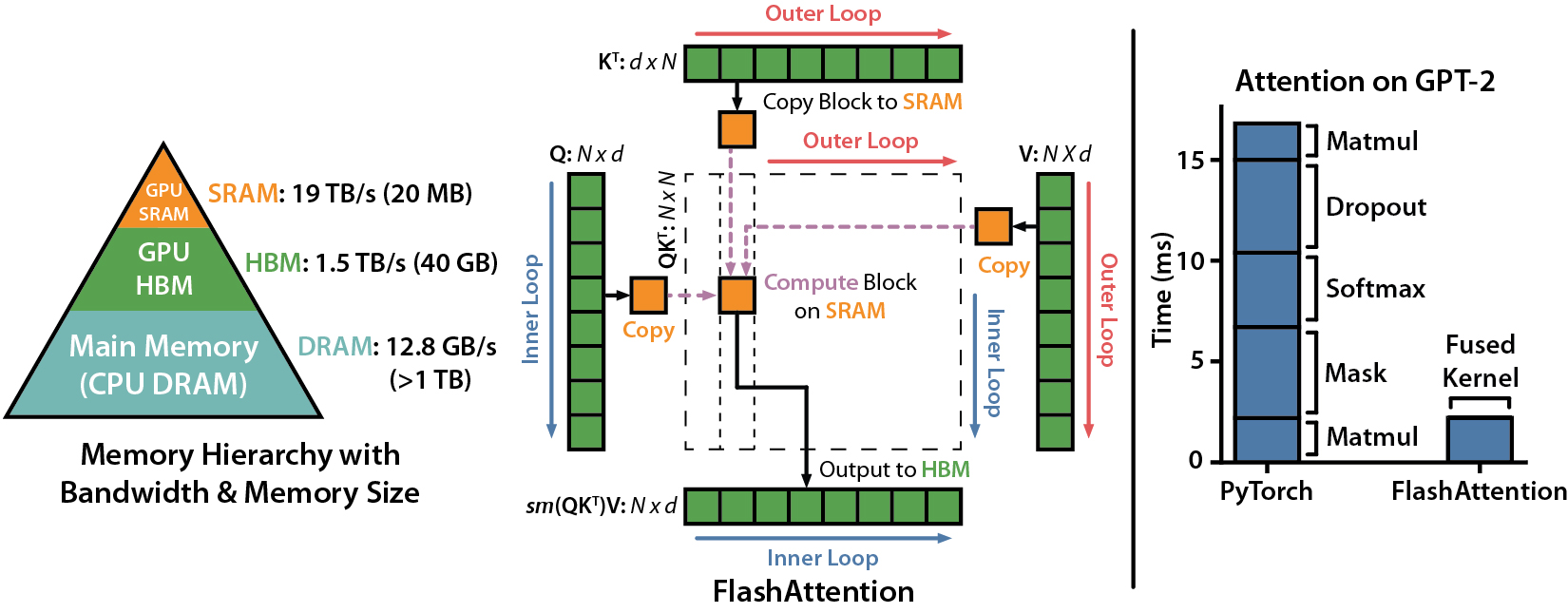
Flash Attention
Key Idea
- memory hierachy: GPU HBM (40G, 1.5TB/s) -> GPU SRAM (20MB, 19TB/s)
- tiling: split the input into blocks and make several passes over blocks, fit GPU SRAM
- recompute: recompute attention on-chip in the backward pass instead of retrieve from HBM
Conclusion: increase FLOPs, decrease Wall-clock time
Code Details
Modules
flash_attn
// csrc/flash_attn/fmha_api.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.doc() = "Fused Multi-head Self-attention";
m.def("fwd", &mha_fwd, "Forward pass");
m.def("bwd", &mha_bwd, "Backward pass");
m.def("fwd_block", &mha_fwd_block, "Forward pass (blocksparse)");
m.def("bwd_block", &mha_bwd_block, "Backward pass (blocksparse)");
}
fused_dense_lib
// csrc/fused_dense_lib/fused_dense.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("linear_bias_forward", &linear_bias_forward, "linear bias forward");
m.def("linear_bias_backward", &linear_bias_backward, "linear bias backward");
m.def("linear_bias_wgrad", &linear_bias_wgrad, "linear bias wgrad");
m.def("linear_bias_residual_backward", &linear_bias_residual_backward, "linear bias residual backward");
m.def("linear_gelu_forward", &linear_gelu_forward, "linear gelu forward");
m.def("linear_gelu_linear_backward", &linear_gelu_linear_backward, "linear gelu linear backward");
m.def("linear_residual_gelu_linear_backward", &linear_residual_gelu_linear_backward, "linear residual gelu linear backward");
}
fused_softmax
// csrc/fused_softmax/fused_softmax.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("scaled_masked_softmax_forward", &multihead_attn::fused_softmax::scaled_masked_softmax::fwd, "Self Multihead Attention scaled, time masked softmax -- Forward.");
m.def("scaled_masked_softmax_backward", &multihead_attn::fused_softmax::scaled_masked_softmax::bwd, "Self Multihead Attention scaled, time masked softmax -- Backward.");
m.def("scaled_masked_softmax_get_batch_per_block", &multihead_attn::fused_softmax::scaled_masked_softmax::get_batch_per_block, "Return Batch per block size.");
m.def("scaled_upper_triang_masked_softmax_forward", &multihead_attn::fused_softmax::scaled_upper_triang_masked_softmax::fwd, "Self Multihead Attention scaled, time masked softmax -- Forward.");
m.def("scaled_upper_triang_masked_softmax_backward", &multihead_attn::fused_softmax::scaled_upper_triang_masked_softmax::bwd, "Self Multihead Attention scaled, time masked softmax -- Backward.");
}
layer_norm
// csrc/fused_softmax/fused_softmax.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.doc() = "CUDA DropoutAddLayerNorm";
m.def("dropout_add_ln_fwd", &dropout_add_ln_fwd, "Run Dropout + Add + LayerNorm forward kernel");
m.def("dropout_add_ln_bwd", &dropout_add_ln_bwd, "Run Dropout + Add + LayerNorm backward kernel");
}
rotary
// csrc/rotary/rotary.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("apply_rotary", &apply_rotary, "Apply rotary embedding");
}
xentropy
// csrc/xentropy/interface.cpp
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &softmax_xentropy_forward, "Softmax cross entropy loss with label smoothing forward (CUDA)");
m.def("backward", &softmax_xentropy_backward, "Softmax cross entropy loss with label smoothing backward (CUDA)");
}
Flash Attention
Python API call chains overview
FlashSelfAttention
flash_attn_func
flash_attn_unpadded_qkvpacked_func
FlashAttnQKVPackedFunc
_flash_attn_forward = flash_attn_cuda.fwd
_flash_attn_backward = flash_attn_cuda.bwd
FlashCrossAttention
flash_attn_unpadded_kvpacked_func
FlashAttnKVPackedFunc
_flash_attn_forward
_flash_attn_backward
# ----
flash_attn_unpadded_qkvpacked_split_func
FlashAttnQKVPackedSplitFunc
_flash_attn_forward
_flash_attn_backward
FlashBlocksparseAttention
flash_blocksparse_attn_func
FlashBlocksparseAttnFun
_flash_blocksparse_attn_forward = flash_attn_cuda.fwd_block
_flash_blocksparse_attn_backward = flash_attn_cuda.bwd_block
FlashSelfAttention
# flash_attn/flash_attn_interface.py
def flash_attn_unpadded_qkvpacked_func(qkv, cu_seqlens, max_seqlen, dropout_p, softmax_scale=None, causal=False, return_attn_probs=False):
return FlashAttnQKVPackedFunc.apply(qkv, cu_seqlens, max_seqlen, dropout_p, softmax_scale, causal, return_attn_probs)
class FlashAttnQKVPackedFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, qkv, cu_seqlens, max_seqlen, dropout_p, softmax_scale, causal, return_softmax):
rng_state = torch.cuda.get_rng_state() if dropout_p > 0 else None
out, softmax_lse, S_dmask = _flash_attn_forward(...)
return (out, softmax_lse, S_dmask)
@staticmethod
def backward(ctx, dout, *args):
_flash_attn_backward(...)
return dqkv, None, None, None, None, None, None
def _flash_attn_forward(q, k, v, out, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
dropout_p, softmax_scale, causal, return_softmax, num_splits=0,
generator=None):
softmax_lse, *rest = flash_attn_cuda.fwd(...)
return out, softmax_lse, S_dmask
def _flash_attn_backward(dout, q, k, v, out, softmax_lse, dq, dk, dv, cu_seqlens_q, cu_seqlens_k,
max_seqlen_q, max_seqlen_k, dropout_p, softmax_scale, causal, num_splits=0,
generator=None):
_, _, _, softmax_d = flash_attn_cuda.bwd(...)
return dq, dk, dv, softmax_d
mha_fwd + mha_bwd
// csrc/flash_attn/fmha_api.cpp
std::vector<at::Tensor>
mha_fwd(const at::Tensor &q, // total_q x num_heads x head_size, total_q := \sum_{i=0}^{b} s_i
const at::Tensor &k, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &v, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
at::Tensor &out, // total_q x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &cu_seqlens_q, // b+1
const at::Tensor &cu_seqlens_k, // b+1
const int max_seqlen_q_,
const int max_seqlen_k_,
const float p_dropout,
const float softmax_scale,
const bool zero_tensors,
const bool is_causal,
const bool return_softmax,
const int num_splits,
c10::optional<at::Generator> gen_) {
Launch_params<FMHA_fprop_params> launch_params(dprops, stream, is_dropout, return_softmax);
run_fmha_fwd(launch_params);
return result;
}
void run_fmha_fwd(Launch_params<FMHA_fprop_params> &launch_params) {
if (launch_params.params.d <= 32) {
run_fmha_fwd_hdim32(launch_params);
} else if (launch_params.params.d <= 64) {
run_fmha_fwd_hdim64(launch_params);
} else if (launch_params.params.d <= 128) {
run_fmha_fwd_hdim128(launch_params);
}
}
std::vector<at::Tensor>
mha_bwd(const at::Tensor &dout, // total_q x num_heads, x head_size
const at::Tensor &q, // total_q x num_heads x head_size, total_q := \sum_{i=0}^{b} s_i
const at::Tensor &k, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &v, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &out, // total_q x num_heads x head_size
const at::Tensor &softmax_lse_, // b x h x s softmax logsumexp
at::Tensor &dq, // total_q x num_heads x head_size, total_q := \sum_{i=0}^{b} s_i
at::Tensor &dk, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
at::Tensor &dv, // total_k x num_heads x head_size, total_k := \sum_{i=0}^{b} s_i
const at::Tensor &cu_seqlens_q, // b+1
const at::Tensor &cu_seqlens_k, // b+1
const int max_seqlen_q_,
const int max_seqlen_k_, // max sequence length to choose the kernel
const float p_dropout, // probability to drop
const float softmax_scale,
const bool zero_tensors,
const bool is_causal,
const int num_splits,
c10::optional<at::Generator> gen_
) {
auto launch = &run_fmha_bwd;
FMHA_dgrad_params params;
set_params_dgrad(params, ... num_splits);
launch(params, stream, /*configure=*/true);
launch(params, stream, /*configure=*/false);
return { dq, dk, dv, softmax_d };
}
void run_fmha_bwd(FMHA_dgrad_params ¶ms, cudaStream_t stream, const bool configure) {
if (params.d <= 32) {
run_fmha_bwd_hdim32(params, stream, configure);
} else if (params.d <= 64) {
run_fmha_bwd_hdim64(params, stream, configure);
} else if (params.d <= 128) {
run_fmha_bwd_hdim128(params, stream, configure);
}
}
// csrc/flash_attn/src/fmha_fwd_hdim32.cu
#include "fmha_fwd_launch_template.h"
void run_fmha_fwd_hdim32(Launch_params<FMHA_fprop_params> &launch_params) {
FP16_SWITCH(launch_params.params.is_bf16, ({
if (launch_params.params.seqlen_k == 128) {
using Kernel_traits = FMHA_kernel_traits<128, 32, 16, 1, 4, 0x08u, elem_type>;
run_fmha_fwd_loop<Kernel_traits>(launch_params);
} else if (launch_params.params.seqlen_k >= 256) {
using Kernel_traits = FMHA_kernel_traits<256, 32, 16, 1, 4, 0x08u, elem_type>;
run_fmha_fwd_loop<Kernel_traits>(launch_params);
}
}));
}
run_fmha_fwd_loop -> fmha_fwd_loop_kernel
// csrc/flash_attn/src/fmha_fwd_launch_template.h
template<typename Kernel_traits>
void run_fmha_fwd_loop(Launch_params<FMHA_fprop_params> &launch_params) {
BOOL_SWITCH(launch_params.is_dropout, IsDropoutConst, ({
auto kernel = launch_params.params.is_causal
? (launch_params.return_softmax
? &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, true, true>
: &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, true, false>)
: (launch_params.return_softmax
? &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, false, true>
: &fmha_fwd_loop_kernel<Kernel_traits, IsDropoutConst, false, false>);
if( smem_size >= 48 * 1024 ) {
FMHA_CHECK_CUDA(cudaFuncSetAttribute(
kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));
}
kernel<<<grid, Kernel_traits::THREADS, smem_size, launch_params.stream>>>(
launch_params.params);
}));
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Return_softmax>
__global__ void fmha_fwd_loop_kernel(FMHA_fprop_params params) {
fmha::device_1xN_loop<Kernel_traits, Is_dropout, Is_causal, Return_softmax>(params);
}
device_1xN_loop
// csrc/flash_attn/src/fmha_fprop_kernel_1xN.h
#include "fmha_kernel.h"
#include <fmha/kernel_traits.h>
#include <fmha/gemm.h>
#include <fmha/utils.h>
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Return_softmax, typename Params>
inline __device__ void device_1xN_loop(const Params ¶ms) {
// The block index for the batch.
const int bidb = blockIdx.x;
// The block index for the head.
const int bidh = blockIdx.y;
// The thread index.
const int tidx = threadIdx.x;
fmha::device_1xN_<Kernel_traits, Is_dropout, Is_causal, Return_softmax, true, true>(params, bidb, bidh, STEPS, ph, 0);
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Return_softmax, bool Is_first, bool Is_last, typename Params, typename Prng>
inline __device__ void device_1xN_(const Params ¶ms, const int bidb, const int bidh, int steps, Prng &ph, const int loop_step_idx) {
...
}
Dependencies
csrc/flash_attn/src/fmha
|-- gemm.h
|-- gmem_tile.h
|-- kernel_traits.h
|-- mask.h
|-- smem_tile.h
|-- softmax.h
`-- utils.h
Long sequences
WHY 原 flashattention 算法的并行依赖 bs * num_heads,A100 有 108 SMs,当 bs * num_heads > 80 时并行度利用率较高,但在长序列场景下,bs * num_heads 通常较小,无法充分利用 GPU 并行度。
HOW 前向:使用多个 thread blocks 并行处理同一个 attention head,head 按照 row 切分,可以无依赖并行 反向:多个 thread blocks 并行处理,head 按照 column 切分,thread 间需要聚合 query gradient。(如果按 row 切则需要聚合 key 和 value 的 gradient)