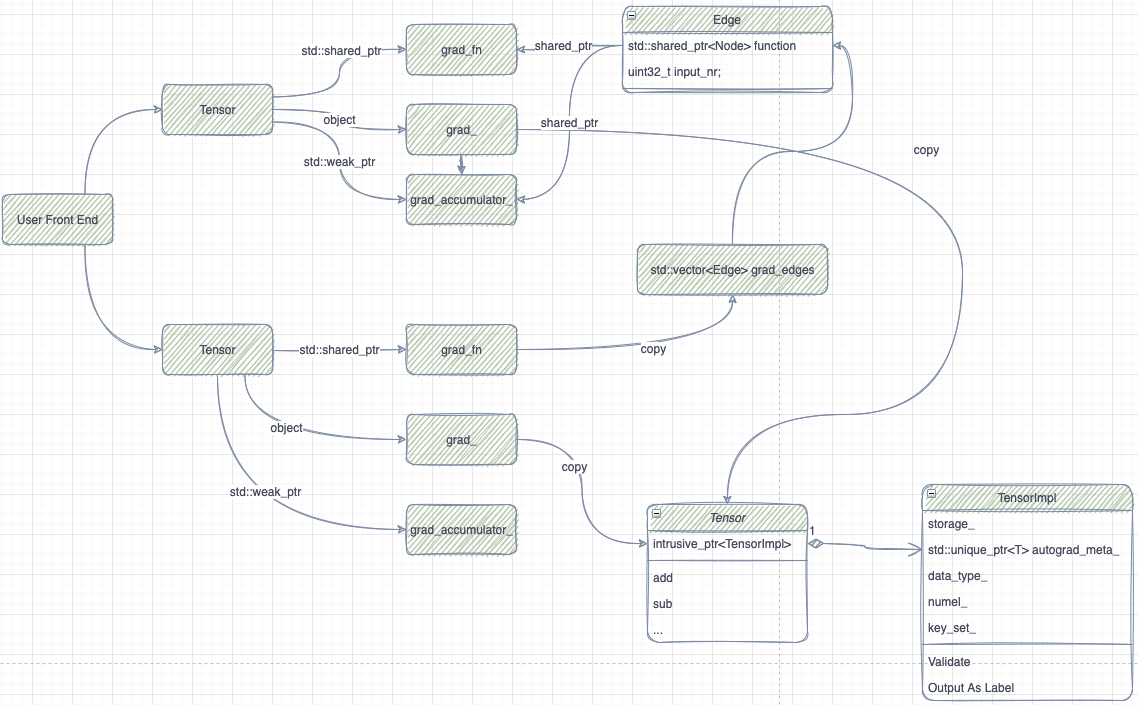
Autograd
// torch/csrc/autograd/variable.h
struct TORCH_API AutogradMeta : public c10::AutogradMetaInterface {
std::string name_;
Variable grad_;
std::shared_ptr<Node> grad_fn_;
std::weak_ptr<Node> grad_accumulator_;
std::shared_ptr<ForwardGrad> fw_grad_;
std::vector<std::shared_ptr<FunctionPreHook>> hooks_;
std::shared_ptr<hooks_list> cpp_hooks_list_;
}
AutogradMeta 中包含 autograd 所需的元素
- grad_: Tensor 对应的 grad
- grad_fn_: 反向 op
- grad_accumulator_: 反向梯度累加器,Node 类型
- cpp_hooks_list_, hooks_: 反向调用时的 hook
Node
Node
- The most important method on
Nodeis the call operator, which takes in a list of variables and produces a list of variables. - The precise size of these lists can be determined with
num_inputs()andnum_outputs(). Nodes are stitched together via theirnext_edgeinterface, which let you manipulate the set of outgoing edges of aNode.- You can add an edge with
add_next_edge(), retrieve an edge withnext_edge(index)and iterate over them via thenext_edges()method.
// torch/csrc/autograd/function.h
using edge_list = std::vector<Edge>;
struct TORCH_API Node : std::enable_shared_from_this<Node> {
public:
explicit Node(
uint64_t sequence_nr,
edge_list&& next_edges = edge_list())
: sequence_nr_(sequence_nr),
next_edges_(std::move(next_edges)) {
for (const Edge& edge: next_edges_) {
update_topological_nr(edge);
}
}
variable_list operator()(variable_list&& inputs) {
...
return apply(std::move(inputs));
}
void update_topological_nr(const Edge& edge) {
Node* node = edge.function.get();
if (node) {
auto topo_nr = node->topological_nr();
if (topological_nr_ <= topo_nr) {
topological_nr_ = topo_nr + 1;
}
}
}
void set_next_edge(size_t index, Edge edge) {
update_topological_nr(edge);
next_edges_[index] = std::move(edge);
}
void add_next_edge(Edge edge) {
update_topological_nr(edge);
next_edges_.push_back(std::move(edge));
}
void set_next_edges(edge_list&& next_edges) {
next_edges_ = std::move(next_edges);
for (const auto& next_edge : next_edges_) {
update_topological_nr(next_edge);
}
}
const Edge& next_edge(size_t index) const noexcept {
return next_edges_[index];
}
const edge_list& next_edges() const noexcept {
return next_edges_;
}
edge_list& next_edges() noexcept {
return next_edges_;
}
protected:
virtual variable_list apply(variable_list&& inputs) = 0;
const uint64_t sequence_nr_;
uint64_t topological_nr_ = 0;
uint64_t thread_id_ = 0;
edge_list next_edges_;
std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_;
std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_;
at::SmallVector<InputMetadata, 2> input_metadata_;
};
可以看到
- Node 的创建由 Edge 来完成,Node 中保存了连接情况和需要执行的方法。
- Node 本身是 callable object, 通过虚函数 apply 被子类重载实现。
- set_next_edge 方法可以添加 Edge
Edge
// torch/csrc/autograd/edge.h
struct Edge {
Edge() noexcept : function(nullptr), input_nr(0) {}
Edge(std::shared_ptr<Node> function_, uint32_t input_nr_) noexcept
: function(std::move(function_)), input_nr(input_nr_) {}
// Required for use in associative containers.
bool operator==(const Edge& other) const noexcept {
return this->function == other.function && this->input_nr == other.input_nr;
}
bool operator!=(const Edge& other) const noexcept {
return !(*this == other);
}
/// The function this `Edge` points to.
std::shared_ptr<Node> function;
/// The identifier of a particular input to the function.
uint32_t input_nr;
};
网络构建
先看简单的例子,
import torch
a = torch.tensor(1.0, requires_grad=True)
b = torch.tensor(2.0, requires_grad=True)
c = torch.add(a, b)
d = torch.mul(a, c)
d.backward()
print(f"a grad:{a.grad} grad_fn:{a.grad_fn}")
print(f"b grad:{b.grad} grad_fn:{b.grad_fn}")
print(f"c grad:{c.grad} grad_fn:{c.grad_fn}")
print(f"d grad:{d.grad} grad_fn:{d.grad_fn}")
'''
a grad:4.0 grad_fn:None
b grad:1.0 grad_fn:None
c grad:None grad_fn:<AddBackward0 object at 0x7f6862dc76d0>
d grad:None grad_fn:<MulBackward0 object at 0x7f6862dc76d0>
'''
以上代码构建的网络如图所示
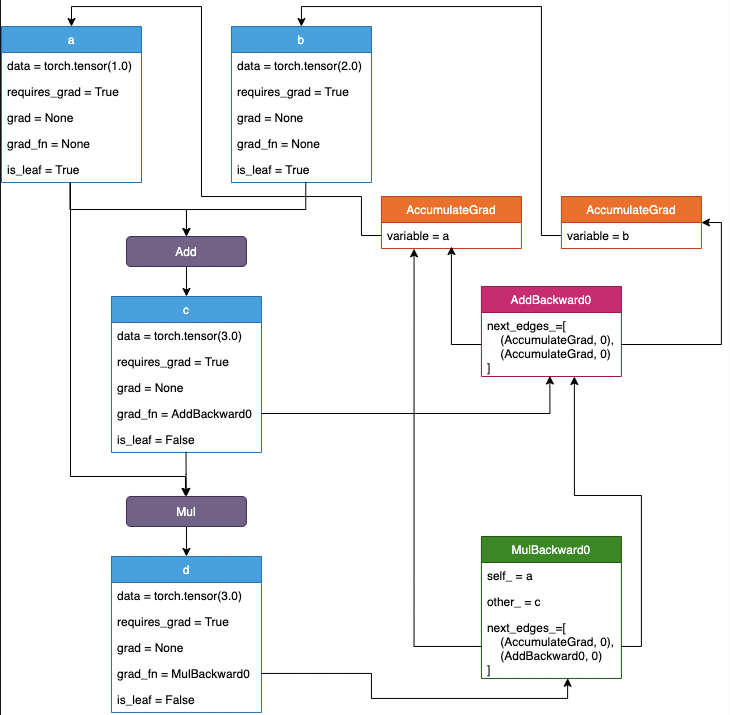
下面解析详细构建过程.
torch.add
torch/csrc/autograd/generated/ 目录需要 build 生成
// torch/csrc/autograd/generated/VariableType_2.cpp
// @generated by torchgen/gen.py from VariableType.cpp
at::Tensor add_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) {
auto& self_ = unpack(self, "self", 0);
auto& other_ = unpack(other, "other", 1);
auto _any_requires_grad = compute_requires_grad( self, other );
(void)_any_requires_grad;
auto _any_has_forward_grad_result = (isFwGradDefined(self) || isFwGradDefined(other));
(void)_any_has_forward_grad_result;
std::shared_ptr<AddBackward0> grad_fn;
if (_any_requires_grad) {
grad_fn = std::shared_ptr<AddBackward0>(new AddBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
grad_fn->other_scalar_type = other.scalar_type();
grad_fn->alpha = alpha;
grad_fn->self_scalar_type = self.scalar_type();
}
auto _tmp = ([&]() {
at::AutoDispatchBelowADInplaceOrView guard;
return at::redispatch::add(ks & c10::after_autograd_keyset, self_, other_, alpha);
})();
auto result = std::move(_tmp);
if (grad_fn) {
set_history(flatten_tensor_args( result ), grad_fn);
}
return result;
}
- 构建反向节点 AddBackward0
- 计算 at::redispatch::add,结果保存至 result
- 关联 AddBackward0 和 result
首先计算逻辑 add 的调用是自动生成的
// torch/include/ATen/RedispatchFunctions.h
// @generated by torchgen/gen.py from RedispatchFunctions.h
namespace at {
namespace redispatch {
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
inline at::Tensor add(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha=1) {
return at::_ops::add_Tensor::redispatch(dispatchKeySet, self, other, alpha);
}
}
}
具体实现 kernel 如下
// torch/include/ATen/ops/add_ops.h
// @generated by torchgen/gen.py from Operator.h
namespace at {
namespace _ops {
struct TORCH_API add_Tensor {
using schema = at::Tensor (const at::Tensor &, const at::Tensor &, const at::Scalar &);
using ptr_schema = schema*;
// See Note [static constexpr char* members for windows NVCC]
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(name, "aten::add")
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(overload_name, "Tensor")
STATIC_CONSTEXPR_STR_INL_EXCEPT_WIN_CUDA(schema_str, "add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor")
static at::Tensor call(const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha);
static at::Tensor redispatch(c10::DispatchKeySet dispatchKeySet, const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha);
};
C API 入口
// torch/include/ATen/core/TensorBody.h
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
inline at::Tensor Tensor::add(const at::Tensor & other, const at::Scalar & alpha) const {
return at::_ops::add_Tensor::call(const_cast<Tensor&>(*this), other, alpha);
}
// aten::add_.Tensor(Tensor(a!) self, Tensor other, *, Scalar alpha=1) -> Tensor(a!)
inline at::Tensor & Tensor::add_(const at::Tensor & other, const at::Scalar & alpha) const {
return at::_ops::add__Tensor::call(const_cast<Tensor&>(*this), other, alpha);
}
AddBackward0
// torch/csrc/autograd/generated/Functions.h
// @generated from ../tools/autograd/templates/Functions.h
struct TORCH_API AddBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "AddBackward0"; }
void release_variables() override { }
at::ScalarType other_scalar_type;
at::Scalar alpha;
at::ScalarType self_scalar_type;
};
TraceableFunction
// torch/csrc/autograd/function.h
struct TraceableFunction : public Node {
using Node::Node;
bool is_traceable() final {
return true;
}
};
collect_next_edges 根据两个输入找到节点的 Edges
// torch/csrc/autograd/function.h
/// Return the next edges of all the given variables, or tuples of variables.
template <typename... Variables>
edge_list collect_next_edges(Variables&&... variables) {
detail::MakeNextFunctionList make;
make.apply(std::forward<Variables>(variables)...);
return std::move(make.next_edges);
}
struct MakeNextFunctionList : IterArgs<MakeNextFunctionList> {
edge_list next_edges;
using IterArgs<MakeNextFunctionList>::operator();
void operator()(const Variable& variable) {
if (variable.defined()) {
next_edges.push_back(impl::gradient_edge(variable));
} else {
next_edges.emplace_back();
}
}
void operator()(const Variable* variable) { ... }
void operator()(const c10::optional<Variable>& variable) { ... }
};
gradient_edge 会返回一组 Edges
// torch/csrc/autograd/variable.cpp
Edge gradient_edge(const Variable& self) {
if (const auto& gradient = self.grad_fn()) {
return Edge(gradient, self.output_nr());
} else {
return Edge(grad_accumulator(self), 0);
}
}
如果 self 是内部创建的(非叶子结点),即通过运算生成的,则返回 self 的 grad_fn 数据成员,否则(即用户创建的叶子结点)返回 AccumulateGrad 实例。
// torch/csrc/autograd/variable.cpp
std::shared_ptr<Node> grad_accumulator(const Variable& self) {
auto autograd_meta = get_autograd_meta(self);
c10::raw::intrusive_ptr::incref(self.unsafeGetTensorImpl());
auto intrusive_from_this =
c10::intrusive_ptr<at::TensorImpl>::reclaim(self.unsafeGetTensorImpl());
result = std::make_shared<AccumulateGrad>(
Variable(std::move(intrusive_from_this)));
autograd_meta->grad_accumulator_ = result;
return result;
}
其中 AcculateGrad 中的 Variable 即 aten::Tensor 指向 self 的 TensorImpl 用于更新聚合梯度:
// torch/csrc/autograd/functions/accumulate_grad.h
struct TORCH_API AccumulateGrad : public Node {
explicit AccumulateGrad(Variable variable_);
variable_list apply(variable_list&& grads) override;
Variable variable;
};
set_history
// torch/csrc/autograd/functions/utils.h
inline void set_history(
at::Tensor& variable,
const std::shared_ptr<Node>& grad_fn) {
AT_ASSERT(grad_fn);
if (variable.defined()) {
auto output_nr = grad_fn->add_input_metadata(variable);
impl::set_gradient_edge(variable, {grad_fn, output_nr});
} else {
grad_fn->add_input_metadata(Node::undefined_input());
}
}
inline void set_history(
std::vector<Variable>&& variables,
const std::shared_ptr<Node>& grad_fn) {
for (auto& variable : variables) {
set_history(variable, grad_fn);
}
}
set_gradient_edge 设置 Tensor 和 grad_fn_.
// torch/csrc/autograd/variable.cpp
void set_gradient_edge(const Variable& self, Edge edge) {
auto* meta = materialize_autograd_meta(self);
meta->grad_fn_ = std::move(edge.function);
meta->output_nr_ = edge.input_nr;
auto diff_view_meta = get_view_autograd_meta(self);
if (diff_view_meta && diff_view_meta->has_bw_view()) {
diff_view_meta->set_attr_version(self._version());
}
}
// torch/csrc/autograd/generated/python_variable_methods.cpp
static PyObject * THPVariable_add(PyObject* self_, PyObject* args, PyObject* kwargs)
{
const Tensor& self = THPVariable_Unpack(self_);
static PythonArgParser parser({
"add(Scalar alpha, Tensor other)|deprecated",
"add(Tensor other, *, Scalar alpha=1)",
}, /*traceable=*/true);
ParsedArgs<2> parsed_args;
auto _r = parser.parse(self_, args, kwargs, parsed_args);
if(_r.has_torch_function()) {
return handle_torch_function(_r, self_, args, kwargs, THPVariableClass, "torch.Tensor");
}
switch (_r.idx) {
case 0: {
// [deprecated] aten::add(Tensor self, Scalar alpha, Tensor other) -> Tensor
auto dispatch_add = [](const at::Tensor & self, const at::Scalar & alpha, const at::Tensor & other) -> at::Tensor {
pybind11::gil_scoped_release no_gil;
return self.add(other, alpha);
};
return wrap(dispatch_add(self, _r.scalar(0), _r.tensor(1)));
}
case 1: {
// aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
auto dispatch_add = [](const at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) -> at::Tensor {
pybind11::gil_scoped_release no_gil;
return self.add(other, alpha);
};
return wrap(dispatch_add(self, _r.tensor(0), _r.scalar(1)));
}
}
}
// aten/src/ATen/core/dispatch/Dispatcher.h
// See [Note: Argument forwarding in the dispatcher] for why Args doesn't use &&
template<class Return, class... Args>
inline Return Dispatcher::redispatch(const TypedOperatorHandle<Return (Args...)>& op, DispatchKeySet currentDispatchKeySet, Args... args) const {
detail::unused_arg_(args...); // workaround for a false-positive warning about unused parameters in gcc 5
// do not use RecordFunction on redispatch
#ifndef NDEBUG
DispatchTraceNestingGuard debug_guard;
if (show_dispatch_trace()) {
auto nesting_value = dispatch_trace_nesting_value();
for (int64_t i = 0; i < nesting_value; ++i) std::cerr << " ";
std::cerr << "[redispatch] op=[" << op.operator_name() << "], key=[" << toString(currentDispatchKeySet.highestPriorityTypeId()) << "]" << std::endl;
}
#endif
const KernelFunction& kernel = op.operatorDef_->op.lookup(currentDispatchKeySet);
return kernel.template call<Return, Args...>(op, currentDispatchKeySet, std::forward<Args>(args)...);
}
// aten/src/ATen/native/BinaryOps.cpp
Tensor add(const Tensor& self, const Scalar& other, const Scalar& alpha) {
return at::add(self, wrapped_scalar_tensor(other), alpha);
}
Tensor& add_(Tensor& self, const Scalar& other, const Scalar& alpha) {
return self.add_(wrapped_scalar_tensor(other), alpha);
}
torch.mul
流程类似
// torch/csrc/autograd/generated/VariableType_0.cpp
at::Tensor mul_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other) {
auto& self_ = unpack(self, "self", 0);
auto& other_ = unpack(other, "other", 1);
auto _any_requires_grad = compute_requires_grad( self, other );
(void)_any_requires_grad;
auto _any_has_forward_grad_result = (isFwGradDefined(self) || isFwGradDefined(other));
(void)_any_has_forward_grad_result;
std::shared_ptr<MulBackward0> grad_fn;
if (_any_requires_grad) {
grad_fn = std::shared_ptr<MulBackward0>(new MulBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
if (grad_fn->should_compute_output(1)) {
grad_fn->self_ = SavedVariable(self, false);
}
grad_fn->other_scalar_type = other.scalar_type();
grad_fn->self_scalar_type = self.scalar_type();
if (grad_fn->should_compute_output(0)) {
grad_fn->other_ = SavedVariable(other, false);
}
}
auto _tmp = ([&]() {
at::AutoDispatchBelowADInplaceOrView guard;
return at::redispatch::mul(ks & c10::after_autograd_keyset, self_, other_);
})();
auto result = std::move(_tmp);
if (grad_fn) {
set_history(flatten_tensor_args( result ), grad_fn);
}
if (result_new_fw_grad_opt.has_value() && result_new_fw_grad_opt.value().defined() && result.defined()) {
// The hardcoded 0 here will need to be updated once we support multiple levels.
result._set_fw_grad(result_new_fw_grad_opt.value(), /* level */ 0, /* is_inplace_op */ false);
}
return result;
}
不同是的是因为乘法的求导和输入有关,所以我们在构建 MulBackward0 的时候需要把输入保存下来,即代码中的 SavedVariable 用于保存实例.
// torch/csrc/autograd/generated/Functions.h
struct TORCH_API MulBackward0 : public TraceableFunction {
using TraceableFunction::TraceableFunction;
variable_list apply(variable_list&& grads) override;
std::string name() const override { return "MulBackward0"; }
void release_variables() override {
std::lock_guard<std::mutex> lock(mutex_);
self_.reset_data();
other_.reset_data();
}
SavedVariable self_;
at::ScalarType other_scalar_type;
at::ScalarType self_scalar_type;
SavedVariable other_;
};
使用 SavedVariable 来保存前向 Var 的数据区而不影响其管理反向 Op 的生命周期:
// torch/csrc/autograd/saved_variable.h
class TORCH_API SavedVariable {
public:
/// Reconstructs the saved variable. Pass `saved_for` as the gradient
/// function if constructing the `SavedVariable` with it would have caused a
/// circular reference.
Variable unpack(std::shared_ptr<Node> saved_for = nullptr) const;
private:
at::Tensor data_;
std::shared_ptr<ForwardGrad> fw_grad_;
std::weak_ptr<Node> weak_grad_fn_;
c10::VariableVersion version_counter_;
uint32_t saved_version_ = 0;
uint32_t output_nr_ = 0;
bool was_default_constructed_ = true;
bool is_inplace_on_view_ = false;
bool saved_original_ = false;
bool is_leaf_ = false;
bool is_output_ = false;
std::unique_ptr<SavedVariableHooks> hooks_;
std::shared_ptr<Node> grad_fn_;
std::weak_ptr<Node> grad_accumulator_;
bool requires_grad_ = false;
};
Lifecycle