.conj(), value=1 - beta2)
if amsgrad:
# Maintains the maximum of all 2nd moment running avg. till now
torch.maximum(max_exp_avg_sqs[i], exp_avg_sq, out=max_exp_avg_sqs[i])
# Use the max. for normalizing running avg. of gradient
denom = (max_exp_avg_sqs[i].sqrt() / math.sqrt(bias_correction2)).add_(eps)
else:
denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(eps)
step_size = lr / bias_correction1
# param = param - step_size * (exp_avg / denom)
# element-wise division
param.addcdiv_(exp_avg, denom, value=-step_size)
AdamW is Adam with correct Weight Decay, when weight decay is 0, there is no difference between Adam and AdamW.
Auto Parallel
A Survey on Auto-Parallelism of Neural Networks Training
Peng Liang et. al. National University of Defense Technology
Abstract.
DL --> large model --> distributed training --> heterogeneous cluster --> auto-parallelism --> large scale DL model
- basic parallelism schemes, communication cost and memory consumption
- current works, strategies, common methods
- promising trends
Introduction
Parallelism strategy
- intra-operator parallelism: data parallelism, tensor parallelism (intra-layer model parallelism)
- inter-operator parallelism: inter-layer model parallelism, pipeline parallelism
Hybrid parallelism
- data + model + pipeline
- Megatron-LM, DeepSpeed(3D parallelism)
Manual --> Auto
All practicable works: a few combinations of parallelism schemes, weak scalability
- e.g. cost model
- automatic parallelism search space can be further expanded
- heterogeneous devices, communication pace/topology
Challenges
- detailed analysis of different parallelism schemes
- trade-offs between different parallelism schemes
- load-balance across heterogeneous devices
- optimization of network communication
- trade-off between runtime and strategy performance in finding strategy
Parallelism schemes
Data parallelism
- Vanilla DP
- ZeRO-Powered DP
- Communication of DP, Centralized/Decentralized architecture
ZeRO-DP
- three stages: 1 partition optimizer states, 2 partition gradients and optimizer states, 3 partition parameters
- stage 1 and 2: reduce-scatter accumulated gradients, stage 3: all-gather updated parameters
- solve redundancy problem with 50% more communication volume (all-gather)
Model parallelism
- Intra-layer MP, tensor parallelism, partition weight tensor
- Inter-layer MP
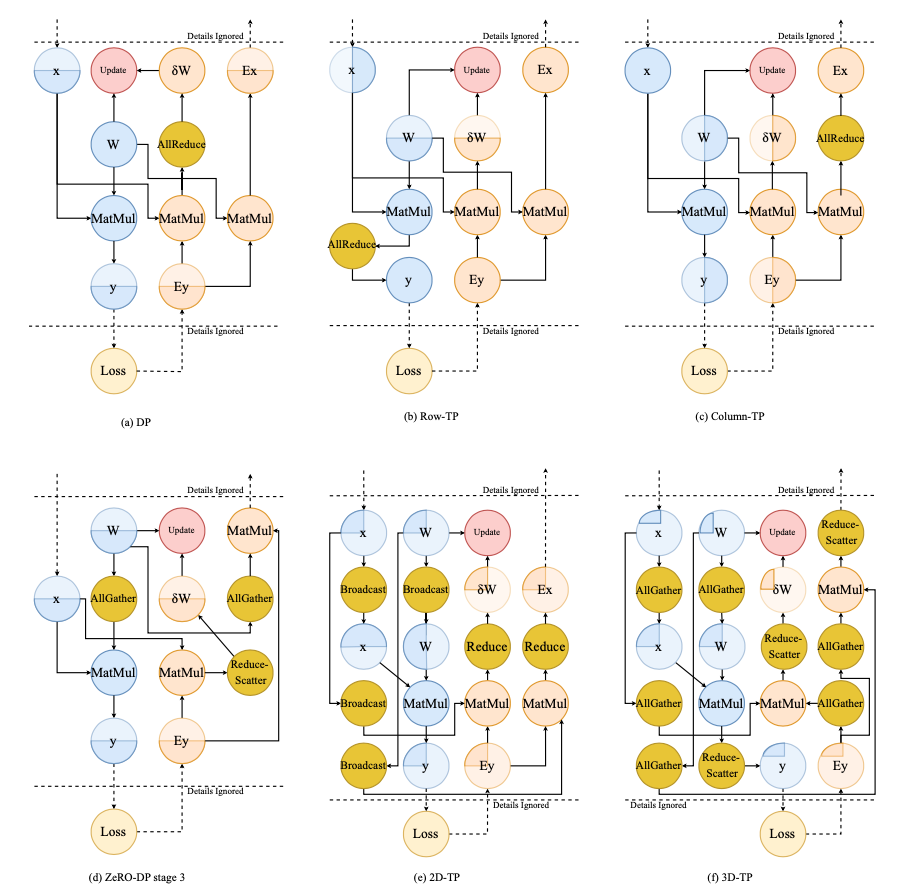
Pipeline parallelism
The partition pattern of PP is the same as that of MP
- inter-layer MP = PP
- PP = well scheduled pipelined MP
- overlap computation, solve low-utility of MP
PipeDream (Microsoft), GPipe (Google)
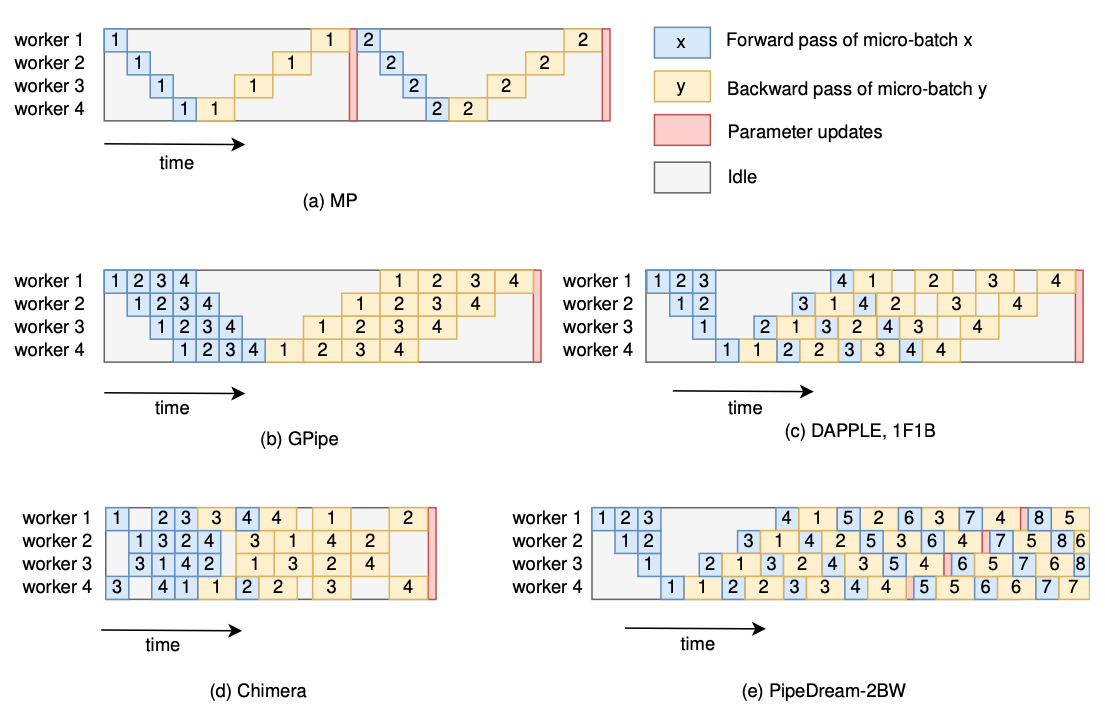
Strategy Searching Methods for Auto-Parallelism
- NP-hard problem
- classic-algorithm-based v.s. machine-learning-based
Classic-algorithm based methods
- recursive algorithm
- dynamic programming algorithm
- integer linear programming algorithm
- breath-first-search (BFS) algorithm
Machine-learning based methods
- Monte-Carlo Markov Chain (MCMC)
- Monte-Carlo Tree Search (MCTS)
- reinforcement learning
Conclusion
Accelerating strategy searching
- grouping
- profiling-base cost model
- using heuristics
Optimizing parallelism strategies
- topology-aware computation
- topology-aware communication
Supporting more parallelism schemes
Scheduling
OSDI 2021
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Aurick Qiao et al. Petuum, Inc, CMU, UCB. Cite 14
Award: Jay Lepreau Best Paper
Oort: Efficient Federated Learning via Guided Participant Selection
Fan Lai et al. University of Michigan. Cite 17
PET: Optimizing Tensor Programs with Partially Equivalent Transformations and Automated Corrections
Haojie Wang et al. Tsinghua, CMU, FB. Cite 4
Privacy Budget Scheduling
Tao Luo et al. Columbia University, Microsoft Research. Cite 2
OSDI 2020
Providing SLOs for Resource-Harvesting VMs in Cloud Platforms
Pradeep Ambati et al. Microsoft Azure, Microsoft Research.
The CacheLib Caching Engine: Design and Experiences at Scale
Benjamin Berg et al. CMU, FB, MS
Twine: A Unified Cluster Management System for Shared Infrastructure
Chunqiang Tang et al. FB
FIRM: An Intelligent Fine-Grained Resource Management Framework for SLO-Oriented Microservices
Haoran Qiu et al. UIUC
Building Scalable and Flexible Cluster Managers Using Declarative Programming
Lalith Suresh et al. VMware, IST, UIUC ...
Protean: VM Allocation Service at Scale
Ori Hadary et al. MS
1-Bit Stochastic Gradient Descent and its Application to Data-Parallel Distributed Training of Speech DNNs
Frank Seide et. al. MRA, Tsinghua, MR. INTERSPEECH 2014
1-BitSGDwithErrorFeedback
总结:1 bit 量化的思路是把每个 32 位的值按照正负分别用 1 或 0 量化,然后通信,更新时 1 则更新 +1,0 则更新 -1,同时本地量化差异保留补偿。这样的效果应该相当于本地梯度累积,每次通信根据正负同步 1 个单位的量。当然,每次更新带上系数,最终得到收敛效果。
1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
Hanlin Tang et. al. Microsoft 2021
总结:adam 的梯度更新是非线性的,沿用 1bit sgd 的梯度累积或者说梯度补偿策略无法保证收敛性,文章提出了针对 adam 的保证收敛性的 1 bit 梯度量化方法并给出了理论证明。方法的核心在于在 warm-up 阶段计算 momentum 方差,用于后面进行误差补偿的计算。
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
Yujun Lin et. al. Tsinghua University, ICLR 2018
Optimizing Network Performance for Distributed DNN Training on GPU Clusters: ImageNet/AlexNet Training in 1.5 Minutes
Peng Sun et. al. SenseTime 2019
GRACE: A Compressed Communication Framework for Distributed Machine Learning
Hang Xu et. al. 2021
SIDCo An Efficient Statistical-based Gradient Compression Technique for Distributed Training Systems
Ahmed M. Abdelmoniem et. al. CEMSE, KAUST. MLSys 2021
PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization
Thijs Vogels et. al. EPFL. NeurIPS 2019
Don't Use Large Mini-Batches, Use Local SGD
Tao Lin et. al. EPFL. ICLR 2020
总结:为减轻同步模式中慢节点的影响,可以减少通信,这会带来精度损失。使用 local SGD 的方法可以现在节点内进行 SGD 更新,多步之后再同步各个节点上的参数。 post local SGD 的方法将训练过程分成两阶段:先使用同步 SGD,再增大同步间隔提高训练吞吐。
Adaptive Communication Strategies to Achieve the Best Error-Runtime Trade-off in Local-Update SGD
Jianyu Wang et. al. Carnegie Mellon University. SysML 2019
总结:动态调整参数同步间隔来平衡训练吞吐和精度。
Overlap Local-SGD: An Algorithmic Approach to Hide Communication Delays in Distributed SGD
Jianyu Wang et. al. ICASSP 2020
Deep Gradient Compression
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
Yujun Lin et. al. Tsinghua University, ICLR 2018
Gradient exchange require hight bandwidth,
- high latency
- low throughput
- poor connnection
Since 99.9% of the gradient exchange in SGD are redundant, propose deep gradient compression (DGC) to reduce communication bandwidth.
To preserve accuracy,
- momentum correction
- local gradient clipping
- momentum factor masking, alleviate staleness
- warm-up training
improving local gradient accumulation and overcomming the staleness effect
DGC
- pushes the gradient compression ratio to up to 600×
- not need to change the model structure
- no loss of accuracy
How
- only gradients larger than a threshold are transmitted
- accumulate the rest of the gradients locally, local gradient accumulation is equivalent to increasing the batch size over time
DGC naively perform fine-grained (i.e., element-wise) top-k to select gradients, and thus the communication will suffer from increased allgather data volume as #nodes increases.
CSC modified the process with coarse-grained sparsification: gradients are partioned into chunks, allreduce the gradient chunks selected based on allreduced L1-norm of each chunk, which gets rid of the allgather and solves the problem.
deep-gradient-compression github
配置
# configs/dgc/__init__.py
训练流程
# train.py
from dgc.horovod.optimizer import DistributedOptimizer
# from dgc.compression import DGCCompressor
compression = configs.train.compression()
# cpr_parameters 即 dgc 处理的范围
compression.initialize(cpr_parameters.items())
# from dgc.optim import DGCSGD
optimizer = configs.train.optimizer(model.parameters())
# Horovod: wrap optimizer with DistributedOptimizer.
optimizer = DistributedOptimizer(
optimizer, named_parameters=model.named_parameters(),
compression=compression,
backward_passes_per_step=configs.train.num_batches_per_step,
op=hvd.Average
)
# 训练基本循环 zero_grad -> loss.backward -> optimizer.step
# 特别注意这里多次 backward 才走一次 step 更新
model.train()
for step, (inputs, targets) in enumerate(...):
optimizer.zero_grad()
# 这里用了内置循环累积梯度,比直接使用大 batch 剩显存
# 注意这个 for 循环,对于 optimizer 里面理解 synchronize 过程非常重要
for b in range(0, step_size, batch_size):
_inputs = inputs[b:b+batch_size]
_targets = targets[b:b+batch_size]
_outputs = model(_inputs)
_loss = criterion(_outputs, _targets)
_loss.mul_(_r_num_batches_per_step)
_loss.backward()
loss += _loss.item()
optimizer.step()
Optimizer
# dgc/horovod/optimizer.py
class _DistributedOptimizer(torch.optim.Optimizer):
def __init__(self, ...):
# 初始化最后注册 通信 hook
self._register_hooks()
def _register_hooks(self):
for param_group in self.param_groups:
for p in param_group['params']:
if p.requires_grad:
# 注册函数只执行一次,这里 zero grad 不是每次调用 hook
p.grad = p.data.new(p.size()).zero_()
self._requires_update.add(p)
# 创建幽灵 tensor 来累积梯度,节点间同步,直至更新;
# p_tmp 和 p 使用同样的 storage,不占用额外显存
p_tmp = p.expand_as(p)
grad_acc = p_tmp.grad_fn.next_functions[0][0]
# 注册 _make_hook 这个关键 hook
grad_acc.register_hook(self._make_hook(p))
self._grad_accs.append(grad_acc)
def _make_hook(self, p):
# 这个 hook 有一个计数器,_allreduce_delay, 根据对象 p 不一样可以取不一样的值
# 计数器不为零时跳过,这样可以让 grad 在本地累积,因为这个 hook 是做通信的
# 效果为这个 hook 在多次调用才会被执行一次
def hook(*ignore):
handle, ctx = None, None
self._allreduce_delay[p] -= 1
if self._allreduce_delay[p] == 0:
handle, ctx = self._allreduce_grad_async(p)
self._handles[p] = (handle, ctx)
return hook
# 然后主要流程 step
def step(self, closure=None):
self.synchronize()
return super(self.__class__, self).step(closure)
# step 调用 synchronize, 可以有跳过逻辑
def synchronize(self):
# 处理 hook 注册不成功,或者说 hook 没有被调用
# hook 被调用后会添加 self._handles
missing_p = self._requires_update - set(self._handles.keys())
for p in missing_p:
handle, ctx = self._allreduce_grad_async(p)
self._handles[p] = (handle, ctx)
# handle 为 None 的 hook 跳过又不跳过了?
# 需要注意 synchronize 函数每个 step 被调用,但不是每次 backward 都会被调用
# 在之前的 train 中有每个 step 会多次 backward,所以 grad 的 hook 会被多次调用,次数匹配
# 所以代码执行到这里 handle 应该是一次调用_allreduce_grad_async 如果不是就补上
for p, (handle, ctx) in self._handles.items():
if handle is None:
handle, ctx = self._allreduce_grad_async(p)
self._handles[p] = (handle, ctx)
# for 循环处理异步通信的结果
for p, (handle, ctx) in self._handles.items():
output = self._synchronize_(handle)
# 重置本地累积次数
self._allreduce_delay[p] = self.backward_passes_per_step
# 解压更新梯度
p.grad.set_(self._compression.decompress(output, ctx))
# 执行完毕,清理
self._handles.clear()
# 异步通信的 op,核心逻辑在 compression 中
def _allreduce_grad_async(self, p):
name = self._parameter_names.get(p)
tensor_compressed, ctx = self._compression.compress(p.grad, name)
handle = self._communicate_(tensor_compressed, name=name, op=self.op)
return handle, ctx
- hook 函数是一次注册,多次调用,所以
self._handles会不断被填充,每次 synchronize 后可以被 clear
# dgc/compression.py
class DGCCompressor:
def __init__(self, ...):
self.attributes = {}
def initialize(self, named_parameters):
# 工作范围
for name, param in named_parameters:
self.attributes[name] = (numel, shape, num_selects, num_samples, top_k_samples, sample_stride)
def _sparsify(self, tensor, name):
# 选出稀疏的 tensor 去通信
# 原实现中比较复杂
# 先随机选取部分梯度值的 TOPK 来计算阈值
# 然后通过该阈值对原 tensor 做稀疏化
importance = tensor.abs()
mask = torch.ge(importance, threshold)
indices = mask.nonzero().view(-1)
num_indices = indices.numel()
# 这里实现上有个 for 循环确保选出的 topk 满足要求
indices = indices[:num_selects]
values = tensor[indices]
return values, indices, numel, shape, num_selects
def compress(self, tensor, name):
if self.compress_ratio < 1.0 and name in self.attributes:
# compress
tensor_compensated = self.memory.compensate(tensor, name, accumulate=True)
values, indices, numel, shape, num_selects = self._sparsify(tensor_compensated, name)
self.memory.update(name, (indices, ))
return tensor, ctx
else:
return tensor, ctx
def decompress(self, tensor, ctx):
name, numel, shape, vdtype, idtype, grad = ctx
if self.compress_ratio < 1.0 and name in self.attributes:
# 这里的 tensor 是个 tuple
# decompress
values, indices = tensor
# 把同步回来的稀疏 tensor 对应位置更新
# accumulate=True 处理 indices 中有重复的情况
grad.zero_().index_put_([indices], values, accumulate=True)
if self.op == Average:
grad.mul_(1. / self.world_size)
return grad.view(shape)
else:
return self.memory.compensate(tensor, name, accumulate=False)
# optimizer _communicate_
def communicate(self, tensor_compressed, name, op):
# 两个分支
if self.compress_ratio < 1.0 and name in self.attributes:
# dgc 分支,tensor_compressed 是 tuple,各个节点选的 topk index 不相同
# 所以使用 allgather 交换,然后各自解压、更新
return [allgather_async_(t, name=f'{name}.t{e}')
for e, t in enumerate(tensor_compressed)]
else:
# 普通分支,直接 allreduce 完整 tensor
return allreduce_async_(tensor_compressed, name=name, op=op)
# optimizer _synchronize_
def synchronize(self, handle):
# from horovod.torch.mpi_ops import synchronize as synchronize_
if isinstance(handle, (tuple, list)):
return [synchronize_(h) for h in handle]
else:
return synchronize_(handle)
为了保证精度文章中介绍了下面几种补偿策略
- momentum correction
- local gradient clipping
- momentum factor masking, alleviate staleness
- warm-up training
前三种策略在 Memory 实现
# dgc/memory.py
class DGCSGDMemory(Memory):
def compensate(self, grad, name, accumulate=True):
if self.gradient_clipping is not None:
grad = self.gradient_clipping(grad)
mmt = self.momentums[name]
if accumulate:
# Momentum Correction
vec = self.velocities[name]
if self.nesterov:
mmt.add_(grad).mul_(self.momentum)
vec.add_(mmt).add_(grad)
else:
mmt.mul_(self.momentum).add_(grad)
vec.add_(mmt)
return vec
else:
if self.nesterov:
mmt.add_(grad).mul_(self.momentum)
return mmt.add(grad)
else:
mmt.mul_(self.momentum).add_(grad)
return mmt.clone() # TODO: save this clone
def update(self, name, ctx):
indices = ctx[0]
if self.momentum_masking:
self.momentums[name].view(-1).index_fill_(0, indices, 0)
self.velocities[name].view(-1).index_fill_(0, indices, 0)
Optimizing Network Performance for Distributed DNN Training on GPU Clusters: ImageNet/AlexNet Training in 1.5 Minutes
Peng Sun et. al. SenseTime 2019
Communication backend: GradientFlow
- ring-based allreduce
- mixed-precision training
- computation/communication overlap
- lazy allreduce: fusing multiple communication operations
- coarse-grained sparse communication: only transmitting important gradient chunks
and also,
- momentum SGD correction
- warm-up dense training
DGC naively perform fine-grained (i.e., element-wise) top-k to select gradients, and thus the communication will suffer from increased allgather data volume as #nodes increases.
CSC modified the process with coarse-grained sparsification: gradients are partioned into chunks, allreduce the gradient chunks selected based on allreduced L1-norm of each chunk, which gets rid of the allgather and solves the problem.
Flash Attention
Key Idea
- memory hierachy: GPU HBM (40G, 1.5TB/s) -> GPU SRAM (20MB, 19TB/s)
- tiling: split the input into blocks and make several passes over blocks, fit GPU SRAM
- recompute: recompute attention on-chip in the backward pass instead of retrieve from HBM
Conclusion: increase FLOPs, decrease Wall-clock time
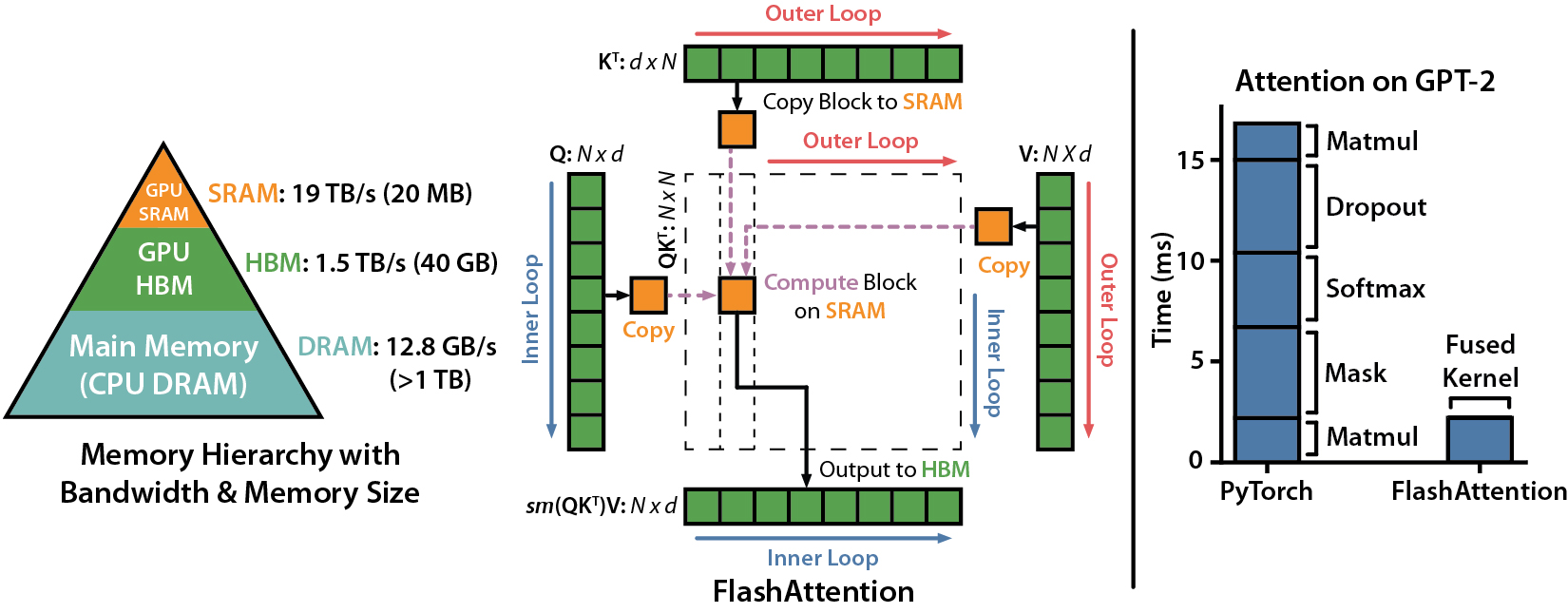
Code Details
Modules
flash_attn
// csrc/flash_attn/fmha_api.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.doc() = "Fused Multi-head Self-attention";
m.def("fwd", &mha_fwd, "Forward pass");
m.def("bwd", &mha_bwd, "Backward pass");
m.def("fwd_block", &mha_fwd_block, "Forward pass (blocksparse)");
m.def("bwd_block", &mha_bwd_block, "Backward pass (blocksparse)");
}
fused_dense_lib
// csrc/fused_dense_lib/fused_dense.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("linear_bias_forward", &linear_bias_forward, "linear bias forward");
m.def("linear_bias_backward", &linear_bias_backward, "linear bias backward");
m.def("linear_bias_wgrad", &linear_bias_wgrad, "linear bias wgrad");
m.def("linear_bias_residual_backward", &linear_bias_residual_backward, "linear bias residual backward");
m.def("linear_gelu_forward", &linear_gelu_forward, "linear gelu forward");
m.def("linear_gelu_linear_backward", &linear_gelu_linear_backward, "linear gelu linear backward");
m.def("linear_residual_gelu_linear_backward", &linear_residual_gelu_linear_backward, "linear residual gelu linear backward");
}
fused_softmax
// csrc/fused_softmax/fused_softmax.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("scaled_masked_softmax_forward", &multihead_attn::fused_softmax::scaled_masked_softmax::fwd, "Self Multihead Attention scaled, time masked softmax -- Forward.");
m.def("scaled_masked_softmax_backward", &multihead_attn::fused_softmax::scaled_masked_softmax::bwd, "Self Multihead Attention scaled, time masked softmax -- Backward.");
m.def("scaled_masked_softmax_get_batch_per_block", &multihead_attn::fused_softmax::scaled_masked_softmax::get_batch_per_block, "Return Batch per block size.");
m.def("scaled_upper_triang_masked_softmax_forward", &multihead_attn::fused_softmax::scaled_upper_triang_masked_softmax::fwd, "Self Multihead Attention scaled, time masked softmax -- Forward.");
m.def("scaled_upper_triang_masked_softmax_backward", &multihead_attn::fused_softmax::scaled_upper_triang_masked_softmax::bwd, "Self Multihead Attention scaled, time masked softmax -- Backward.");
}
layer_norm
// csrc/fused_softmax/fused_softmax.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.doc() = "CUDA DropoutAddLayerNorm";
m.def("dropout_add_ln_fwd", &dropout_add_ln_fwd, "Run Dropout + Add + LayerNorm forward kernel");
m.def("dropout_add_ln_bwd", &dropout_add_ln_bwd, "Run Dropout + Add + LayerNorm backward kernel");
}
rotary
// csrc/rotary/rotary.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("apply_rotary", &apply_rotary, "Apply rotary embedding");
}
xentropy
// csrc/xentropy/interface.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &softmax_xentropy_forward, "Softmax cross entropy loss with label smoothing forward (CUDA)");
m.def("backward", &softmax_xentropy_backward, "Softmax cross entropy loss with label smoothing backward (CUDA)");
}
Flash Attention
Python API call chains overview
FlashSelfAttention
flash_attn_func
flash_attn_unpadded_qkvpacked_func
FlashAttnQKVPackedFunc
_flash_attn_forward = flash_attn_cuda.fwd
_flash_attn_backward = flash_attn_cuda.bwd
FlashCrossAttention
flash_attn_unpadded_kvpacked_func
FlashAttnKVPackedFunc
_flash_attn_forward
_flash_attn_backward
# ----
flash_attn_unpadded_qkvpacked_split_func
FlashAttnQKVPackedSplitFunc
_flash_attn_forward
_flash_attn_backward
FlashBlocksparseAttention
flash_blocksparse_attn_func
FlashBlocksparseAttnFun
_flash_blocksparse_attn_forward = flash_attn_cuda.fwd_block
_flash_blocksparse_attn_backward = flash_attn_cuda.bwd_block
FlashSelfAttention
# flash_attn/flash_attn_interface.py
def flash_attn_unpadded_qkvpacked_func(qkv, cu_seqlens, max_seqlen, dropout_p, softmax_scale=None, causal=False, return_attn_probs=False):
return FlashAttnQKVPackedFunc.apply(qkv, cu_seqlens, max_seqlen, dropout_p, softmax_scale, causal, return_attn_probs)
class FlashAttnQKVPackedFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, qkv, cu_seqlens, max_seqlen, dropout_p, softmax_scale, causal, return_softmax):
rng_state = torch.cuda.get_rng_state() if dropout_p > 0 else None
out, softmax_lse, S_dmask = _flash_attn_forward(...)
return (out, softmax_lse, S_dmask)
@staticmethod
def backward(ctx, dout, *args):
_flash_attn_backward(...)
return dqkv, None, None, None, None, None, None
def _flash_attn_forward(q, k, v, out, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
dropout_p, softmax_scale, causal, return_softmax, num_splits=0,
generator=None):
softmax_lse, *rest = flash_attn_cuda.fwd(...)
return out, softmax_lse, S_dmask
def _flash_attn_backward(dout, q, k, v, out, softmax_lse, dq, dk, dv, cu_seqlens_q, cu_seqlens_k,
max_seqlen_q, max_seqlen_k, dropout_p, softmax_scale, causal, num_splits=0,
generator=None):
_, _, _, softmax_d = flash_attn_cuda.bwd(...)
return dq, dk, dv, softmax_d
mha_fwd + mha_bwd
// csrc/flash_attn/fmha_api.cpp
std::vector<at::Tensor>
mha_fwd(const at::Tensor &q, // total_q x num_heads x head_size, total_q := \sum_{i=0}^{b} s_i
const at::Tensor &k, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &v, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
at::Tensor &out, // total_q x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &cu_seqlens_q, // b+1
const at::Tensor &cu_seqlens_k, // b+1
const int max_seqlen_q_,
const int max_seqlen_k_,
const float p_dropout,
const float softmax_scale,
const bool zero_tensors,
const bool is_causal,
const bool return_softmax,
const int num_splits,
c10::optional<at::Generator> gen_) {
Launch_params<FMHA_fprop_params> launch_params(dprops, stream, is_dropout, return_softmax);
run_fmha_fwd(launch_params);
return result;
}
void run_fmha_fwd(Launch_params<FMHA_fprop_params> &launch_params) {
if (launch_params.params.d <= 32) {
run_fmha_fwd_hdim32(launch_params);
} else if (launch_params.params.d <= 64) {
run_fmha_fwd_hdim64(launch_params);
} else if (launch_params.params.d <= 128) {
run_fmha_fwd_hdim128(launch_params);
}
}
std::vector<at::Tensor>
mha_bwd(const at::Tensor &dout, // total_q x num_heads, x head_size
const at::Tensor &q, // total_q x num_heads x head_size, total_q := \sum_{i=0}^{b} s_i
const at::Tensor &k, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &v, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &out, // total_q x num_heads x head_size
const at::Tensor &softmax_lse_, // b x h x s softmax logsumexp
at::Tensor &dq, // total_q x num_heads x head_size, total_q := \sum_{i=0}^{b} s_i
at::Tensor &dk, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
at::Tensor &dv, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &cu_seqlens_q, // b+1
const at::Tensor &cu_seqlens_k, // b+1
const int max_seqlen_q_,
const int max_seqlen_k_, // max sequence length to choose the kernel
const float p_dropout, // probability to drop
const float softmax_scale,
const bool zero_tensors,
const bool is_causal,
const int num_splits,
c10::optional<at::Generator> gen_
) {
auto launch = &run_fmha_bwd;
FMHA_dgrad_params params;
set_params_dgrad(params, ... num_splits);
launch(params, stream, /*configure=*/true);
launch(params, stream, /*configure=*/false);
return { dq, dk, dv, softmax_d };
}
void run_fmha_bwd(FMHA_dgrad_params ¶ms, cudaStream_t stream, const bool configure) {
if (params.d <= 32) {
run_fmha_bwd_hdim32(params, stream, configure);
} else if (params.d <= 64) {
run_fmha_bwd_hdim64(params, stream, configure);
} else if (params.d <= 128) {
run_fmha_bwd_hdim128(params, stream, configure);
}
}
// csrc/flash_attn/src/fmha_fwd_hdim32.cu
#include "fmha_fwd_launch_template.h"
void run_fmha_fwd_hdim32(Launch_params<FMHA_fprop_params> &launch_params) {
FP16_SWITCH(launch_params.params.is_bf16, ({
if (launch_params.params.seqlen_k == 128) {
using Kernel_traits = FMHA_kernel_traits<128, 32, 16, 1, 4, 0x08u, elem_type>;
run_fmha_fwd_loop<Kernel_traits>(launch_params);
} else if (launch_params.params.seqlen_k >= 256) {
using Kernel_traits = FMHA_kernel_traits<256, 32, 16, 1, 4, 0x08u, elem_type>;
run_fmha_fwd_loop<Kernel_traits>(launch_params);
}
}));
}
run_fmha_fwd_loop -> fmha_fwd_loop_kernel
// csrc/flash_attn/src/fmha_fwd_launch_template.h
template<typename Kernel_traits>
void run_fmha_fwd_loop(Launch_params<FMHA_fprop_params> &launch_params) {
BOOL_SWITCH(launch_params.is_dropout, IsDropoutConst, ({
auto kernel = launch_params.params.is_causal
? (launch_params.return_softmax
? &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, true, true>
: &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, true, false>)
: (launch_params.return_softmax
? &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, false, true>
: &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, false, false>);
if( smem_size >= 48 * 1024 ) {
FMHA_CHECK_CUDA(cudaFuncSetAttribute(
kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));
}
kernel<<<grid, Kernel_traits::THREADS, smem_size, launch_params.stream>>>(
launch_params.params);
}));
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Return_softmax>
__global__ void fmha_fwd_loop_kernel(FMHA_fprop_params params) {
fmha::device_1xN_loop<Kernel_traits, Is_dropout, Is_causal, Return_softmax>(params);
}
device_1xN_loop
// csrc/flash_attn/src/fmha_fprop_kernel_1xN.h
#include "fmha_kernel.h"
#include <fmha/kernel_traits.h>
#include <fmha/gemm.h>
#include <fmha/utils.h>
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Return_softmax, typename Params>
inline __device__ void device_1xN_loop(const Params ¶ms) {
// The block index for the batch.
const int bidb = blockIdx.x;
// The block index for the head.
const int bidh = blockIdx.y;
// The thread index.
const int tidx = threadIdx.x;
fmha::device_1xN_<Kernel_traits, Is_dropout, Is_causal, Return_softmax, true, true>(params, bidb, bidh, STEPS, ph, 0);
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Return_softmax, bool Is_first, bool Is_last, typename Params, typename Prng>
inline __device__ void device_1xN_(const Params ¶ms, const int bidb, const int bidh, int steps, Prng &ph, const int loop_step_idx) {
...
}
Dependencies
csrc/flash_attn/src/fmha
|-- gemm.h
|-- gmem_tile.h
|-- kernel_traits.h
|-- mask.h
|-- smem_tile.h
|-- softmax.h
`-- utils.h
Long sequences
WHY 原 flashattention 算法的并行依赖 bs * num_heads,A100 有 108 SMs,当 bs * num_heads > 80 时并行度利用率较高,但在长序列场景下,bs * num_heads 通常较小,无法充分利用 GPU 并行度。
HOW 前向:使用多个 thread blocks 并行处理同一个 attention head,head 按照 row 切分,可以无依赖并行 反向:多个 thread blocks 并行处理,head 按照 column 切分,thread 间需要聚合 query gradient。(如果按 row 切则需要聚合 key 和 value 的 gradient)
References
LoRA
LoRA: Low-Rank Adaptation of Large Language Models
References
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.T @ self.lora_B.T) * self.scaling
models
LLM
Model
LLM
| Affiliation | Model | Github | Size | Train | Infer | More |
|---|---|---|---|---|---|---|
| META | LLaMa | 7B/13B/33B/65B | hf | github | ||
| Databrics | Dolly | Dolly | 12B | v | ||
| LAION.ai | ||||||
| Stability.ai | ||||||
| Eleuther.AI | ||||||
| BigScience | BLOOM | 176B |
Variation
| Affiliation | Model | Size | Base |
|---|---|---|---|
| Baize | 7B |
-
LLaMA arXiv
-
OPT https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
-
Bloom arxiv
-
Bloom huggingface
Tech
Megatron-DeepSpeed
-
https://github.com/NVIDIA/Megatron-LM
-
https://github.com/microsoft/DeepSpeed
-
https://github.com/microsoft/Megatron-DeepSpeed
-
https://github.com/bigscience-workshop/Megatron-DeepSpeed)
-
HF LLaMA modeling_llama
-
Stanford Alpaca stanford_alpaca
-
Transformer Reinforcement Learning X trlx
-
3D parallelism
DeepSpeed
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
- ZeRO sharding
- pipeline parallelism
DeepSpedd support
- Optimizer state partitioning (ZeRO stage 1)
- Gradient partitioning (ZeRO stage 2)
- Parameter partitioning (ZeRO stage 3)
- Custom mixed precision training handling
- A range of fast CUDA-extension-based optimizers
- ZeRO-Offload to CPU and Disk/NVMe
Megatron-LM
Megatron-LM is a large, powerful transformer model framework developed by the Applied Deep Learning Research team at NVIDIA.
- Tensor Parallelism
- main_grad
Workflow
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat
https://github.com/EleutherAI/gpt-neox
https://github.com/CarperAI/trlx/blob/main/examples/summarize_rlhf/reward_model/reward_model.py
Question
- How loss was caculated in SFT ? What's the difference between Pretraining ?
falcon
Architecture
- Positionnal embeddings: rotary (Su et al., 2021);
- Attention: multiquery (Shazeer et al., 2019) and FlashAttention (Dao et al., 2022);
- Decoder-block: parallel attention/MLP with a single layer norm.
Spec
- AWS SageMaker, on 64 A100 40GB GPUs in P4d instances.
- 40B parameters
- 1,000B tokens of RefinedWeb
- Falcon-40B-Instruct = Falcon-40B + 150M tokens (Baize + 5% RefinedWeb).
llama
llama-agentic-system
https://github.com/meta-llama/llama-agentic-system
https://github.com/google/mesop
import time
import mesop as me
import mesop.labs as mel
@me.page(path="/text_to_text", title="Text I/O Example")
def app():
mel.text_to_text(
upper_case_stream,
title="Text I/O Example",
)
def upper_case_stream(s: str):
yield s.capitalize()
time.sleep(0.5)
yield "Done"
peft
PEFT (Parameter Efficient Fine-Tuning) is a method for adapting large pre-trained language models (like BERT, GPT-3) to new tasks without needing to fine-tune all of the model's parameters. This allows the model to be adapted using less compute and memory. The main alternatives to PEFT are:
- Full fine-tuning: Fine-tuning all of the model's parameters on the new task data. This requires a lot of compute and memory but often achieves the best performance.
- Feature extraction: Using the pretrained model as a feature extractor and training a small classifier on top. This requires little compute but often achieves worse performance than fine-tuning.
- Prompt tuning: Providing the model with prompts that incorporate the task and dataset, and then using the model's predictions on those prompts for the task. This requires no additional training but often achieves worse performance than fine-tuning. PEFT aims to get the best of both worlds - achieve performance comparable to full fine-tuning while requiring much less compute. It does this by only fine-tuning a small subset of the model's parameters on the new task data. The main PEFT methods are:
- LoRA: Fine-tuning only the model's layer outputs and attention weights.
- Prefix tuning: Fine-tuning only the first few layers of the encoder.
- P-tuning: Fine-tuning all layers but with a small learning rate for most layers.
- Prompt tuning: Providing prompts but also fine-tuning some parameters. So in summary, PEFT requires more compute than feature extraction or prompt tuning but much less than full fine-tuning, while aiming to achieve comparable performance to full fine-tuning.
Transformer
BERT
BertModel
class BertModel(BertPreTrainedModel):
def __init__(self, config, add_pooling_layer=True):
self.config = config
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config) if add_pooling_layer else None
def forward(self, ...):
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
BertEmbeddings
# src/transformers/models/bert/modeling_bert.py
class BertEmbeddings(nn.Module):
def __init__(self, config):
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, ...):
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
position_embeddings = self.position_embeddings(position_ids) # absolute
embeddings = inputs_embeds + token_type_embeddings + position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
BertEncoder
class BertEncoder(nn.Module):
def __init__(self, config):
self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
def forward(self, ...):
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
>>> model.config
BertConfig {
"_name_or_path": "bert-base-uncased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.22.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
>>> model.eval()
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
...
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
T5
from transformers import T5Tokenizer, T5Model
model = T5Model.from_pretrained("t5-small")
>>> model.config
T5Config {
"_name_or_path": "t5-small",
"architectures": [
"T5WithLMHeadModel"
],
"d_ff": 2048,
"d_kv": 64,
"d_model": 512,
"decoder_start_token_id": 0,
"dense_act_fn": "relu",
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"is_gated_act": false,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"n_positions": 512,
"num_decoder_layers": 6,
"num_heads": 8,
"num_layers": 6,
"output_past": true,
"pad_token_id": 0,
"relative_attention_max_distance": 128,
"relative_attention_num_buckets": 32,
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
"transformers_version": "4.22.2",
"use_cache": true,
"vocab_size": 32128
}
>>> model.eval()
T5Model(
(shared): Embedding(32128, 512)
(encoder): T5Stack(
(embed_tokens): Embedding(32128, 512)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
(relative_attention_bias): Embedding(32, 8)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
...
(5): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(decoder): T5Stack(
(embed_tokens): Embedding(32128, 512)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
(relative_attention_bias): Embedding(32, 8)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
...
(5): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> model.config
# same as T5Model
>>> model.eval()
T5ForConditionalGeneration(
...
(lm_head): Linear(in_features=512, out_features=32128, bias=False)
)
GPT
model = OpenAIGPTModel.from_pretrained("openai-gpt")
>>> model.config
OpenAIGPTConfig {
"_name_or_path": "openai-gpt",
"afn": "gelu",
"architectures": [
"OpenAIGPTLMHeadModel"
],
"attn_pdrop": 0.1,
"embd_pdrop": 0.1,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "openai-gpt",
"n_ctx": 512,
"n_embd": 768,
"n_head": 12,
"n_layer": 12,
"n_positions": 512,
"n_special": 0,
"predict_special_tokens": true,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"transformers_version": "4.22.2",
"vocab_size": 40478
}
OpenAIGPTModel(
(tokens_embed): Embedding(40478, 768)
(positions_embed): Embedding(512, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0): Block(
(attn): Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
...
(11): Block(
(attn): Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
FasterTransformer
NVIDIA Transformer 推理前向优化方案。
References
models
python
Some interesting usage.
import json
from types import SimpleNamespace
data = '{"name": "John Smith", "hometown": {"name": "New York", "id": 123}}'
# Parse JSON into an object with attributes corresponding to dict keys.
x = json.loads(data, object_hook=lambda d: SimpleNamespace(**d))
print(x.name, x.hometown.name, x.hometown.id)
Pipe
class Pipe(object):
def __init__(self, func):
self.func = func
def __ror__(self, other):
def generator():
for obj in other:
if obj is not None:
yield self.func(obj)
return generator()
@Pipe
def even_filter(num):
return num if num % 2 == 0 else None
@Pipe
def multiply_by_three(num):
return num*3
@Pipe
def convert_to_string(num):
return 'The Number: %s' % num
@Pipe
def echo(item):
print item
return item
def force(sqs):
for item in sqs: pass
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
force(nums | even_filter | multiply_by_three | convert_to_string | echo)
IP
hostname -i
python -c "import socket; print(socket.gethostbyname(socket.getfqdn(socket.gethostname())))"
Concurrent Execution
TL;DR;
- 使用 python 作为引子/driver 启动其他独立进程,使用 exec.
- 使用 python 作为主进程管理,子进程是独立启动的进程,使用 subprocess.Popen.
- 子进程是 python 函数使用 multiprocessing。
- 把 python 函数当作线程启动时使用 threading。
https://docs.python.org/3/library/concurrency.html
1. subprocess
- 启动子进程,自定义 excutable
import subprocess
proc = subprocess.Popen(["/usr/bin/git", "commit", "-m", "Fixes a bug."])
proc.poll()
proc.wait()
proc.communicate()
proc.terminate()
proc.kill()
https://docs.python.org/3/library/subprocess.html
2. threading
- 启动线程
- 存在 GIL 问题,无法完全利用 CPU
import threading
def serve():
pass
thread = threading.Thread(target=serve, daemon=None)
thread.start()
thread.join()
https://docs.python.org/3/library/threading.html
Pros
- Lightweight - low memory footprint
- Shared memory - makes access to state from another context easier
- Allows you to easily make responsive UIs
- cPython C extension modules that properly release the GIL will run in parallel
- Great option for I/O-bound applications
Cons
- cPython - subject to the GIL
- Not interruptible/killable
- If not following a command queue/message pump model (using the Queue module), then manual use of synchronization primitives become a necessity (decisions are needed for the granularity of locking)
- Code is usually harder to understand and to get right - the potential for race conditions increases dramatically
3. multiprocessing
- 启动子进程,使用内置函数
- 使用进程,充分利用 CPU 资源
from multiprocessing
proc = multiprocessing.Process(target=serve, daemon=None)
proc.start()
proc.join()
proc.close()
https://docs.python.org/3/library/multiprocessing.html
Pros
- Separate memory space
- Code is usually straightforward
- Takes advantage of multiple CPUs & cores
- Avoids GIL limitations for cPython
- Eliminates most needs for synchronization primitives unless if you use shared memory (instead, it's more of a communication model for IPC)
- Child processes are interruptible/killable
- Python multiprocessing module includes useful abstractions with an interface much like threading.Thread
- A must with cPython for CPU-bound processing
Cons
- IPC a little more complicated with more overhead (communication model vs. shared memory/objects)
- Larger memory footprint
4. Executor
https://docs.python.org/3/library/concurrent.futures.html
- ProcessPoolExecutor 封装 multiprocessing module,提供进程池
- ThreadPoolExecutor, 线程池
API
class concurrent.futures.Executor:
submit(fn, /, *args, **kwargs)
map(func, *iterables, timeout=None, chunksize=1)
shutdown(wait=True, *, cancel_futures=False)
调用 submit 返回 concurrent.futures.Future, 使用 result(timeout=None) 获取结果。.
exec
python 转 shell 执行
os.execve('/bin/sh', 'echo', 'ok')
multiprocessing
multiprocessing — Process-based parallelism — Python 3.10.1 documentation
Difference between Pipe and Queue
-
A
Pipe()can have two endpoints -
A
Queue()can have multiple producers and consumers
A Pipe has a better performance than Queue since Queue is built on top of Pipe.
Queue
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
Pipe
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
Lock
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()s
Shared memory
Value and Array Only
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
Server process
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
remote manager
start server
from multiprocessing.managers import BaseManager
from queue import Queue
queue = Queue()
class QueueManager(BaseManager): pass
QueueManager.register('get_queue', callable=lambda:queue)
m = QueueManager(address=('', 50000), authkey=b'abracadabra')
s = m.get_server()
s.serve_forever()
use in clients
from multiprocessing.managers import BaseManager
class QueueManager(BaseManager): pass
QueueManager.register('get_queue')
m = QueueManager(address=('foo.bar.org', 50000), authkey=b'abracadabra')
m.connect()
queue = m.get_queue()
queue.put('hello')
#queue.get('hello')
decorator
Examples
def decorator(f):
print(0)
return f
@decorator
def func(*args, **kwargs):
print(2, *args, **kwargs)
return 3
# func = decorator(func)
print(1)
print(func())
应用场景
- 插件注册 Registering Plugins
- Trace
def decorator(f):
print(0)
def wrapper(*args, **kwargs):
print(2)
ret = f(*args, **kwargs)
print(4)
return ret
return wrapper
@decorator
def f(*args, **kwargs):
print(3)
return 5
# f = decorator(f)
print(1)
print(f())
应用场景
- 过滤/校验
- 重复调用
- 统计时间
- Debug
def decorator(arg):
print(arg)
def wrapper(f):
print(1)
return f
return wrapper
@decorator(0)
def f(*args, **kwargs):
print(3)
return 4
# f = decorator(arg)(f)
print(2)
print(f())
import functools
def repeat(_func=None, *, num_times=2):
def decorator_repeat(func):
@functools.wraps(func)
def wrapper_repeat(*args, **kwargs):
for _ in range(num_times):
value = func(*args, **kwargs)
return value
return wrapper_repeat
if _func is None:
return decorator_repeat
else:
return decorator_repeat(_func)
@repeat
def say_whee():
print("Whee!")
@repeat(num_times=3)
def greet(name):
print(f"Hello {name}")
say_whee()
greet("kk")
import functools
def singleton(cls):
"""Make a class a Singleton class (only one instance)"""
@functools.wraps(cls)
def wrapper_singleton(*args, **kwargs):
if not wrapper_singleton.instance:
wrapper_singleton.instance = cls(*args, **kwargs)
return wrapper_singleton.instance
wrapper_singleton.instance = None
return wrapper_singleton
@singleton
class TheOne:
pass
class Decorator:
def __init__(self, arg):
print(arg)
self.arg = arg
def __call__(self, f):
print(1, self.arg)
return f
@Decorator(0)
def func(arg):
print(3)
return arg
# func = Decorator(arg)(arg)
print(2)
print(func(4))
print(func(5))
class Decorator:
def __init__(self, f):
print(0)
self.f = f
def __call__(self, arg):
print(2, self.f)
return self.f(arg)
@Decorator
def func(arg):
print(3)
return arg
# func = Decorator(arg)(arg)
print(1)
print(func(4))
print(func(5))
Reference
golang
Golang Error
Using reference to loop iterator variable
in := []int{1, 2, 3}
var out []*int
for _, v := range in {
out = append(out, &v)
}
fmt.Println("Values:", *out[0], *out[1], *out[2])
fmt.Println("Addresses:", out[0], out[1], out[2])
Bad ordered struct
type BadOrderedPerson struct {
Veteran bool // 1 byte
Name string // 16 byte
Age int32 // 4 byte
}
type OrderedPerson struct {
Name string
Age int32
Veteran bool
}
type BadOrderedPerson struct {
Veteran bool // 1 byte
_ [7]byte // 7 byte: padding for alignment
Name string // 16 byte
Age int32 // 4 byte
_ struct{} // to prevent unkeyed literals
// zero sized values, like struct{} and [0]byte occurring at
// the end of a structure are assumed to have a size of one byte.
// so padding also will be addedd here as well.
}
type OrderedPerson struct {
Name string
Age int32
Veteran bool
_ struct{}
}
cplusplus
enable_shared_from_this
Bad case:
#include <iostream>
#include <memory>
class KK {
public:
std::shared_ptr<KK> get_shared_ptr() {
return std::shared_ptr<KK>(this);
}
};
int main() {
std::shared_ptr<KK> k1(new KK());
std::shared_ptr<KK> k2 = k1->get_shared_ptr();
std::cout << k1.use_count() << std::endl;
std::cout << k2.use_count() << std::endl;
}
Good case:
#include <iostream>
#include <memory>
//struct KK : std::enable_shared_from_this<KK> {
class KK : public std::enable_shared_from_this<KK> {
public:
std::shared_ptr<KK> get_shared_ptr() {
return shared_from_this();
}
};
int main() {
std::shared_ptr<KK> k1(new KK());
std::shared_ptr<KK> k2 = k1->get_shared_ptr();
std::cout << k1.use_count() << std::endl;
std::cout << k2.use_count() << std::endl;
}
Note:
public should be added before class since
struct Test : enable_shared_from_this<Test>
derives publicly from enable_shared_from_this;
while
class Test : enable_shared_from_this<Test>
derives privately from enable_shared_from_this;
mathematics
Topics
-
Pure Mathematics
- Algebra
- Analysis
- Geometry
- Topology
-
Applied Mathematics
- Modeling
- Learning
- Algorithms
-
Physics
- Classical mechanics
- Statistical mechanics
- Electromagnetism
- Quantum mechanics
Definition
Scalar ,
Vector
Linearity ,
Estimator
Bias
unbiased if
Mean Squared Error
minimizing the mean squared error = maximum likelihood estimator
Moore-Penrose pseudoinverse
Probability
represent the probability of and hanppend.
represent the probability of while already known been happend.
Conditional Probability
If independent with , then
Bayes's Rule
Experience
Variance
Covariance
Normal Distribution
If , then , .
Logistic sigmoid
Softplus function
Softmax
norm
XOR
Linear model cannot perform XOR operation
General Problem
For a data-set with samples
Linear Case
Module
Likelihood function
Likelihood is the probability that a particular outcome is observed when the true value of the parameter is ,
Unlike probabilities, likelihood function do not have to integrate (or sum) to 1.
Quadratic Problem
is invertable,
summary
- maximum likelihood estimation
- least square regression
- minimum cross-entropy between the distributions
- minimum the KL divergence
prevent overfitting
- maximum a posteriori estimation
- regularized least square
cross-entropy negative log-likelihood of a Bernoulli or softmax distribution
PCA
- maximize variance of data after projection
maximize variance -- lagrangian multiplier --> eigenvector of covariance matrix
Theorem (Bochner’s theorem)
A continuous function of the form 𝑘(𝑥,𝑦)=𝑘(𝑥−𝑦) is positive definite if and only if 𝑘(𝛿) is the Fourier transform of a non-negative measure.
Random Fourier features — Random walks
Entropy
Definition
For a discrete probability distribution on the finite set with , the entropy of is defined as
For a continuous probability density function on an interval , the entropy of is defined as
Theorem
For a probability density function on a finite set , then
with equality iff. is uniform, i.e. .
Uniform probability yields maximum uncertainty and therefore maximum entropy.
Theorem
For a continuous probability density function on with variance , then
with equality iff. if Gaussian with variance , i.e. for some we have
Theorem
For a continuous probability density function on with mean , then
with equality iff. is exponential with mean , i.e.
Cross entropy
The cross entropy of the distribution relative to a distribution over a given set is defined as follows:
Kullback-Leibler divergence
The Kullback-Leibler divergence (relative entropy) was introduced as the directed divergence between two distributions
The Kullback-Leibler divergence is then interpreted as the average difference of the number of bits required for encoding samples of using a code optimized for rather than one optimized for .
Jensen-Shannon divergence
where
Mutual Information
Let be a pair of random variables with values over the space . If their joint distribution is and the marginal distributions are and , the mutual information is defined as
where is the Kullback–Leibler divergence.
PMFs for discrete distributions
The mutual information of two jointly discrete random variables and is calculated as a double sum:
where is the joint probability mass function of and , and and are the marginal probability mass functions of and respectively.
PDFs for continuous distributions
In the case of jointly continuous random variables, the double sum is replaced by a double integral:
where is now the joint probability density function of and , and and are the marginal probability density functions of and respectively.
Mutual information and Kullback–Leibler divergence
Mutual information is the Kullback–Leibler divergence from the product of the marginal distributions
Newton's Method
Given a twice differentiable function , solve the optimization problem
Consider the second-order Taylor expansion of around
Setting the derivative to zero,
the minimum is achieved for
then
Regression
Linear Regression
Objective function
Ordinary least square Lagrangian function
Let leads to
With respect to different constraints,
- for lasso,
- for ridge.
Ridge Regression : L1 Regularization
Least absolute shrinkage and selection operator
- When , no parameters are eliminated. The estimate is equal to the one found with linear regression.
- As increases, more and more coefficients are set to zero and eliminated (theoretically, when , all coefficients are eliminated).
- As increases, bias increases.
- As decreases, variance increases.
Lasso Regression : L2 Regularization
Let leads to
Elastic net Regularization
Logistic Regression
For ,
Logistic function is inverse logit, sigmoid function defined as follows, for ,
Suppose linear with , i.e.
then
Conjugate Descent
Definition
Let be a symmetric matrix. are Q-orthogonal w.r.t. if
Proposition
Let be positive definite. If are Q-orthogonal, then they are linear independent.
Proof
If , then controversy with postive definite.
Proposition
Let vectors Q-orthogonal, be arbitrary starting point.
Assume
then is the solution of .
Matrix is positive definite.
Let vectors Q-orthogonal, which is linear independent, then there exist ,
Proposition
Let arbitrary,
Gradient Descent
Multi-variable function , defined differentiable in a neighborhood of a point , for small enough,
leads to .
If convex and Lipschitz, converge to a local mimimum.
Optimization : Momentum
Let ,
The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.
Optimization : Nesterov
Version with correction,
This anticipatory update prevents us from going too fast and results in increased responsiveness, which has significantly increased the performance of RNNs on a number of tasks.
Adagrad
It adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. For this reason, it is well-suited for dealing with sparse data.
Application : learned to recognize cats in Youtube videos; GloVe word embeddings.
Adadelta
Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size w.
RMSprop
RMSprop and Adadelta have both been developed independently around the same time stemming from the need to resolve Adagrad’s radically diminishing learning rates. RMSprop in fact is identical to the first update vector of Adadelta.
Adam
Adaptive Moment Estimation (Adam) is another method that computes adaptive learning rates for each parameter. In addition to storing an exponentially decaying average of past squared gradients like Adadelta and RMSprop, Adam also keeps an exponentially decaying average of past gradients , similar to momentum.
Principal Component Analysis
In order to maximize variance, the first weight vector thus has to satisfy
Since has been defined to be a unit vector, it equivalently also satisfies
The quantity to be maximised can be recognised as a Rayleigh quotient. A standard result for a positive semidefinite matrix such as is that the quotient's maximum possible value is the largest eigenvalue of the matrix, which occurs when w is the corresponding eigenvector.
Let be origin samples, projection vector satisfies
Denote the variance of origin samples, variance of projected samples,
Lagrangian multiplier form,
leads to
the variance is maximized with is the eigenvector of , the maximum value is the related eigenvalue .
PCA is either done by
- singular value decomposition of a design matrix;
- eigenvalue decomposition on the covariance matrix.
Eigenvalue Decomposition
A (non-zero) vector is an eigenvector of a square matrix if it satisfies the linear equation
where termed the eigenvalue corresponding to .
Since ,
Diagonalisable matrice can be factorized as
where and is the -th column of .
Singualar Value Decomposition
The singular value decomposition (svd) of matrix
where , and is diagonal with positive number.
The right singular vectors of the eigenvectors of , while the singular values of are equal to the square-root of the eigenvalues of .
Support Vector Machine
Suppose dataset related to label , find and bias such that
which leads to
The distance between optimal hyperplanes is , so maximizing the margin equals to minimizing .
Primary problem : min ,
leads to
and ,
leads to
Dual problem : max ,
s.t. ,
Only support vectors have nonzero coefficients .
Approaches : sub-gradient descent and coordinate descent.
differentiation
傅立叶分析 Fourier Analysis
基础知识
掌握傅立叶分析需要了解以下概念:
- 向量空间 (vector space)
- 线性 (linearity)
- 向量基 (base/basis)
内积
离散向量 的内积定义为
连续函数 的内积定义为
注意理解离散求和符号 和连续求和符号 在概念上的一致性。
正交基
如果 是向量空间 的一组正交基,那么对于所有向量 ,
一般将 部分叫做向量的坐标。
注意同一向量空间可能有不同的基,所以对应不同的坐标。
在二维平面 中,经典基向量为 和 ,他们组成的变换矩阵为单位矩阵 (identity matrix)
假设我们选取 和 作为新的一组基, 因为 , 这是一组正交基,他们组成的变换矩阵为
这里我们并没有对向量进行归一化处理,所以在变换矩阵或逆变换矩阵里一般会有一个系数, 这也是在傅立叶变换的定义中有不同系数版本的原因。
任意二维平面上的向量 都可以通过基 的线性组合表示, 向量在该坐标系中的坐标可以通过变换矩阵得到
可以看出, 变换后的坐标为 ,因为 , 变换后的坐标为 ,因为 .
从坐标系 变换回 的逆变换矩阵也即矩阵 的逆矩阵为
总结而言,矩阵 可以进行坐标变换,同时其逆矩阵 可以实现坐标逆变换,
离散傅立叶变换
现实场景下的信号处理一般针对离散数据而言, 长度为 的离散数据可以当作 维向量空间中的向量, 假定它在经典基向量下的坐标为 .
这里我们考虑一组新的基向量 , 注意 是一个 维向量。 假定这是一组正交基,那么记
则 表示向量 在变换后的向量。 注意这里的 是 的矩阵。
假设矩阵 是可逆的,它的逆矩阵记做 ,那么我们有
对于所有的向量 ,
这样我们可以将 叫做 的 ~变换,而 叫做 的 ~逆变换。
当采用如下的基向量时,我们得到了离散条件下的 傅立叶变换 和 傅立叶逆变换,
这里 为欧拉 Euler 常数,,所以 为整数时 ,当 为时可以理解为 1 的 次方根的第 个根。
的取值为从 到 共 个向量,注意到
也即这是一组正交向量,证明可以参考内积的定义进行展开计算。
基向量 的选取非常巧妙,也是傅立叶变换的精髓,可以这样理解, 对于 维空间,选取 1 的 个 次方根作为一个基向量,然后通过分别取 到 次方构建出一组正交基。
记 , 基向量 , 傅立叶变换的矩阵为
傅立叶逆变换的矩阵为
由此可见,傅立叶变换的矩阵或者说基向量的精髓之处在于它的逆矩阵可以如此轻而易举地计算或者说构造出来。
至此,对于任意长度为 的向量 ,如果它表示的是时域的信号, 那么可以通过 计算它的傅立叶变换 ,得到频域上的信号表示, 在频域上对信号进行适当处理之后再通过 重新得到时域上被修改过的信号。 频域上的修改会对时域上的信号有怎样的影响已经超出了本文的范畴,推荐信号处理相关书籍。
通过如下的计算可以看出在计算傅立叶变换时可通过分治的思想将 计算复杂度从 降到 ,这也快速傅立叶变换 (FFT) 在工程上如此成功的理论基础。
至此我们从向量空间的角度理解了离散傅立叶变换,后续的文章我们继续从离散情况出发推广字连续有界 (傅立叶级数 Fourier Series)和连续(傅立叶变换 Fourier Transform)的情况。
kmeans
Let
find
such that
where
cos defines
Equivalent form
under condition
where
For , let
then
replace with above expression
then
For and ,
preliminary
From Fourier to Wavelets
- Descrete Fourier Transform
preliminary
From Fourier to Wavelets
- Descrete Fourier Transform
Preliminary
Euler's formula
The Euler's formula refers to
The proof of this formula can be introduced by investigating the function with the facts that
which conclude that .
Beware of the following facts,
- is periode function,
- .
they will be the key to step into the Fourier kingdom.
Inner product
For , the inner product defined as and for , the inner product defined as
For , the inner product defined as and for , the inner product defined as
Orthogonal Basis
Discrete case, the space
If is an orthogonal basis of space , which means where
Note that and .
then ,
It is an orthonormal bases if .
Suppose , the above formula can be rewritten in matrix form, that is
The construction of orthogonal bases in space equals to find square matrix such that .
The following shows the intuition to extend , i.e. orthogonal bases ,
the space
For , extending to , , respect to where , Then
the space
For , extending to , which is ,
where ,
Haar Wavelets
Definition.
The Haar scaling function is defined as
The Haar wavelet is the function
Fourier Analysis
Discrete Fourier Transform
In the space , fourier provide an orthogonal basis
with the -th root of .
This proposition is valable thanks to
and .
As a consequence,
The discrete fourier transform can be represented as follows,
then the inverse fourier transform would be
Equivalently, the fourier transform element
and the inverse fourier transform element recovered by
Fast Fourier Transform (FFT)
Note that , the elements in matrix above are massively in common, elements disinct, precisely.
With the orthogonality, rewrite the formula as follows,
The above result shows that the coefficients of fourier transform can be calculated recursively using the method of divide and conquer which reduce the calculation complexity from to .
Denote the transform matrix as , then
with is a permutation matrix and
Fourier series
Consider the space , the functions , form a orthogonal basis since
Complex form
For function ,
where
From complex to real
Since , suppose , then
if , and which means , then
Real value, conventional form
For -periodic function ,
where
Fourier Transform
From fourier series to fourier transform
Since
which leads,
Denote the Fourier transform as follows,
then the Inverse Fourier transform
this is non-unitary, angular frequency form.
Fourier transform (unitary, oridnay frequency form)
For function , i.e. ,
with , i.e. .
Inverse Fourier transform
More
If function is frequency band-limited, i.e. Then
where
Further
and
Therefore,
Derivatives.
Convolution
Definition
Parseval's theorem
Fourier Transform of Normal Distribution
Uncertainty Principle
For , the distribution of propability density of and are
Multiresolution
Definition.
Definition. Multiresolution Analysis
A multiresolution analysis for consists of
- a sequence of closed subspaces of , and
- a scaling function ,
such that the following conditions holds,
- constitute an orthonomal basis of .
- ,
- ,
- ,
- ,
The scaling function in multiresolution analysis determines the spaces uniquely.
Definition. Wavelet space
For any , let denote the orthogonal complement of with respect to , i.e.
For each , the closed subspaces,
Any wavelet generate a direct sum decomposition of .
Basis for ,
Basis for ,
Decomposition formulas
Denote and ,
Reconstruction formulas
Proposition.
The function generate a multiresolution analysis. Let and is an orthonormal basis for , then
- the functions form an orthonormal basis for ,
- is wavelet, i.e., the functions form an orthonormal basis for ,
- the functions form an orthonormal basis for .
Proposition.
The function generate a multiresolution analysis. Then there exist a 1-periodic function such that
where
Let
define the function
then
- the functions form an orthonormal basis for ,
- is wavelet, i.e., the functions form an orthonormal basis for ,
Proposition
If
then
Compactly supported wavelet means that only few coeficients of are non-zeros.
Theorem
Let , is an orthonormal system iff.
kubernetes
Doc
Design
GitHub - kubernetes/design-proposals-archive: Archive of Kubernetes Design Proposals
socket
dockerd -H unix:///var/run/docker.sock -H tcp://192.168.59.106 -H tcp://10.10.10.2
curl -XPOST --unix-socket /var/run/docker.sock -d '{"Image":"nginx"}' -H 'Content-Type: application/json' http://localhost/containers/create
{"Id":"1b46f62945c70c0f21e00cb72db968201352e6536072278e23674419c4d763ee","Warnings":[]}
curl -XPOST --unix-socket /var/run/docker.sock http://localhost/containers/1b46f62945c70c0f21e00cb72db968201352e6536072278e23674419c4d763ee/start
curl --unix-socket /var/run/docker.sock http://localhost/events
Linux Network
Linux namespaces
-
Cgroups
-
IPC
-
Network
-
Mount
-
User
-
PID
-
UTS(Unix Time Sharing), NIS(network information service)
Reference
Concepts
Overview
- Traditional deployment
- Virtualized deployment
- Container deployment
Objects
Kubernetes objects
- persistent entities
- spec + status
Management
- imperative commands: create/delete xx
- imperative object configuration: create/delete -f
- declarative object configuration: apply -f
Object Names and IDs
- DNS Subdomain: 253, alphanumeric + '-' + '.'
- RFC 1123: 63, alphanumeric + '-'
- RFC 1035: 63, alphanumeric + '-'
RFC 1123 labels are allowed to start with a digit
Labels and Selectors
The label selector is the core grouping primitive in Kubernetes.
Namespaces
<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.66666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord">−</span><span class="mord mathnormal">n</span><span class="mord mathnormal">a</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal" style="margin-right:0.02778em;">O</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal" style="margin-right:0.13889em;">T</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.02778em;">O</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.07153em;">K</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">m</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">m</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">a</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">a</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">d</span><span class="mord mathnormal">m</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.13889em;">W</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">d</span><span class="mord mathnormal">m</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.13889em;">W</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal">m</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">d</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.16666666666666666em;"></span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">d</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal">x</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal">m</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">T</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">s</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">A</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">s</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">A</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">n</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">q</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">n</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">q</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord">.</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">b</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord">3</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">F</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord">.</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">b</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord">3</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">L</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord">.</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05017em;">B</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord">.</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">A</span><span class="mord mathnormal">t</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord">‘</span><span class="mord">‘</span><span class="mord">‘</span><span class="mord">‘</span><span class="mord">‘</span><span class="mord">‘</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">h</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">i</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.66666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.8888799999999999em;vertical-align:-0.19444em;"></span><span class="mord">−</span><span class="mord mathnormal">n</span><span class="mord mathnormal">a</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right:0.2777777777777778em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal" style="margin-right:0.02778em;">O</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal" style="margin-right:0.13889em;">T</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.02778em;">O</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal" style="margin-right:0.07153em;">K</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal">b</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05017em;">B</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">m</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">m</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.10903em;">M</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal">L</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">a</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.22222em;">V</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">u</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">i</span><span class="mord mathnormal">m</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.13889em;">T</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">q</span><span class="mord mathnormal">u</span><span class="mord mathnormal">o</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">q</span><span class="mord mathnormal">u</span><span class="mord mathnormal">o</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">Q</span><span class="mord mathnormal">u</span><span class="mord mathnormal">o</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">A</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal">a</span><span class="mord mathnormal">e</span><span class="mord mathnormal">m</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">m</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal">p</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">p</span><span class="mord mathnormal">s</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">u</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">o</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">s</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">s</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal">L</span><span class="mord mathnormal">o</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">u</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">A</span><span class="mord mathnormal">c</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">s</span><span class="mord mathnormal">h</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">2</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.08125em;">H</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">A</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">o</span><span class="mord mathnormal">b</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.09618em;">J</span><span class="mord mathnormal">o</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.05724em;">j</span><span class="mord mathnormal">o</span><span class="mord mathnormal">b</span><span class="mord mathnormal">s</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">c</span><span class="mord mathnormal">h</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.09618em;">J</span><span class="mord mathnormal">o</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal">L</span><span class="mord mathnormal">e</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">c</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">e</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">n</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10903em;">N</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">p</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">b</span><span class="mord mathnormal">u</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mord mathnormal">d</span><span class="mord mathnormal">b</span><span class="mord mathnormal">p</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">i</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.13889em;">P</span><span class="mord mathnormal">o</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.02778em;">D</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">p</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.05017em;">B</span><span class="mord mathnormal">u</span><span class="mord mathnormal">d</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord">.</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.05017em;">B</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">i</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">b</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord">.</span><span class="mord mathnormal">a</span><span class="mord mathnormal">u</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.04398em;">z</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">s</span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal">c</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">e</span><span class="mord mathnormal">s</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord">8</span><span class="mord mathnormal">s</span><span class="mord">.</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord">/</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord">1</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">u</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.05764em;">S</span><span class="mord mathnormal">t</span><span class="mord mathnormal">o</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.03588em;">g</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.07153em;">C</span><span class="mord mathnormal">a</span><span class="mord mathnormal">p</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03588em;">y</span><span class="mord">‘</span><span class="mord">‘</span><span class="mord">‘</span></span></span></span>scheduler
Summary and Examples
比较简单的 demo,体现基本框架
稍微复杂一些,完整实现,extender 部署
GitHub - everpeace/k8s-scheduler-extender-example: An example of kubernetes scheduler extender
aliyun gpu,部署替换 kube-scheduler
基于 kubernetes framework
GitHub - everpeace/kube-throttler: throttling your pods in kubernetes cluster.
Reference
Kubernetes Operator 开发
Kubernetes 是 Google 开源贡献给云原生计算基金会 (CNCF),用于自动部署、拓展和管理容器化程序的开源系统。Kubernetes 作为云原生的基础设施,已经成为容器化应用编排的事实标准,依赖其优秀的顶层设计和强大的可拓展能力,为整个生态的繁荣奠定了基础。
Kubernetes 内置了一系列的工作负载资源可以直接使用以完成基于容器化运行的特定任务,例如一个数据处理任务或者一个单节点的训练任务可以使用定义 Job 来实现。当内置的工作负载不能满足我们的业务场景需求时,可以通过拓展 Kubernetes 的方式添加功能,例如直接使用 Kubernetes 内置资源无法准确定义一个分布式机器学习任务所需要的角色分配和批量任务等功能。
Operator 是开发 Kubernetes 应用拓展的原生方式,它通过添加自定义资源(CRD)拓展出新的 API,并且依赖 Kubernetes API Server 面向用户提供服务,即用户通过原有服务即可操作新添加的资源对象。为了响应该资源对象的变动,维护资源对象的生命周期,开发者需要定义资源的更新逻辑,即需要开发部署控制器 (Controller) .
如图所示,Operator 包括自定义资源类型(CRD)和控制器(Controller)两个部分,CRD 使得资源定义和 API 得以拓展,Controller 负责对应资源的变化的逻辑处理。
Operator 的应用场景非常广泛,而相比于普通部署于 Kubernetes 集群的应用相比,Operator 的设计模式主要针对能够对资源类进行抽象,通过管理实例化资源的方式完成特定任务。更多应用场景的说明可以在这里 找到。
本文分为三个部分:首先通过 Kubernetes 资源定义和对 Controller 逻辑进行解析介绍 Operator 的工作原理,最后介绍在实践中开发 Operator 的方法。
Kubernetes 资源定义
Kubernetes 的资源管理和调度以 Pod 为单位,一个 Pod 中可以运行一个或多个容器 (Container) ,容器中运行特定的应用程序。Kubernetes 中的资源定义都提供了对外接口,即用户可以通过 Kubernetes API 直接操作 Pod,例如可以使用以下配置信息来描述/定义一个 Pod 实例:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
配置信息相当于实例化了一个 Pod 对象,表示一个名称为 nginx 的 Pod,运行镜像为 nginx:1.14.2 , 而 Pod 类的定义可以在这里找到,
type Pod struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec PodSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status PodStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
这里的定义主要有四块内容,其中 apiVersion 和 kind 来自于 TypeMeta 指定类型的名称和版本信息,来自 ObjectMeta 的 metadata 主要指定具体的对象信息,最常见的包含资源名称 name 和资源所在的命名空间 namespace。在 Kubernetes 中,通过类型、命名空间和名称的组合(kind-namespace-name)即可唯一标识一个具体的资源对象。TypeMeta和ObjectMeta信息属于 Kubernetes API 体系的基础定义,类似于继承中的父类定义。而 spec 和 status 会根据资源类型的不同有不同的定义,如这里 Pod 的 spec 和 status 分别由 PodSpec 和 PodStatus 具体定义。一般地,spec表示资源对象的静态配置信息和期望的状态,即该资源通过 spec即可描述它应有的完整工作流程。相对地,status表示该资源对象当前所处的状态信息,在运行时会随时间被更新的部分。
通过调用 Kubernetes 对应的服务接口我们可以在集群中对对象进行 CRUD 操作即创建、查询、更新、删除对应的对象。
定义资源的格式可以有多种,如 yaml,json 等等,取决于调用方法所支持的数据格式。调用 Kubernetes 接口的方式也有多种,如 http(s) 访问、kubectl 客户端访问、使用 SDK 开发 client 等, 本文不对此做详细讨论。
基于 Pod 拓展的资源叫做工作负载资源,Kubernetes 内置了多种工作负载资源。
-
Job 提供单次任务资源定义,Cronjob 提供时间规划运行任务定义;
-
StatefulSet 提供有状态负载集合的定义;
-
Deployment 和 ReplicaSet 提供无状态负载集合的定义;
-
DaemonSet 提供节点绑定的负载定义;
工作负载资源定义都有类似上述 Pod 定义四个部分的结构,基于 Kubernetes 声明式的设计,期望状态在 spec 中被描述, status 中体现当前资源所处的实际状态,那么谁负责更新资源当前所处的状态和怎么做才能满足期望状态呢?这就是接下来讲的组件 controller。
Controller 原理和实现
通过上面资源定义的介绍我们知道 Controller 是进行逻辑处理的部分,它的作用是更新资源状态同时尽可能采取行动使得资源满足期望状态。要理解 Controller 的工作原理需要首先理解 Kubernetes client-go 中的 informer 设计。首先,informer 和特定的资源绑定,如图所示,Informer 通过客户端实现对特定资源的 List 和 Watch 操作,即从服务端拉取所需要的资源信息,获取到的信息一方面存入自带索引的本地缓存 cache indexer,另一方面变动信息生成对应事件 event,预先注册的对应资源变动的 handler 相应逻辑会被触发执行。这里 event 信息中只有索引信息,在处理模块中需要使用资源完整信息时再通过 indexer 进行查询。
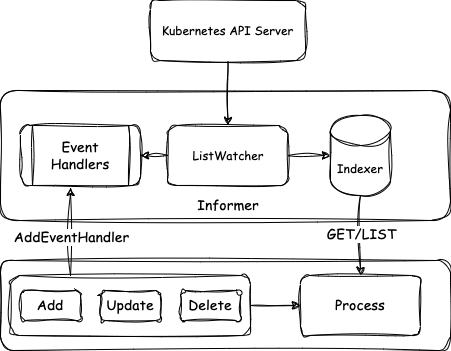
从以上设计中可以看出,本地缓存所需资源信息,极大减少了和 API Server 交互的压力,而且在具体实现中,采用了 shared informer 的机制,即同一资源被多次使用时可以共享 informer 再次降低了负载压力。
我们以 Job Controller 为例(完整源码可以在这里找到),来看 Controller 如何利用 informer 完成控制逻辑的。Controller 定义主要包含以下部分(已省略部分内容),在 Job Controller 中关注两种资源 Job 和 Pod。
type Controller struct {
// 用于连接集群的客户端
kubeClient clientset.Interface
// 用于获取 job 信息
jobLister batchv1listers.JobLister
// 用于获取 pod 信息
podStore corelisters.PodLister
// 需要处理的消息任务队列
queue workqueue.RateLimitingInterface
}
当 Controller 被初始化时,两种资源 Job 和 Pod对应的 informer 已经提前被创建作为参数传入,这里主要将 Controller 中对应的函数和资源变动事件通过 AddEventHandler 函数进行注册绑定,这样对应资源变动时,函数将会被执行,可以看到当 job 被创建和删除时,只是简单将对象放入处理队列,而 job 更新和 pod 变动都有对应函数处理,pod 的变动触发函数主要处理一致性问题和触发 job 更新消息,下面我们主要关注 job 更新消息的处理。
func NewController(podInformer coreinformers.PodInformer, jobInformer batchinformers.JobInformer, kubeClient clientset.Interface) *Controller {
// 初始化,创建消息队列
jm := &Controller{
kubeClient: kubeClient,
queue: workqueue.NewNamedRateLimitingQueue(...),
}
// 向 job informer 注册处理 job 资源变更消息的 handler 函数
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.enqueueController(obj, true)
},
UpdateFunc: jm.updateJob,
DeleteFunc: func(obj interface{}) {
jm.enqueueController(obj, true)
},
})
jm.jobLister = jobInformer.Lister()
// 向 pod informer 注册处理 pod 资源变更消息的 handler 函数
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jm.addPod,
UpdateFunc: jm.updatePod,
DeleteFunc: jm.deletePod,
})
jm.podStore = podInformer.Lister()
return jm
}
当 Controller 运行时,可以同时运行多个 worker 并发处理任务
func (jm *Controller) Run(workers int, stopCh <-chan struct{}) {
...
for i := 0; i < workers; i++ {
go wait.Until(jm.worker, time.Second, stopCh)
}
...
}
每个 worker 不断地从消息队列中取出需要处理即有变更发生的资源,执行同步函数
func (jm *Controller) worker() {
for jm.processNextWorkItem() {
}
}
func (jm *Controller) processNextWorkItem() bool {
key, quit := jm.queue.Get()
...
// syncHandler 即 jm.syncJob
forget, err := jm.syncHandler(key.(string))
...
}
同步 job 的具体流程如下,先通过消息中的索引信息获取对象,这里再次注意获取资源三要素:资源类型、命名空间和名字,job 是用来管理 pod 的(几乎所有的工作负载都是这样设计),底层资源还是 pod,所以这里还要获取与 job 关联的 pods。获得资源的状态信息后,经过一系列判断以对 job 进行不同的操作,比如失败且满足条件时会执行删除关联 pod 操作,有的还需进一步判断,比如在 manageJob 包含了对不同情形下需要执行删除和创建 pod,注意到,最后操作都会落到对 pod 的管理上,这也是 job 资源的意义。同步完成后,更新 job 的最新状态。
注意这里获取资源对象都是从 informer,也即本地缓存中获取的。
func (jm *Controller) syncJob(key string) (bool, error) {
// 获取资源
ns, name, err := cache.SplitMetaNamespaceKey(key)
//
sharedJob, err := jm.jobLister.Jobs(ns).Get(name)
// 通过 job 获取关联 pods
pods, err := jm.getPodsForJob(&job)
if jobFailed {
// 如果 job 失败,删除 pods
jm.deleteJobPods(&job, activePods, errCh)
} else {
// 进一步分析以确定操作
if ...
jm.manageJob(activePods, succeeded, &job)
...
}
// 计算、修改 job status
...
// 即 updateJobStatus 更新 job status 信息
jm.updateHandler(&job)
}
在 manageJob 包含了对 job spec 中任务运行数量控制的核心逻辑,可以看出,当一个常规 job 被创建时,它会进入这里的创建 pod 分支以启动工作流程。
func (jm *Controller) manageJob(activePods []*v1.Pod, succeeded int32, job *batch.Job) (int32, error) {
parallelism := *job.Spec.Parallelism
if active > parallelism {
...
// 删除 pod
jm.podControl.DeletePod(job.Namespace, activePods[ix].Name, job)
} else if active < parallelism {
...
// 创建 pod,同时关联 pod 和 job
jm.podControl.CreatePodsWithControllerRef(job.Namespace, &job.Spec.Template, job, metav1.NewControllerRef(job, controllerKind)) }
}
}
关于对 pod 的控制逻辑都已完毕,我们最后来看 Controller 一个重要的任务是将资源当前的状态更新至 status 字段下,这里的逻辑比较简单,只需要将获取和计算好的当前状态更新到服务端,值得注意的是并不会也不能直接改动从 informer 中获取的对象(再次强调它是本地缓存),而是通过客户端(这里的 jobClient)直接向 API Server 提交请求更新状态。
func (jm *Controller) updateJobStatus(job *batch.Job) error {
jobClient := jm.kubeClient.BatchV1().Jobs(job.Namespace)
newJob, err = jobClient.Get(context.TODO(), job.Name, metav1.GetOptions{})
newJob.Status = job.Status
jobClient.UpdateStatus(context.TODO(), newJob, metav1.UpdateOptions{}); err == nil {
}
在上述介绍中,限于篇幅省略了对 expectations 的讨论,它是一个缓存工具用于保证同步过程中的数据一致性问题。因为在缓存场景下,运行时从缓存中获取的信息可能和服务端存在不一致的情况,在实现时需要考虑。
通过以 Job Controller 为例,我们介绍了 Controller 的原理和工作流程,简单地可以将 Controller 的工作原理总结为以下循环和图示。
for {
desired := getDesiredState() // spec
current := getCurrentState() // status
makeChanges(desired, current)
}
Operator 开发实践
当 Kubernetes 提供的工作负载无法满足需求场景时,我们可以考虑通过添加自定义资源和自定义控制器的方式来扩展 Kubernetes 功能,这里包含两层意思:
-
通过自定义资源 ( CustomResourceDefinition 简称 CRD)来拓展 Kubernetes API
-
通过部署对应的自定义 Controller 执行自定义资源的定制化逻辑
这种原生的拓展方式即 CRD 和 Controller 联合开发部署的方式被称为开发 Kubernetes 的 Operator.
开发自定义 Operator 时,可以使用一些开发工具来帮助我们自动构建开发 Operator 所需要的基础组件,比如 kubebuilder 是一个带有命令行工具和运行时库的构建工具,通过它可以快速构建一个生产部署 ready 的自定义 Operator,包括生成 RBAC 、yaml 配置等等。
下面以 CronJob 的 Operator 为例来介绍使用自定义 Operator 开发的流程和方法。
首先是通过 Golang struct 定义 CRD,前面介绍过,只需要关心 spec 和 status即可,
type CronJob struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec CronJobSpec `json:"spec,omitempty"`
Status CronJobStatus `json:"status,omitempty"`
}
根据具体的设计需要在 spec 中添加字段,可以一般也必然地会使用 kubernetes 内置的资源,这里 CronJob 中定义了 job,使用 job 资源类型来管理工作负载。
type CronJobSpec struct {
Schedule string `json:"schedule"`
JobTemplate batchv1beta1.JobTemplateSpec `json:"jobTemplate"`
...
}
Controller 对应这里的 CronJobReconciler,它的逻辑被封装为接口函数 Reconcile,这个函数会在资源发生变动时被触发,所以只需在函数内部专注编写同步状态逻辑即可。而且 Reconciler 还提供了高层 API 如 get/list/create 等操作,这些 API 来自于 controller-runtime 库中的 client,当有更灵活的调用需求时可以直接使用该库中的 API 进行资源操作而不必受限于这里封装的 Reconcile 函数。
func (r *CronJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
// 获取对象,再次注意三要素
var cronJob batch.CronJob
if err := r.Get(ctx, req.NamespacedName, &cronJob); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
var childJobs kbatch.JobList
r.List(ctx, &childJobs, client.InNamespace(req.Namespace), client.MatchingFields{jobOwnerKey: req.Name}); err != nil {
// 计算当前的状态,给 cronJob.Status 负值
cronJob.Status = getStatus()
// 更新状态
if err := r.Status().Update(ctx, &cronJob); err != nil {
// 更新不成功时,返回错误,将任务放入队列重新执行
return ctrl.Result{}, err
}
// 创建 job 实例
job, err := constructJobForCronJob(&cronJob, missedRun)
if err != nil {
return scheduledResult, nil
}
// 向服务端请求创建 job
if err := r.Create(ctx, job); err != nil {
return ctrl.Result{}, err
}
return scheduledResult, nil
}
同样值得关注的是 Controlller 被创建的部分,原 informer 中的索引和缓存逻辑被封装到了这里,根据拓展资源的定义在这里添加资源依赖关系和创建索引,除了工作负载如果需要用到其他 Kubernetes 资源也需要在这里进行添加,如 Service 和 Configmap 等,当使用非 Kubernetes 内置资源时,会形成必要的强依赖。
func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
// 创建本地缓存和索引
mgr.GetFieldIndexer().IndexField(context.Background(), &kbatch.Job{}, jobOwnerKey, func(rawObj client.Object) []string {}
// 构建资源依赖关系
return ctrl.NewControllerManagedBy(mgr).
For(&batch.CronJob{}).
Owns(&kbatch.Job{}).
Complete(r)
}
到这里使用 Operator 开发模式进行 Kubernetes 扩展的主要内容就介绍完了,更多的开发细节请参考 Kubernetes 和 kuberbuilder 的文档。
基于 kuberbuilder 开发的用于运行 paddlepaddle 分布式任务的 paddle-Operator 已经开源,感兴趣的朋友可以在这里找到源码,相互学习交流。
Reference
https://kubernetes.io/zh/docs/concepts/workloads/
https://kubernetes.io/zh/docs/concepts/extend-kubernetes/api-extension/custom-resources/
https://github.com/kubernetes-sigs/kubebuilder
https://github.com/kubernetes/api
https://github.com/cncf/tag-app-delivery/blob/main/operator-wg/whitepaper/Operator-WhitePaper_v1-0.md
device plugin
Docker
Expression
- containerd
- runc
- CRI
- OCI
- containerd-shim
- dockershim
install kubernetes
install kubelet kubeadm kubectl
set up yum
# /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
# /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-aarch64
enabled=1
gpgcheck=0
install kubeadm etc.
yum -y install ipvsadm ipset net-tools jq
yum -y install kubelet-1.23.1 kubeadm-1.23.1 kubectl-1.23.1
start kubelet
systemctl daemon-reload
systemctl enable kubelet
check kubeadm、kubelet、kubectl
kubelet --version
kubeadm version -o yaml
kubectl version --short
Node stop here to join master
config image for kubernetes
kubeadm config --kubernetes-version=v1.23.1 --image-repository=registry.aliyuncs.com/google_containers images list
config kubeadm
---
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.23.1
clusterName: kubernetes
imageRepository: registry.aliyuncs.com/google_containers
networking:
serviceSubnet: "10.96.0.0/16"
podSubnet: "10.100.0.0/16"
dnsDomain: "cluster.local"
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
deploy kubeadm
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee /tmp/kubeadm-init.log
egrep 'kubeadm.*join|discovery-token-ca-cert-hash' /tmp/kubeadm-init.log >$HOME/k8s.add.node.txt
kubectl auth
export KUBECONFIG=/etc/kubernetes/admin.conf
mkdir -p $HOME/.kube
ln -fs /etc/kubernetes/admin.conf $HOME/.kube/config
enable scheduling on master
kubectl taint nodes --all node-role.kubernetes.io/master-
kubectl taint nodes --all node-role.kubernetes.io/master=:PreferNoSchedule
deploy flannel with kube-flannel.yml
kubectl apply -f kube-flannel.yml
install dashboard (optional)
deploy dashboard
kubectl apply -f kubernetes-dashboard.yaml
kubernetes-dashboard.yaml
add auth
create sa dashboard-admin
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
show secret
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print 1}') | awk '/token:/{print2}' >HOME/k8s.token.dashboard.txt
# dashboard token
cat $HOME/k8s.token.dashboard.txt
cat $HOME/k8s.add.node.txt
kubectl get cs
kubectl get nodes
kubectl get pod -A
Local_IP=(kubectl -n kube-system get cm kubeadm-config -oyaml | awk '/advertiseAddress/{print $NF}')
echo " https://{Local_IP}:30000"
reference
reset kubeadm
kubeadm reset -f
systemctl stop kubelet
ifconfig flannel.1 down
ip link del flannel.1
ifconfig cni0 down
ip link del cni0
ifconfig flannel.1 tunl0
ip link del tunl0
ip link del kube-ipvs0
ip link del dummy0
ip link del tunl0@NONE
ipvsadm --clear
rm -rf /etc/cni/net.d
sync time
yum -y install ntpdate
ntpdate -u cn.ntp.org.cn
show ip
ip route show
firewall turn off
systemctl stop firewalld
systemctl disable firewalld
selinux turn off
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
swap turn off
swapoff -a
sed -i 's/.*swap.*/#&/' /etc/fstab
print join command
kubeadm token create --print-join-command
kubelet log
journalctl -xefu kubelet
kubectl drain <node-name> --ignore-daemonsets --delete-local-data
kubectl delete node
pause node
kubectl drain <node-name> --ignore-daemonsets --delete-local-data
kubectl uncordon node <node-name>
kubectl taint nodes node key=value1:NoSchedule
kubectl taint nodes node key:NoSchedule-
Restart DNS
kubectl -n kube-system rollout restart deployment coredns
ifconfig
ip link set cni0 down
brctl delbr cni0
ifconfig cni0 down
ifconfig flannel.1 down
ifconfig docker0 down
Ubuntu
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" >>/etc/apt/sources.list.d/kubernetes.list
upgrade
# renew certs
kubeadm init phase certs apiserver --config kubeadm-config.yaml
# upgrade
kubeadm upgrade apply --config kubeadm-config.yaml
# restart kubelet
systemctl restart kubelet.service
# check config
kubeadm config view
# check certSANs
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text
image gc
/var/lib/kubelet/config.yaml
imageGCHighThresholdPercent: 99
imageGCLowThresholdPercent: 98
NodeHasDiskPressure
/etc/default/kubelet (for DEBs), or /etc/sysconfig/kubelet (for RPMs).
vi /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS=--eviction-hard=nodefs.available<5% --eviction-hard=imagefs.available<3%
api-service
Create manifests
kubeadm init phase certs all
kubeadm init phase kubeconfig admin
kubeadm init phase etcd local
kubeadm init phase control-plane apiserver
PKI
manifests/etcd.yaml
- --client-cert-auth=true
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
kubeconfig
cluster:
server: https://xxx.xxx
certificate-authority: pki/ca.crt
user:
client-certificate:
client-key:
manifests/kube-apiserver.yaml
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt
- --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key
- --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
- --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --service-account-key-file=/etc/kubernetes/pki/sa.pub
- --service-account-signing-key-file=/etc/kubernetes/pki/sa.key
- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
controller
Scheme
src/k8s.io/apimachinery/pkg/runtime/scheme.go
- serializing and deserializing API objects
- converting group, version, and kind information
- foundation for a versioned API and versioned configuration
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes, addDefaultingFuncs)
AddToScheme = SchemeBuilder.AddToScheme
var scheme = runtime.NewScheme()
AddToScheme(scheme)
nvidia
| NAME | WHAT | SOURCE | HEADER | --- |
|---|---|---|---|---|
| CUDA | Compute Unified Device Architecture | N | cuda.h | libcuda.so |
| cuBLAS | Basic Linear Algebra Subroutine | N | cublas_v2.h | cublas.so |
| CUTLASS | CUDA Templates for Linear Algebra Subroutines | Y | cutlass/cutlass.h | |
| CUB | Cooperative primitives for CUDA C++ | Y | cub/cub.cuh | |
| Thrust | The C++ Parallel Algorithms Library | Y | thrust/.h | |
| cuSOLVER | LAPACK | N | cusolverDn.h | libcusolver.so |
CUDA
一般 CUDA 指 CUDA Toolkit
#include "cuda.h"
#include "cuda_runtime.h"
#include <iostream>
int main() {
int rt_ver, dr_ver;
auto err1 = cudaRuntimeGetVersion(&rt_ver);
if (err1 != cudaSuccess) {
std::cerr << cudaGetErrorString(err1) << std::endl;
return -1;
}
std::cout << "Runtime version: " << rt_ver << std::endl;
auto err2 = cudaDriverGetVersion(&dr_ver);
if (err2 != cudaSuccess) {
std::cerr << cudaGetErrorString(err2) << std::endl;
return -1;
}
std::cout << "Driver version: " << dr_ver << std::endl;
return 0;
}
cuBLAS
CUDA Basic Linear Algebra Subroutine library
CUTLASS
利用cutlass的warp和block层级的接口实现一个大的attention kernel为例, 难点主要是需要熟练使用cutlass,并能进行调优,而采用cutlass的开发有以下4个难点:
- cutlass并不是一个如cublas那样使用简单的GEMM库。cutlass仅提供threads block, warp, instruction各个级别的原语,开发者需要熟悉cutlass源码,并根据需求组装原语实现kernel。
- cutlass使用了大量的模版,在debug过程中需要阅读很长的log,且基本无法使用代码跳转工具,会给开发带来一定困难。
- cutlass并不提供自动调优的功能,需要开发者手动选择最优的设置,或者接入框架的自动调优中。
- 由于可能的组合非常多,基于cutlass进行开发时通常需要编写自动生成kernel的脚本。
从torch的实现上可以看出该工作需要的工作量还是比较大.
CUB
#include <cub/cub.cuh>
// Block-sorting CUDA kernel
__global__ void BlockSortKernel(int *d_in, int *d_out)
{
using namespace cub;
// Specialize BlockRadixSort, BlockLoad, and BlockStore for 128 threads
// owning 16 integer items each
typedef BlockRadixSort<int, 128, 16> BlockRadixSort;
typedef BlockLoad<int, 128, 16, BLOCK_LOAD_TRANSPOSE> BlockLoad;
typedef BlockStore<int, 128, 16, BLOCK_STORE_TRANSPOSE> BlockStore;
// Allocate shared memory
__shared__ union {
typename BlockRadixSort::TempStorage sort;
typename BlockLoad::TempStorage load;
typename BlockStore::TempStorage store;
} temp_storage;
int block_offset = blockIdx.x * (128 * 16); // OffsetT for this block's ment
// Obtain a segment of 2048 consecutive keys that are blocked across threads
int thread_keys[16];
BlockLoad(temp_storage.load).Load(d_in + block_offset, thread_keys);
__syncthreads();
// Collectively sort the keys
BlockRadixSort(temp_storage.sort).Sort(thread_keys);
__syncthreads();
// Store the sorted segment
BlockStore(temp_storage.store).Store(d_out + block_offset, thread_keys);
}
cuSolver
cuSolverDN: Dense LAPACK
, solve .
cuSolverSP: Sparse LAPACK
, solve
cuSolverRF: Refactorization
, solve .
Thrust
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
#include <thrust/sort.h>
#include <thrust/copy.h>
#include <thrust/random.h>
int main() {
// Generate 32M random numbers serially.
thrust::default_random_engine rng(1337);
thrust::uniform_int_distribution<int> dist;
thrust::host_vector<int> h_vec(32 << 20);
thrust::generate(h_vec.begin(), h_vec.end(), [&] { return dist(rng); });
// Transfer data to the device.
thrust::device_vector<int> d_vec = h_vec;
// Sort data on the device.
thrust::sort(d_vec.begin(), d_vec.end());
// Transfer data back to host.
thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin());
}
Comparasion
NVIDIA HPC SDK vs CUDA Toolkit
cuda.h vs cuda_runtime.h
Reference
cuda 101
CUDA 全称 Compute Unified Devices Architecture 是使用大量 GPU 计算单元进行通用计算的平台。
CUDA C/C++ 是基于标准 C/C++ 的拓展,实现异构计算。 这里说的异构计算主要指
- 主机 cpu host 和主机内存 host memory
- GPU 设备 device 和设备内存 device memory
CPU 架构有复杂的缓存体系,指令延迟非常小,大量的晶体管处理逻辑任务; GPU 拥有更多的计算单元和高带宽,有更高的吞吐,大量的晶体管处理数值和逻辑运算;
todo
Gloo
TL;DR;
Gloo 是集合通信和算法库。运行逻辑如下,
- 定义网络设备信息创建通信媒介 Device;
- 使用可以共同交换数据的 Store 实现 rendezvous;
- 节点通过 (rank, size) 创建 Context, 使用 connectFullMesh 方法建立通信域:
- 向 Store 注册自身节点信息;
- 从 Store 中获取全部节点信息;
- 启动 n-1 个服务分别与其余节点建立连接;
- 通过 Context 使用集合通信功能。
Concepts
Device
Device 是通信设备的抽象。
Context
Context 负责建立管理通信域。
Store
Store 是实现 rendezvous 的介质,是实现共识的媒介。
Address
gloo::transport::tcp::Address 是对网络地址的封装。
attr
gloo::transport::tcp::attr 是对网络通信属性的结构体封装,ip、网卡等信息。
Gloo v.s. MPI
More
ibverbs 是使用 IB(InfiniBand) 的 API.
Workflow
int main(void) {
// Device
gloo::transport::tcp::attr attr;
auto dev = gloo::transport::tcp::CreateDevice(attr);
// Store
auto fileStore = gloo::rendezvous::FileStore("/tmp");
auto prefixStore = gloo::rendezvous::PrefixStore(prefix, fileStore);
// Context
auto context = std::make_shared<gloo::rendezvous::Context>(rank, size);
context->connectFullMesh(prefixStore, dev);
}
// gloo/rendezvous/context.cc
void Context::connectFullMesh(
rendezvous::Store& store,
std::shared_ptr<transport::Device>& dev) {
// localKey = 'rank_0'
// value = 'host-0'
store.set(localKey, value);
for (int i = 0; i < size; i++) {
// i != rank
auto val = store.get(key);
}
auto transportContext = dev->createContext(rank, size);
for (int i = 0; i < size; i++) {
// i != rank
auto& pair = transportContext->createPair(i);
}
// '0'
// [host-0]:9000[host-1]:9001
store.set(storeKey.str(), allBytes);
for (int i = 0; i < size; i++) {
// i != rank
store.wait({key.str()}, getTimeout());
auto allAddrs = store.get(key.str());
auto addr = extractAddress(allAddrs, i);
transportContext->getPair(i)->connect(addr);
}
}
std::unique_ptr<transport::Pair>& Context::createPair(int rank) {
pairs_[rank] = std::unique_ptr<transport::Pair>(
new tcp::Pair(this, device_.get(), rank, getTimeout()));
return pairs_[rank];
}
创建 Pair 对象会在本地启动 tcp socket 服务。
// gloo/transport/tcp/pair.cc
Pair::Pair(
Context* context,
Device* device,
int rank,
std::chrono::milliseconds timeout) {
listen();
}
void Pair::listen() {
std::lock_guard<std::mutex> lock(m_);
int rv;
const auto& attr = device_->attr_;
auto fd = socket(attr.ai_family, attr.ai_socktype, attr.ai_protocol);
rv = bind(fd, (const sockaddr*)&attr.ai_addr, attr.ai_addrlen);
fd_ = fd;
rv = ::listen(fd_, 1);
self_ = Address::fromSockName(fd);
device_->registerDescriptor(fd_, EPOLLIN, this);
return;
}
Reference
mpi
Jax
JAX has 4 main function transformations
-
grad()to automatically differentiate a function -
vmap()to automatically vectorize operations -
pmap()for parallel computation of SPMD programs -
jit()to transform a function into a JIT-compiled version
These transformations are (mostly) composable, very powerful, and have the potential to expedite your programs several times over.
https://www.assemblyai.com/blog/why-you-should-or-shouldnt-be-using-jax-in-2022/
TVM
Expression
TE Tensor Expression, DSL (domain-specific language)
Relay TVM’s high-level model language
IR intermediate representation
TIR Tensor Intermediate Representation, TVM’s low-level intermediate representation
Schedule how to execute the computation
Stage schedule for one operation
TOPI TVM Operator Inventory, numpy-style generic operations and schedules
Demo
from tvm.driver import tvmc
#Step 1: Load
model = tvmc.load('resnet50-v2-7.onnx', shape_dict={'data':[1, 3, 224, 224]})
#Step 1.5: Optional Tune
tuning_records = tvmc.tune(model, target="llvm")
#Step 2: Compile
package = tvmc.compile(model, target="llvm", tuning_records = tuning_records)
#Step 3: Run
result = tvmc.run(package, device="cpu")
print(result)
- IRModule: relay.Function + tir.PrimFunc
- tvmc.compile: relay::Function --> tir::PrimFunc
Why TVM ?
tvmc.tune make model run more fast.
How ?
ALL, especially,
AutoTVM (template-based) or AutoScheduler (Ansor, template-free auto-tuning)
TVM optimizaing compiler workflow
- TF/PyTroch/ONNX
- Relay (High-level IR)
- TE (Computation definition)
- AutoTVM/AutoScheduler (Auto-tuining module)
- TE + Schedule (Optimization specification)
- TIR (Low-level IR)
- Machine Code
流程解析
- TVM 数据输入格式,prefer ONNX
- TVM 高级 API 操作计算图
- Relay 通过 fuseops pass 生成子图,同时有 schedule primitives 对 low-level loop 进行优化,Tensor Operator Inventory (TOPI) 处理常规 op, 生成 TE
- 通过 AutoTVM (template-based) 或 AutoScheduler (template-free auto-tuning) 寻找最佳 schedule
- 生成 json 格式 tuning records, 包含最佳 schedule
- 生成 TIR,支持主流 LLVM/NVCC
- 生成机器码
low-level loop optimizations: tiling, vectorization, parallelization, unrolling, and fusion
TVM Auto-scheduler (a.k.a. Ansor)
package tvm.auto_scheduler
Schedule Primitives
How to get good performance kernel ?
TE
import tvm
from tvm import te
m = te.var('m')
n = te.var('n')
a = te.placeholder((m, n), name='A')
b = te.placeholder((m, n), name='B')
c = te.compute((m, n), lambda i, j: a[i, j]*b[i, j], name='C')
s = te.create_schedule([c.op])
tgt = tvm.target.Target(target="llvm", host="llvm")
mult = tvm.build(s, [a, b, c], target=tgt, name="mult")
print(mult.get_source())
print(tvm.lower(s, [a, b, c], simple_mode=True))
tvm.build
tvm.te.schedule.Schedule, tvm.tir.PrimFunc, IRModule, Mapping[str, IRModule] --> tvm.runtime.Module
A module that combines both host and device code
tvm.lower
tvm.te.schedule.Schedule, tvm.tir.PrimFunc, IRModule --> IRModule
Demo for IRModule transform
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
import numpy as np
from tvm import te
A = te.placeholder((8,), dtype="float32", name="A")
B = te.compute((8,), lambda *i: A(*i) + 1.0, name="B")
func = te.create_prim_func([A, B])
ir_module = IRModule({"main": func})
print(ir_module.script())
"""
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0 in T.serial(8):
with T.block("B"):
i0_1 = T.axis.spatial(8, i0)
T.reads(A[i0_1])
T.writes(B[i0_1])
B[i0_1] = A[i0_1] + T.float32(1)
"""
# <class 'tvm.driver.build_module.OperatorModule'>
mod = tvm.build(ir_module, target="llvm") # The module for CPU backends.
# <class 'tvm.tir.schedule.schedule.Schedule'>
sch = tvm.tir.Schedule(ir_module)
block_b = sch.get_block("B")
(i,) = sch.get_loops(block_b)
i_0, i_1, i_2 = sch.split(i, factors=[2, 2, 2])
print(sch.mod.script())
"""
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0_0, i0_1, i0_2 in T.grid(2, 2, 2):
with T.block("B"):
i0 = T.axis.spatial(8, i0_0 * 4 + i0_1 * 2 + i0_2)
T.reads(A[i0])
T.writes(B[i0])
B[i0] = A[i0] + T.float32(1)
"""
sch.reorder(i_0, i_2, i_1)
print(sch.mod.script())
"""
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0_0, i0_2, i0_1 in T.grid(2, 2, 2):
with T.block("B"):
i0 = T.axis.spatial(8, i0_0 * 4 + i0_1 * 2 + i0_2)
T.reads(A[i0])
T.writes(B[i0])
B[i0] = A[i0] + T.float32(1)
"""
sch.bind(i_0, "blockIdx.x")
sch.bind(i_2, "threadIdx.x")
print(sch.mod.script())
"""
# from tvm.script import tir as T
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[8, "float32"], B: T.Buffer[8, "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0_0 in T.thread_binding(2, thread="blockIdx.x"):
for i0_2 in T.thread_binding(2, thread="threadIdx.x"):
for i0_1 in T.serial(2):
with T.block("B"):
i0 = T.axis.spatial(8, i0_0 * 4 + i0_1 * 2 + i0_2)
T.reads(A[i0])
T.writes(B[i0])
B[i0] = A[i0] + T.float32(1)
"""
Relay
relay.build()
return
- execution graph in json format
- TVM module library of compiled functions specifically for this graph on the target hardware
- parameter blobs of the model
During the compilation,
- Relay does the graph-level optimization,
- TVM does the tensor-level optimization,
resulting in an optimized runtime module for model serving.
Relay v.s. TE
tvm.tir.sqrt(x: tvm.ir.PrimExpr) -> tvm.ir.PrimExpr
# Alias of tvm.tir.sqrt()
tvm.te.sqrt(x: tvm.ir.PrimExpr) -> tvm.ir.PrimExpr
tvm.relay.sqrt(data: tvm.ir.RelayExpr) -> tvm.ir.RelayExpr)
For tvm.ir.BaseExpr,
- PrimExpr is class of all primitive expressions, used in the low-level code optimizations and integer analysis.
- RelayExpr is class of all non-primitive expressions.
Build
tvm.build v.s. tvm.relay.build
tvm.relay.build(ir_mod: IRModule, target, target_host, executor=graph{}, runtime=cpp)
-> tvm.relay.backend.executor_factory.ExecutorFactoryModule
tvm.build(inputs: Union[tvm.te.schedule.Schedule, tvm.tir.function.PrimFunc, tvm.ir.module.IRModule, Mapping[str, tvm.ir.module.IRModule]], args, target, target_host, runtime, binds)
-> tvm.driver.build_module.OperatorModule
Optimization
Blocking, Cache
通过分 Block, 让留在 cache 中的中间计算结果能够发挥作用,从而提升性能。
Vectorization, Array Packing
连续的内存访问会比较高效,通过 vectorize 达到这样的目的。对矩阵的 Array Packing 也是在做这样的优化。
Parallelization
非依赖的情况下可以使用并行策略提高整体性能。
TOPI
n = te.var("n")
m = te.var("m")
A = te.placeholder((n, m), name="A")
origin
k = te.reduce_axis((0, m), "k")
B = te.compute((n,), lambda i: te.sum(A[i, k], axis=k), name="B")
s = te.create_schedule(B.op)
# print(tvm.lower(s, [A], simple_mode=True))
TOPI
C = topi.sum(A, axis=1)
ts = te.create_schedule(C.op)
# print(tvm.lower(ts, [A], simple_mode=True))
Develop
- write a pass with IR
- glue to lowering
每一个 phase 做的 transformation 如下,
- Phase 0 generates the raw IR and loop levels.
- Phase 1 flattens the array storage.
- Phase 2 transforms loops, like unroll, vectorization and thread-binding.
- Phase 3 does some cleanup work.
所以比如自定义的 vectorize 适合放在 phase 1 之后。
with tvm.transform.PassContext(config={"tir.add_lower_pass": [(1, vectorize)]}):
print(tvm.lower(sch, [a, b, c]))
Reference
github
LocalAI
AI
leptonai A Pythonic framework to simplify AI service building
landscape2 Landscape2 is a tool that generates interactive landscapes websites, sncf
Tools
Triton
OpenAI triton
AST/Visitor Triton/Compiler libLLVM
Python --------> Triton-IR ------> LLVM-IR ------> PTX
Lightning
Fairscale
PEFT
PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.
Methods:
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- P-Tuning: GPT Understands, Too
Idea
描述不准原理:描述的简洁和准确不可同时达到
The art of negotiation: Six must-have strategies
influence and persuasion
How do your actions and relationships frame your ability to impact, influence and persuade? Gillian Ku, Professor of Organisational Behaviour, shares six interpersonal principles of how we interact with people that affect one’s ability to influence and persuade others.
Reciprocity
We try to repay in kind what another person has provided us.
An overpowering rule that enforce the uninvited debts.
Examples/Use
- free gift
- survey with 25 dollar if return VS 5 dollar whatever
- reciprocal concession in negotiations.
Defuse
- reject gift
- accept but wary, even redefine a relationship
- excuse for let me think about your offer
- organizational limits
Commitments and Consistency
Once we make a choice, we will encounter personal or interpersonal pressures to behave consistently.
Commitments are most effective when they are active, public, effortful and viewed as uncoerced.
Examples/Use
- Petitions
- foot in door technique
Defuse
- ignore sunk costs
- neutral party check judgement
- avoid public commitments unless you are certain
Social Proof
The greater the number of people who find any idea correct, the more we will perceive the idea to be correct.
We use others actions to decide on proper behaviors for ourselves when uncertainty reign and others are similar to us.
Examples/Use
- laugh tracks
- auctions, merges and acquisitions
Defuse
- understand your motivations for doing something, don't just follows the crowd
Liking
We prefer to say yes to the requests of people we know and like.
We tend to like people who are
- physical attractive
- similar to us
- familiar
- compliment us
- associated with positive things
Authority
We tend to defer to (obey) authorities in a mindless fashion.
Tendency to respond to mere symbolic authority, e.g. titles, uniforms, trappings.
Scarcity
We tend to assign more value to opportunities when they are less available.
Scarcity is particularly potent where things are newly scarce and when we compete with others for them.
Limited numbers and time limits.
Examples/Use
- buy now
- auction fever, competition, scarcity and time pressure
- open house
Defuse
- beware an adrenalin rush
- understands your motivations
Principle of influence
interpersonal influence tactics procedural influence tactics decision-making biases
How you say something is as important than what you say
reference
https://www.youtube.com/watch?v=uKbcmlKb81c
Learn Anything Faster By Using The Feynman Technique
Richard Feynman is considered to be one of the most miraculous personalities in scientific history. The 1965 Nobel prize winner on QED (along with J. Schwinger and Tomonaga), Dr. Feynman was a remarkably amazing educator and a great physicist. Feynman, along with many other contributions to science, had created a mathematical theory that accounts for the phenomenon of superfluidity in liquid helium. Thereafter, he had fundamental contributions (along with Murray Gell-Mann) to weak interactions such as beta decay. In his later years, Feynman played a significant role in the development of quark theory by putting forward his Parton model of high energy proton collision processes. He also introduced basic new computational techniques and notations into physics. Besides being a physicist, he was at various times repairer of radios, a picker of locks, an artist, a dancer, a bongo player, a great teacher, and a showman who successfully demonstrated the cause of the 1986 Challenger Shuttle Disaster as part of the Roger’s Commission. A truer description would have said that Feynman was all genius and all buffoon. The deep thinking and the joyful clowning were not separate parts of a split personality… He was thinking and clowning simultaneously.” — Freeman Dyson, 1988 remark on Feynman.
The genius of Richard Feynman in evident from his three-volume books on physics called The Feynman Lectures on Physics, which are based on his lectures at Caltech during 1961–1963. In his teenage years, Richard Feynman’s high school did not offer any courses on calculus. As a high-school teenager, he decided to teach himself calculus and read Calculus for the Practical Man.
Feynman always believed that if one cannot explain something in simple terms, one doesn’t understand it. A similar quotation is attributed to Albert Einstein as well. Whether or not it originally comes from Feynman, the idea is elegantly true and is, in fact, the basis for the Feynman technique of learning things. Feynman is often attributed as The Great Explainer for his ability to explain complicated concepts in science, particularly physics, in extremely simple and understandable manner, in a way that in people from a non-scientific background could understand. He opened a fresh notebook. On the title page he wrote: NOTEBOOK OF THINGS I DON’T KNOW ABOUT. For the first but not last time he reorganized his knowledge. He worked for weeks at disassembling each branch of physics, oiling the parts, and putting them back together, looking all the while for the raw edges and inconsistencies. He tried to find the essential kernels of each subject. — James Gleick on his biography of Richard Feynman What is the Feynman technique?
The Feynman technique of Learning primarily involves four simple steps:
- Pick a topic you want to understand and start studying it
- Pretend to teach the topic to a classroom or a child or someone who is unfamiliar with the topic
- Go back to the resource material when you get stuck
- Simplify and Organize
Step-1: This technique is applicable to pretty much any discipline or any subject and concept despite the fact that it says the Feynman technique, it is not just limited to math or physics and can be applied to a wide range of fields. The first step to use this technique is to choose the topic and start studying it. Now, studying doesn’t mean just memorizing the facts. In fact, Feynman himself was always against the culture of memorization and he always believed that one should learn and understand the principles rather than memorizing the facts or formulae. Another good method of studying something is to write. Writing something on a piece of paper stimulates the Hippocampus of your brain, the part which is primarily responsible for memory and learning.
Step-2: If you want to master something, teach it. Teaching is a powerful tool for learning. Explain the concepts in your own words and try to explain it to a child or someone who is completely unfamiliar with the topic. You can also pretend to explain it to a rubber duck that in on your table. The idea is to try and break things down in as much simpler and plain language as possible. Try to use simple terms and vocabularies and don’t limit yourself to just the facts that you’ve learned. You may as well include an example or two to make things simpler or create your own example making sure that it is associated with the main idea. It becomes much easier for you to understand things at a deeper level if you do so and helps you make connections. All things are made of atoms — little particles that move around in perpetual motion, attracting each other when they are a little distance apart, but repelling upon being squeezed into one another. In that one sentence … there is an enormous amount of information about the world. - His suggestion that the most valuable information on scientific knowledge in a single sentence using the fewest words is to state the atomic hypothesis.
Step-3: This is an extremely crucial step where you learn where you are lacking. As you are explaining or writing things in simple terms, you always come across certain areas where you are find it difficult to explain or make connections or formulate examples. This is the point where you get back to the resource material, the books or journals or internet, whatever your primary references are, and fill the gaps in your knowledge. You can identify your gaps by several instances, like not being able to explain something or simplify something, forgetting some important points and so on. The idea is to get back, and revise things once again. This helps you understand things even better. In this step, you know the areas that you need to work on and focus on which is a significant part of the learning process. Knowing one’s limitations and then working upon them to understand them better is the point of this step and it works like magic.
Step-4: Here comes the product now. Once you have corrected your mistakes and straightened your difficulties, you simplify your explanation and make it better. You can always go back to Step-2 and Step-3 until you have a clear-cut understanding of the subject matter. Your notes and examples are now in the simplest form possible and you have a deeper understanding of the topic under study. You can follow this approach over and over again till you feel like you have mastered the concept.
After your final explanation is ready, you can convey it to your colleagues or friends or professionals who are familiar with your field of expertise and reflect back upon your understanding of things. This Test-and-Learn method works wonders. Feynman always believed that the truth lies in simplicity and that things can be better understood when they are simple and elegant. It is much easier to overcomplicate things, which often shows the lack of deep understanding. The idea is to make things simple enough to be understood by anyone and then using that tool for deeper understanding for yourself. The Feynman technique of Learning helps you learn and understand things by a different perspective. It can be used not just for academic purposes but also for building businesses, creating startups, mental models, and many more. The Feynman Technique is a great method to develop mastery over pretty much set of information.
A wavelet tour of signal processing the Sparse way
Stephane Mallat
history
- 1910 - Haar - a piecewise constant function
- 1980 - Stromberg - a piecewise linear function - an orthonormal basis, better approximation of smooth function
- Morlet, Grossmann - continuous wavelet transform
- Meyer - a family of orthonormal wavelet bases with function infinitely continuously differentiable
- Daubechies - wavelets of compact support
Time-Frequency localisation trade-off
Keeping , by denoting
then
it shows that we lose in frequency while we gain in time.
tips
ip_local_port_range
Tests
preset
echo "61000 61001" | sudo tee /proc/sys/net/ipv4/ip_local_port_range
61000 61001
cat /proc/sys/net/ipv4/ip_local_port_range
61000 61001
normally,
nohup nc 123.125.114.144 80 -v &
[1] 16196
nohup: ignoring input and appending output to 'nohup.out'
nohup nc 123.125.114.144 80 -v &
[2] 16197
nohup: ignoring input and appending output to 'nohup.out'
ss -ant |grep 10.0.2.15:61
ESTAB 0 0 10.0.2.15:61001 123.125.114.144:80
ESTAB 0 0 10.0.2.15:61000 123.125.114.144:80
as expected,
nc 123.125.114.144 80 -v
nc: connect to 123.125.114.144 port 80 (tcp) failed: Cannot assign requested address
while
nohup nc 123.125.114.144 443 -v &
[3] 16215
nohup: ignoring input and appending output to 'nohup.out'
nohup nc 123.125.114.144 443 -v &
[4] 16216
nohup: ignoring input and appending output to 'nohup.out'
ss -ant |grep 10.0.2.15:61
ESTAB 0 0 10.0.2.15:61001 123.125.114.144:443
ESTAB 0 0 10.0.2.15:61001 123.125.114.144:80
ESTAB 0 0 10.0.2.15:61000 123.125.114.144:443
ESTAB 0 0 10.0.2.15:61000 123.125.114.144:80
further,
nohup nc 220.181.57.216 80 -v &
[5] 16222
nohup: ignoring input and appending output to 'nohup.out'
nohup nc 220.181.57.216 80 -v &
[6] 16223
nohup: ignoring input and appending output to 'nohup.out'
nc 220.181.57.216 80 -v
nc: connect to 220.181.57.216 port 80 (tcp) failed: Cannot assign requested address
ss -ant |grep :80
SYN-SENT 0 1 10.0.2.15:61001 220.181.57.216:80
SYN-SENT 0 1 10.0.2.15:61000 220.181.57.216:80
SYN-SENT 0 1 10.0.2.15:61001 123.125.114.144:80
SYN-SENT 0 1 10.0.2.15:61000 123.125.114.144:80
Above test are available since linux kernel 3.2.
Reference
infrastructure
PKI
Concepts
-
PKI: Public Key Infrastructure
-
TLS: Transport Layer Security
-
SSL: Secure Sockets Layer
-
RSA: Rivest–Shamir–Adleman
-
CSR: Certificate Signing Request
-
CA: certificate authority
-
PEM: Privacy Enhanced Mail
Encryption and Decryption
Symmetric encryption and decryption
echo "private message" > plaintext.txt
KEY=`openssl rand -hex 32`
IV=`openssl rand -hex 16`
openssl enc -aes-256-cbc -K <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.76666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.07153em;">K</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.22222em;">Y</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span></span></span></span>IV -in plaintext.txt -out encrypted.txt
openssl enc -aes-256-cbc -d -K <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.76666em;vertical-align:-0.08333em;"></span><span class="mord mathnormal" style="margin-right:0.07153em;">K</span><span class="mord mathnormal" style="margin-right:0.05764em;">E</span><span class="mord mathnormal" style="margin-right:0.22222em;">Y</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222222222222222em;"></span></span><span class="base"><span class="strut" style="height:0.65952em;vertical-align:0em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span></span></span></span>IV -in encrypted.txt -out decrypted.txt
Key
private key
Generate private key
openssl genpkey -algorithm RSA -pkeyopt rsa_keygen_bits:2048 -out private_key.pem
-----BEGIN PRIVATE KEY-----
MIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoIBAQC/HvhWEGsLHE9a...
-----END PRIVATE KEY-----
- PEM encoding
- Base64 encoding
Generate RSA private key
openssl genrsa -out sa.key 2048
public key
openssl rsa -pubout -in private_key.pem -out public_key.pem
Verification
Sign with private key, verify with public key.
openssl dgst -sha256 -sign private_key.pem -out signature message.txt
openssl dgst -sha256 -verify public_key.pem -signature signature message.txt
Encryption and decryption
Encrypt with public key, decrypt with private key.
Example with genkey
openssl genpkey -algorithm RSA -out private_key.pem -pkeyopt rsa_keygen_bits:2048
openssl rsa -pubout -in private_key.pem -out public_key.pem
openssl rsautl -encrypt -inkey public_key.pem -pubin -in message.txt -out message.enc
openssl rsautl -decrypt -inkey private_key.pem -in message.enc -out message.dec
Example with genrsa
openssl genrsa -out sa.key 2048
openssl rsa -pubout -in sa.key -out sa.pub
openssl rsautl -encrypt -inkey sa.pub -pubin -in message.txt -out message.enc
openssl rsautl -decrypt -inkey sa.key -in message.enc -out message.dec
x509
CA
openssl genpkey -algorithm RSA -out ca.key
openssl req -x509 -new -nodes -key ca.key -sha256 -days 365 -out ca.crt -subj "/C=CN/ST=Beijing/L=Beijing/O=Company/OU=IT/CN=CA"
Server
openssl genpkey -algorithm RSA -out server.key
openssl req -new -key server.key -out server.csr -subj "/C=CN/ST=Beijing/L=Beijing/O=Company/OU=IT/CN=localhost" -addext "subjectAltName=DNS:localhost"
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt -days 365 -sha256 -extfile <(printf "subjectAltName=DNS:localhost")
Client
openssl genpkey -algorithm RSA -out client.key
openssl req -new -key client.key -out client.csr -subj "/C=CN/ST=Beijing/L=Beijing/O=Company/OU=IT/CN=localhost" -addext "subjectAltName=DNS:localhost"
openssl x509 -req -in client.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out client.crt -days 365 -sha256 -extfile <(printf "subjectAltName=DNS:localhost")
Show the cerfificate
openssl x509 -text -noout -in server.crt
openssl x509 -text -noout -in client.crt
curl -k https://localhost:8443
curl --cacert ca.crt https://localhost:8443
curl --cacert ca.crt --key client.key --cert client.crt https://localhost:8443
| client \ server | CA | SelfSigned | VerifyClient | --- |
|---|---|---|---|---|
| CA | OK | - | - | |
| skip | OK | OK | NO | |
| client | - | - | OK |
Munual Verification
openssl s_client -connect localhost:8443 -showcerts
openssl verify -CAfile ca.crt server.crt
ssh-keygen
TODO: Can ssh-key pair used to verification ?
# Generate private key
ssh-keygen -t rsa -b 2048 -f id_rsa
# Extract public key
ssh-keygen -y -f id_rsa > id_rsa.pub
# Convert public key to pem format
ssh-keygen -f id_rsa.pub -e -m pem > id_rsa_pub.pem
# Sign file with private key
openssl dgst -sha256 -sign id_rsa -out signature.sig id_rsa.pub
# Verify the signature with public key
openssl dgst -sha256 -verify id_rsa_pub.pem -signature signature.sig id_rsa.pub
openssl rsa -in id_rsa -pubout -out id_rsa.pub.pem
ssh-keygen
| Command | private | public | --- | --- |
|---|---|---|---|---|
| ssh-keygen | id_rsa | id_rsa.pub | --- | --- |
| openssl rsa | sa.key | sa.pub | --- | --- |
References
- https://en.wikipedia.org/wiki/Public_key_infrastructure
- https://serverfault.com/questions/9708/what-is-a-pem-file-and-how-does-it-differ-from-other-openssl-generated-key-file
- https://www.ssh.com/academy/ssh/keygen
cache
Design Pattern
Cache aside
- read cache before store
- client-driven cache save
Read through
- cache as proxy
- server-driven cache save
Write through
- update cache sync store
Write behind caching
linux page cache
- lazy write
projects
copilot
Goals
Run local copilot with llm.
References
- https://developer.apple.com/metal/pytorch/
- https://github.com/vllm-project/vllm
library
https://arxiv.org/pdf/2407.01219
Vector Database
- https://github.com/milvus-io/milvus
- https://github.com/qdrant/qdrant
RAG
qdrant
docker
run -d -p 6333:6333 \
-v (pwd)/data:/qdrant/storage \
-v (pwd)/snapshots:/qdrant/snapshots \
-v (pwd)/config.yaml:/qdrant/config/production.yaml \
qdrant/qdrant
config.yaml https://github.com/qdrant/qdrant/blob/master/config/config.yaml
chronicles
chronicles
Feb 13
Summarizey the story of invention of Blue LED.
The invention of the blue LED was a significant breakthrough in lighting technology, for which Isamu Akasaki, Hiroshi Amano, and Shuji Nakamura were awarded the Nobel Prize in Physics in 2014. Shuji Nakamura, a Japanese-born American electronic engineer, played a key role in this innovation. He worked at the Nichia Corporation, where he developed a bright blue LED using indium gallium nitride (InGaN) and a low-temperature heating method, significantly increasing its efficiency. This blue LED was nearly 100 times brighter than existing ones at the time, enabling its use in various applications. By combining the bright blue LED with fluorescent material, Nakamura enabled the creation of white light. Additionally, this development led to the production of power-efficient screens used in televisions, computer monitors, and smartphones. The blue LED also paved the way for the invention of the blue laser, which significantly increased storage capacity and led to the creation of new industry standards. Nakamura's invention of the blue LED was a game-changer in the lighting industry, with far-reaching implications for energy-efficient lighting and display technologies. Despite the immense impact of his invention, it is worth noting that Nakamura initially received only 180 for his discovery.
- https://www.nobelprize.org/prizes/physics/2014/press-release/
- https://www.invent.org/blog/inventors/shuji-nakamura-blue-led-lights
- https://en.wikipedia.org/wiki/Shuji_Nakamura
How pigment works ?
Pigments work by selectively absorbing certain wavelengths of light and reflecting or transmitting others, which determines their color. This process is known as subtractive color, and it's what happens with paints and dyes. The absorbed colors are the ones you don't see, and you see only the colors that come bouncing back to your eye. Pigments are insoluble and chemically unreactive substances that are used to add color or change the visual appearance of materials. They can be organic or inorganic, with inorganic pigments being brighter and longer-lasting than organic ones. The color of pigments arises because they absorb only certain wavelengths of visible light, and this absorption is the result of charge transfer between a metal for inorganic pigments, or conjugated double bonds for organic pigments. In summary, pigments work by selectively absorbing and reflecting light to produce the colors we see.
Is there blue pigment in the nature ? And how the blue pigment is different from others ?
Natural blue pigments are rare in nature. The color blue found in foods, plants, and animals often lacks a chemical compound that makes them blue, making natural blue pigment uncommon. For instance, the majority of natural blue colors in food are derived from the purple compound "anthocyanin," which can also produce rich red and black shades in addition to blue and purple. Blue colors in animals are often achieved through the manipulation of light, such as the layered nanostructures on the wing scales of blue-winged butterflies or the light-scattering structures in blue birds. The only known animal to produce a true blue pigment is the Obrina Olivewing butterfly, which uses a bile pigment called biliverdin to achieve its blue color. Therefore, true blue pigments are rare in nature, and the blue color in living organisms is often achieved through structural or optical means rather than through a chemical pigment.
Feb 10
Tweet
Elad Hazan: most exciting paper ever from our @GoogleAI lab at @Princeton : @naman33k @danielsuo @XinyiChen2 https://arxiv.org/abs/2312.06837 Convolutional filters predetermined by the theory, no learning needed!
Yann Lecun:
Hi Elad, basically, you are backpedaling to the old days of statistical pattern recognition when the entire literature was devoted to designing fixed feature extractors by exploiting the properties of the signal.
Pretty much every signal classification system (including speech recognition) used to use spectral features of some kind (computed by banks of wavelet-like filters), followed by some sort of non-linearity (e.g. square complex modulus) and temporal pooling.
9 years ago, Stéphane Mallat made a bet with me: he claimed that he could use features from his scattering transform followed by a simple trainable classifier and approach the performance of convnets on ImageNet.
The scattering transform architecture looks very much like a convnet (and is inspired by it), except that the kernels are fixed wavelets, whereas in convnets, the kernels are all learned.
The prize was a meal at a 3-star restaurant.
He admitted defeat after 5 years.
He said, "I learned something while trying to understand why it didn't work."
Elad Hazan:
Hi Yann, is this is an invitation for another bet? I'll take it, worst case I have to pay for dinner w. you ;-)
These particular filters have a nice property: they can learn a symmetric LDS without dependence on the condition number (effective memory).
The hope is they can help, but not replace, the learned component. My bet would be that this improves performance, in tasks requiring long memory. But there is no claim that it replaces learning completely.
You would agree that in certain cases, pre-fixed structures can help? That is the case, for example, in adaptive gradient methods for optimization, where a predefined rule is helpful.
- https://twitter.com/ylecun/status/1756249264500380129
- https://arxiv.org/abs/2312.06837
Feb 9
- 2B/3B
- Deployment on Mobile Phone, ~10 tokens/s
- 面壁智能
- https://github.com/OpenBMB/MiniCPM
compare fine-tuned version v.s. sft version